Kubernetes Basics
Introduction to Kubernetes
To learn Kubernetes, it is essential to first understand its technical scope, foundational theories, and other related knowledge. Learning Kubernetes definitely requires an introductory process, which should start from the basics and progress to more complex concepts.
So what are the foundational elements to understand before diving into Kubernetes?
According to the certification exams by the Linux Foundation, the following learning objectives must be achieved to understand Kubernetes:
- Discuss Kubernetes.
- Learn the basic Kubernetes terminology.
- Discuss the configuration tools.
- Learn what community resources are available.
Next, I will introduce some concepts (Discussion), technical terminologies (Terminology), relevant configuration tools, and community open source resources.
This series of tutorials will mix some English terms, as a significant amount of English terminology is encountered during the study and use of Kubernetes. Furthermore, the international certification exams for Kubernetes are conducted in English, so it's beneficial to gradually familiarize yourself with some English vocabulary.
This tutorial series primarily references the course content and Kubernetes documentation from the Linux Foundation, with course materials shared under the Attribution 3.0 Unported (CC BY 3.0) license. The CC BY 3.0 license allows:
- Sharing—to copy and redistribute the material in any medium or format
- Adapting—to remix, transform, and build upon the material
- For any purpose, even commercially.
The URL for the Linux Foundation's certification exams and course learning:
https://training.linuxfoundation.org/#
Terms of Use:
https://www.linuxfoundation.org/terms/
After learning Kubernetes, you can further pursue the following certification credentials:
Kubernetes Administrator Certification (CKA), Kubernetes Application Developer Certification (CKAD), Kubernetes Security Specialist Certification (CKS).
What Is Kubernetes?
Let's first consider that running a Docker container can be done easily using the docker run ... command, which is quite straightforward (relatively simple).
However, achieving the following scenarios can be difficult:
- Connecting containers across multiple hosts
- Scaling containers
- Deploying applications without downtime
- Service discovery among several aspects
In 2008, LXC (Linux Containers) released its first version, which was the original version of containers; in 2013, Docker launched its first version; and in 2014, Google introduced LMCTFY.
To address various issues in deploying, scaling, and managing containers within large clusters, software such as Kubernetes, Docker Swarm emerged, referred to as container orchestration engines.
What is Kubernetes?
"An open-source system for automating deployment, scaling, and management of containerized applications."
“一个自动化部署、可拓展和管理容器应用的开源系统”
Google's infrastructure had already scaled significantly before the wide adoption of virtual machine (VM) technology. Efficiently utilizing clusters and managing distributed applications became the core challenges for Google. Container technology provides an efficient way to package and manage clusters.
For years, Google has used Borg to manage containers within clusters, accumulating a wealth of experience in cluster management and operational software development. Drawing from Borg, Google developed Kubernetes, which is essentially an evolution of Borg (however, Google primarily still uses Borg).
Kubernetes has, from the start, addressed these challenges through a set of primitives and a powerful and extensible API, adding new objects and controllers that easily meet various production needs.
As the word Kubernetes is difficult to pronounce, with 8 letters between "k" and "s," it is commonly referred to as "k8s." And the original name for K3S, designed for small embedded devices? I don't know 🤪🤪🤪
Kubernetes is written in Go.
Of course, besides Kubernetes, there are other orchestration software like Docker Swarm, Apache Mesos, Nomad, Rancher, etc., that can monitor container states, enable dynamic scaling, and more.
Components of Kubernetes
The components of Kubernetes can be divided into two categories: Control Plane Components and Node Components.
Control Plane Components are responsible for making global decisions for the cluster;
Node Components run on nodes, providing a Kubernetes environment for Pods.
Docker and Kubernetes cannot be used whimsically; it may require changes in development models and system administration approaches. In traditional environments, a single application is deployed on a dedicated server. When business grows, larger bandwidth, CPU, and memory are needed, making extensive customizations to improve performance, cache optimization, etc., while also requiring larger hardware.
In contrast, solutions that utilize Kubernetes adopt multiple smaller servers or microservices instead of one large single server model.
For example, to ensure service reliability, if one host's service process fails, another server will take over the service. If a single server has extremely high configuration, the costs will also be high, resulting in a more expensive solution. When using Kubernetes, if one server or process fails, another can be started that might only require less than 1GB of memory. Furthermore, microservices allow for application module decoupling.
PS: Most of the web servers in use today are likely Nginx, which supports load balancing, reverse proxy, and multi-server configurations, making it ideal for microservices and multi-host deployments. In contrast, Apache uses many httpd daemons to respond to page requests.
By splitting a single application into multiple microservices and converting a high-configuration server into multiple smaller servers (agents), Kubernetes can then be used to manage clusters. To manage multiple servers and service instances, Kubernetes provides a variety of components.
In Kubernetes, the applications deployed on each small server are referred to as microservices (logically) or agents (equivalent to a server). The lifecycle of the applications is transient, as they may be replaced upon any exceptions. To utilize multiple microservices within a cluster, services and API calls are necessary. If one service needs to connect to another, agents must communicate with each other. For example, a web service needs to connect to a database. Both Kubernetes and Consul have service discovery and network proxy capabilities. Kubernetes offers kube-proxy, while Consul has Consul Connect; readers can refer to separate documentation for further information.
Readers can click the link below to learn more about Components of Kubernetes:
https://www.vmware.com/topics/glossary/content/components-kubernetes
Kubernetes Architecture
Using a diagram to represent the architecture is the fastest way to demystify Kubernetes. Below is a graphic referred to as Kubernetes Architecture.
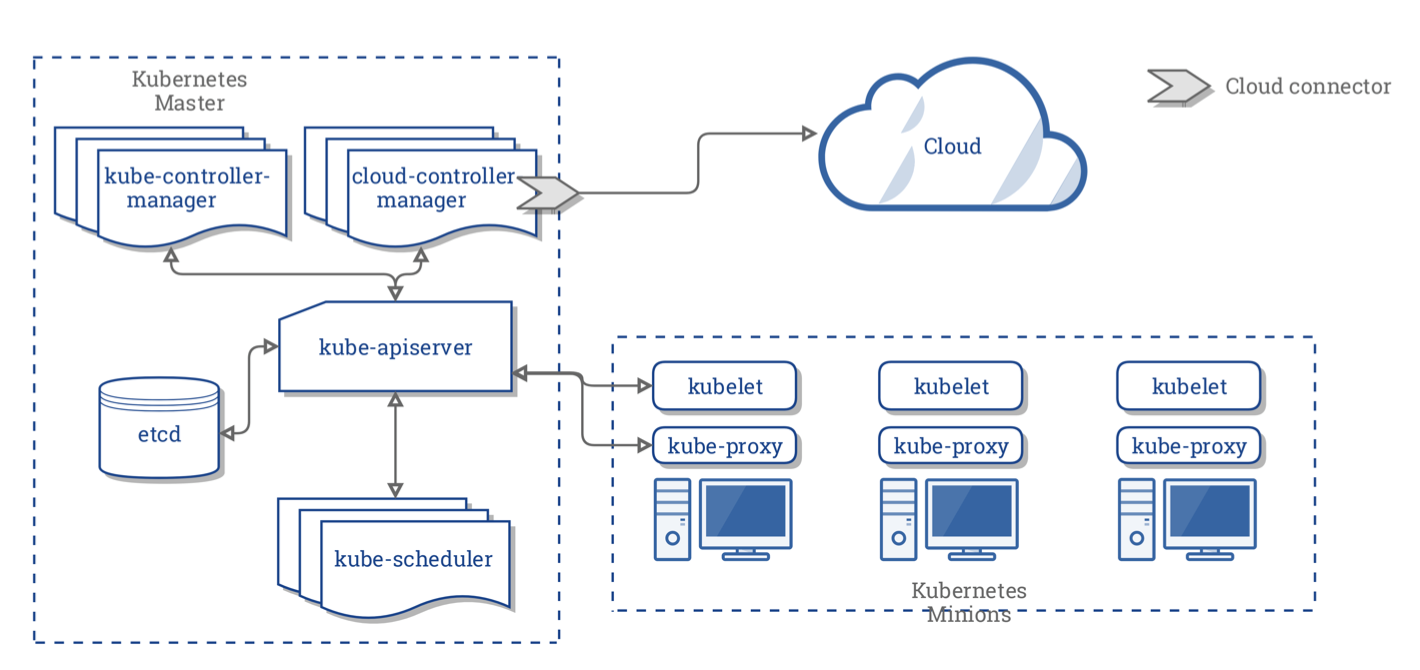
The above diagram illustrates a simple Kubernetes structure. The dashed box on the left is called the central manager (also known as master), indicating the central management; the right side shows three worker nodes (worker nodes), which are referred to as minions. These two parts correspond to Master-Minions.
In the diagram, the Master consists of several components:
- An API server (kube-apiserver)
- A scheduler (kube-scheduler)
- Various controllers (there are two controllers in the diagram)
- A storage system (this component is called etcd) that stores the cluster state, container settings, network configurations, etc.
Next, we will explore terms and keywords related to Kubernetes based on this image.
Docker cgroup and Namespace
We know that operating systems schedule resources based on individual processes. Modern operating systems set resource boundaries for processes, ensuring that each process uses its own memory area, preventing memory overlap. The Linux kernel features cgroups and namespaces to define boundaries for processes, isolating them from one another.
Namespace
In a container, when we use the top command or ps command to view the processes on the machine, we can see each process's PID. All processes in the machine's containers have a base PID = 1. But why are there no conflicts? Processes in containers can use all ports freely, and different containers can use the same port without conflicts—this is a representation of how namespaces set boundaries.
In Linux, unshare can create a namespace (which is essentially a process, where other processes within the namespace are its child processes) and create some resources (child processes). To deeply understand the namespace in Docker, we can execute the following in Linux:
sudo unshare --fork --pid --mount-proc bashThen we can execute ps aux to check the processes:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 23612 3556 pts/1 S 21:14 0:00 bash
root 13 0.0 0.1 37624 3056 pts/1 R+ 21:14 0:00 ps auxDoes this not resemble the results of a command executed inside a Docker container? We can also use the nsenter command to enter another process's namespace.
In the code above, the --pid parameter creates the PID namespace, but since the network was not isolated, executing the netstat --tlap command will show that this namespace's network is not isolated from other namespaces.
The types of namespaces in Linux include:
- mount: a namespace with an independent mount file system;
- ipc: Inter-Process Communication namespace, with independent semaphores, shared memory, etc.;
- uts: namespaces with independent hostname and domain name;
- net: independent networks, such as each Docker container having a virtual network card;
- pid: independent process spaces, where process PIDs all start from 1;
- user: a namespace with an independent user system, where the root in Docker is different from the host's user;
- cgroup: independent user groups;
The namespace in Docker relies on the Linux kernel's implementation.
Cgroups
Cgroups can limit the memory and CPU resources that a process can use. Cgroups, short for Control Groups, is a mechanism for isolating physical resources in the Linux kernel.
To avoid excessive length, readers only need to understand that Docker limits container resource usage and CPU cores based on cgroups in the Linux kernel; further explanation is not necessary here.
kube-apiserver
Kubernetes exposes a set of APIs through kube-apiserver, which we can use to control the behavior of Kubernetes. Kubernetes includes a local client that calls these APIs, named kubectl. Of course, we can also develop powerful tools similar to kubectl using these APIs, such as the service mesh management tool Istio.
kube-scheduler
When a container is to be run, the request sent will be forwarded to the API by the scheduler (kube-scheduler). The scheduler can also find a suitable node to run the container.
Node
Each node in the cluster runs two processes, kubelet and kube-proxy (as seen in the Kubernetes Minions in the diagram).
Earlier, we learned that when a container is to be run, the request sent to the scheduler will eventually reach the kubelet on the node, which can accept requests to "run containers." The kubelet also manages the necessary resources and monitors them on the local node.
Kube-proxy creates and manages network rules to expose containers on the network.
Kubernetes Master can only run on Linux, while nodes can run on Linux and Windows.
Terminology
This section introduces some Kubernetes terminology to familiarize readers with concepts within Kubernetes. The content in this section will not provide extensive explanations, as each part would require complex discussions; these concepts will be explained in detail in subsequent Kubernetes topics. Therefore, this is just an overview of some concise concepts. Readers need not scrutinize it, just have a glance.
Orchestration is managed
Orchestration management is controlled or operated through a series of watch-loops; each controller interrogates the kube-apiserver for object status and then modifies it until the desired conditions are met.
Container orchestration is the primary technology for managing containers. Docker also has its officially developed orchestration tool, Swarm; however, in the container orchestration battle of 2017, Swarm was outperformed by Kubernetes.
Namespace
Kubernetes documentation states that for clusters with only a few to dozens of users, there is no need to create or consider namespaces. Here, we only need to know that cluster resources are delineated by namespaces, allowing for isolation between resources. This name is referred to as a namespace. However, this namespace is different from the Linux kernel's namespace technology mentioned earlier; readers only need to perceive that both concepts are conceptually similar.
Pod
Pod is the smallest deployable computing unit created and managed within Kubernetes.
In previous studies, we learned that Kubernetes is an orchestration system for deploying and managing containers. Containers run on a Pod, where a Pod can host multiple containers, and these containers share the same IP address, access to the storage system, and namespace. Kubernetes utilizes namespaces to isolate objects within the cluster, facilitating resource control and multi-tenant connectivity.
Replication Controller
Replication Controller, abbreviated as RC, is a controller used to deploy and upgrade Pods.
ReplicaSet
ReplicaSet aims to maintain a stable set of Pod replicas that are up and running at all times.
If a Pod crashes, we can manually restart the Pod, but this method is unreliable as it is impossible for a person to execute a series of commands 24/7 instantly.
Deployments
Deployment provides a way to manage Pods and ReplicaSets. This will not be elaborated on in detail, but will be mentioned as needed in the future.
Kubernetes Objects
Kubernetes objects are persistent entities through which the entire cluster's state can be defined. Here are some representations of object information:
- Object name and IDs: represented by name and UID to ensure uniqueness among similar resources;
- Namespace: the namespace mentioned earlier;
- Labels and selectors: Labels are key-value pairs attached to Kubernetes objects (such as Pods);
- Annotations: non-identifying metadata attached to objects;
- Field selectors: filters Kubernetes resources based on the values of one or more resource fields;

文章评论