原作者:Joydip Kanjilal
原文地址:https://www.codemag.com/Article/2207031/Writing-High-Performance-Code-Using-SpanT-and-MemoryT-in-C
本文采用半译方式。
在本文中,将会介绍 C# 7.2 中引入的新类型:Span 和 Memory,文章深入研究 Span<T> 和 Memory<T> ,并演示如何在 C# 中使用它们。
本文所有代码用例在 .NET 6.0 下运行。
.NET 中支持的内存类型
.NET 中,开发者能够使用的三种内存类型,分别是:
- Stack memory 堆栈内存: 驻留在堆栈中,并使用
stackalloc关键词分配; - Managed memory 托管内存: 驻留在堆中并由 GC 管理;
- Unmanaged memory 非托管内存: 驻留在非托管堆中,并通过调用
Marshal.AllocHGlobal或者Marshal.AllocCoTaskMem方法分配;
.NET Core 2.1 中新增的类型
.NET Core 2.1 中新引入的类型包括:
-
System.Span: 这以类型安全和内存安全的方式表示任意内存的连续部分;
-
System.ReadOnlySpan: 这表示任意连续内存区域的类型安全和内存安全只读表示形式;
-
System.Memory: 这表示一个连续的内存区域;
-
System.ReadOnlyMemory: 类似
ReadOnlySpan, 此类型表示内存的连续部分ReadOnlySpan, 它不是 ByRef 类型;译者注:
ByRef类型指的是ref readonly struct。
访问连续内存: Span 和 Memory
开发者可能经常需要在应用程序中处理大量数据,例如字符串处理在任何应用程序中都是至关重要的,因此开发者必须遵循推荐的实践以避免不必要的分配。开发者可以使用不安全的代码块和指针直接操作内存,但是这种方法有相当大的风险,指针操作容易出现错误,如溢出、空指针访问、缓冲区溢出和悬空指针。如果 bug 只影响堆栈或静态内存区域,那么它将是无害的,但是如果它影响关键的系统内存区域,则可能导致应用程序崩溃。
因此,出现了 Span<T> 和 Memory<T> ,能够以安全的方式使用指针访问内存。
Span<T> 和 Memory<T> 是 .NET 新引入的类型(都是 struct),它们提供了一种类型安全的方法来访问任意内存的连续区域。Span<T> 和 Memory<T> 都是 System 命名空间的一部分,表示连续的内存块,没有 任何复制语义。
C# 新版本添加了 Span<T> 、 Memory<T> 、 ReadOnlySpan 和 ReadOnlyMemory 类型,它们可以帮助开发者在安全和性能方面直接使用内存。
这些新类型在 System.Memory 命名空间中,适用于需要处理大量数据或希望避免不必要的内存分配(例如在使用缓冲区时)的高性能场景。与在 GC 堆上分配内存的数组类型不同,这些新类型提供了对任意托管或本机内存的连续区域的抽象,而不需要在 GC 堆上分配内存。
译者注:因为它们都是 struct,会被分配到栈中。
Span<T> 和 Memory<T> 结构体为数组、字符串或任何连续的托管或非托管内存块提供低级接口,它们的主要功能是促进微优化和编写低分配代码,以减少托管内存分配,从而减少垃圾收集器的负担。它们还允许切片或处理数组、字符串或内存块的某个部分,而无需复制原始内存块。Span<T> 和 Memory<T> 在高性能领域非常有用,例如 ASP.NET Core 6 request-processing 管道。
Span 介绍
Span<T>(早期称为 Slice)出现在 C# 7.2/NET Core 2.1,创建它的开销几乎为零,它提供了一种使用连续内存块的类型安全方法,例如:
- Arrays and subarrays 数组和子数组
- Strings and substrings 字符串和子字符串
- Unmanaged memory buffers 非托管内存缓冲区
Span 类型表示驻留在托管堆、堆栈甚至非托管内存中的连续内存块,如果创建一个基元类型的数组(使用 stackalloc 创建),它将在堆栈上分配,并且不需要垃圾回收来管理其生存期。Span<T> 能够指向分配给堆栈或堆上的内存块。但是,因为 Span<T> 被定义为 ref 结构,所以它应该只驻留在堆栈上。
以下是一目了然的 Span<T> 的特征:
- Value type 值类型
- Low or zero overhead 低或零开销
- High performance 高性能
- Provides memory and type safety 提供内存和类型安全
开发者可以将 Span 与下列任一项一起使用
- Arrays
- Strings
- Native buffers 本地缓冲区
可以转换为 Span<T> 的类型列表如下:
- Arrays
- Pointers 指针
- IntPtr 指针
- stackalloc
开发者可以将以下所有内容转换为 ReadOnlySpan<T> :
- Arrays
- Pointers 指针
- IntPtr 指针
- stackalloc
- string
Span<T> 是一个仅堆栈类型,准确地说它是一个 ByRef 类型。因此,既不能将 span 装箱,也不能显示为仅限堆栈类型的字段,也不能在泛型参数中使用它们。但是,可以使用 span 来表示返回值或方法参数。请参考下面给出的代码片段,它说明了 Span 结构的完整源代码:
public readonly ref struct Span<T>
{
internal readonly ByReference<T> _pointer;
private readonly int _length;
//Other members
}
因为 Span 定义时,是 public readonly ref struct Span<T>,表示只能在堆栈中分配。
开发者可以在这里查看 struct Span<T> 的完整源代码: https://github.com/dotnet/corefx/blob/master/src/common/src/corelib/system/Span.cs。
Span<T> 源代码显示它基本上包含两个只读字段: 一个本机指针和一个长度属性,表示 Span 包含的元素数。
Span 的使用方式与数组相同,但是与数组不同,它可以引用堆栈内存,即堆栈上分配的内存、托管内存和本机内存。这为开发者提供了一种简单的方法来利用以前只有在处理非托管代码时才能获得的性能改进。
若要创建空的 Span,可以使用 Span.Empty 属性:
Span<char> span = Span<char>.Empty;
下面的代码片段演示如何在托管内存中创建 Byte 数组,然后从中创建 span 实例。
var array = new byte[100];
var span = new Span<byte>(array);
C# 中的 Span
下面是如何在堆栈中分配一块内存并使用 Span 指向它:
Span<byte> span = stackalloc byte[100];
下面的代码片段显示了如何使用字节数组创建 Span、如何将整数存储在字节数组中以及如何计算存储的所有整数的总和。
var array = new byte[100];
var span = new Span<byte>(array);
byte data = 0;
for (int index = 0; index < span.Length; index++)
span[index] = data++;
int sum = 0;
foreach (int value in array)
sum += value;
下面的代码片段从本机内存(非托管内存)创建一个 Span:
var nativeMemory = Marshal.AllocHGlobal(100);
Span<byte> span;
unsafe
{
span = new Span<byte>(nativeMemory.ToPointer(), 100);
}
现在可以使用下面的代码片段在 Span 指向的内存中存储整数,并显示存储的所有整数的总和:
byte data = 0;
for (int index = 0; index < span.Length; index++)
span[index] = data++;
int sum = 0;
foreach (int value in span)
sum += value;
Console.WriteLine ($"The sum of the numbers in the array is {sum}");
Marshal.FreeHGlobal(nativeMemory);
还可以使用 stackalloc 关键字在堆栈内存中分配 Span,如下所示:
byte data = 0;
Span<byte> span = stackalloc byte[100];
for (int index = 0; index < span.Length; index++)
span[index] = data++;
int sum = 0;
foreach (int value in span)
sum += value;
Console.WriteLine ($"The sum of the numbers in the array is {sum}");
需要开启不安全代码设置。
Span 和 Arrays
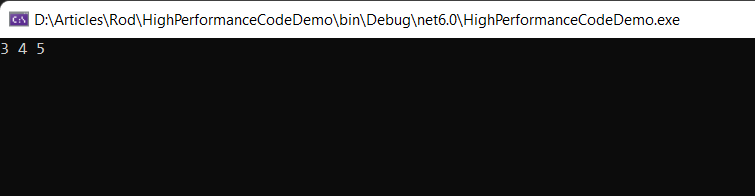
切片允许将数据视为逻辑块,然后可以以最小的资源开销处理这些逻辑块。Span<T> 可以包装整个数组,因为它支持切片,所以可以让它指向数组中的任何连续区域。下面的代码片段显示了如何使用 Span<T> 指向数组中由三个元素组成的片段。
int[] array = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
Span<int> slice = new Span<int>(array, 2, 3);
作为 Span<T> struct 的一部分,Slice 方法有两个重载,允许基于索引创建,这允许将 Span<T> 数据作为一系列逻辑块来处理,这些逻辑块可以单独处理,也可以按照数据处理流水线的各个部分的要求来处理。
开发者可以使用 Span<T> 来包装整个数组。因为它支持切片,所以它不仅可以指向数组的第一个元素,还可以指向数组中任何连续的元素范围。
foreach (int i in slice)
Console.WriteLine($"{i} ");
执行前面的代码片段时,分片数组中的整数将显示在控制台上,如图2所示。
Span 和 ReadOnlySpan
ReadOnlySpan<T> 实例通常用于引用数组项或数组的块。与数组不同,ReadOnlySpan<T> 实例可以引用本机内存、托管内存或堆栈内存。Span<T> 和 ReadOnlySpan<T> 都提供了连续内存区域的类型安全表示, Span<T> 提供对内存区域的读写访问, ReadOnlySpan<T> 提供对内存段的只读访问。
下面的代码片段说明了如何使用 ReadOnlySpan 在 C# 中切割字符串的一部分:
ReadOnlySpan<char> readOnlySpan = "This is a sample data for testing purposes.";
int index = readOnlySpan.IndexOf(' ');
var data = ((index < 0) ?
readOnlySpan : readOnlySpan.Slice(0, index)).ToArray();
Memory 入门
Memory<T> 是一个引用类型,它表示内存的一个连续区域,具有一个长度,但不一定从索引0开始,可以是另一个 Memory 中的许多区域之一。由 Memory 表示的内存甚至可能不是开发者自己的进程,因为它可能已经在非托管代码中分配。内存对于表示非连续缓冲区中的数据非常有用,因为它允许开发者像对待单个连续缓冲区一样对待它们,而不需要进行复制。
以下是 Memory
public struct Memory<T>
{
void* _ptr;
T[] _array;
int _offset;
int _length;
public Span<T> Span => _ptr == null ? new Span<T>(_array, _offset, _length) : new Span<T>(_ptr, _length);
}
除了包含 Span<T> 功能外,Memory<T> 还提供了一个安全的、可切片的视图,可以进入任何连续的缓冲区,无论是数组还是字符串。与 Span<T> 不同,它没有仅限于堆栈的约束,因为它不是类似于 ref 的类型。因此,开发者可以将它放在堆上,在集合中或异步等待中使用它,将它保存为字段或装箱,就像对待任何其他 C# 结构一样。
当需要修改或处理 Memory<T> 引用的缓冲区时,Span<T> 属性允许开发者获得高效的索引功能。相反,Memory<T> 是一种比 SpanReadOnlyMemory<T> 的不可变的只读对应物。
尽管 Span<T> 和 Memory<T> 都代表一个连续的内存块,但与 Span<T> 不同,Memory<T> 不是一个 ref 结构。因此,与 Span<T> 相反,开发者可以在托管堆上的任何位置使用 Memory<T> 。因此,在 Memory<T> 中没有与 Span<T> 中相同的限制,开发者可以使用 Memory<T> 作为类字段,并且可以跨 await 和 yield 边界(下面会说到)。
ReadOnlyMemory
与 ReadOnlySpan<T> 类似,ReadOnlyMemory<T> 表示对连续内存区域的只读访问,但与 ReadOnlySpan<T> 不同,它不是 ByRef 类型。
现在请参考下面的字符串,其中包含由空格字符分隔的国家名称。
string countries = "India Belgium Australia USA UK Netherlands";
var countries = ExtractStrings("India Belgium Australia USA UK Netherlands".AsMemory());
通过提取字符串的方法提取每个国家的名称,如下所示:
public static IEnumerable<ReadOnlyMemory<char>> ExtractStrings(ReadOnlyMemory<char> c)
{
int index = 0, length = c.Length;
for (int i = 0; i < length; i++)
{
if (char.IsWhiteSpace(c.Span[i]) || i == length)
{
yield return c[index..i];
index = i + 1;
}
}
}
开发者可以调用上述方法,并使用以下代码片段在控制台窗口中显示国家名称:
var data = ExtractStrings(countries.AsMemory());
foreach(var str in data)
Console.WriteLine(str);
Span 和 Memory 的优势
使用 Span 和 Memory 类型的主要优点是提高了性能。开发者可以通过使用 stackalloc 关键字来分配堆栈上的内存,该关键字分配一个未初始化的块,该块是 T[size] 类型的实例。如果开发者的数据已经在堆栈上,则不需要这样做,但是对于大型对象,这样做很有用,因为以这种方式分配的数组只有在其作用域持续存在时才存在。如果使用堆分配的数组,可以通过 Slice() 这样的方法传递它们,并在不复制任何数据的情况下创建视图。
这里还有一些好处:
- 它们减少了垃圾收集器的分配数量。它们还减少了数据的副本数量,并提供了一种更有效的方法来同时处理多个缓冲区;
- 它们允许开发者编写高性能代码。例如,如果开发者有一大块内存需要分成小块,那么使用 Span 作为原始内存的视图。这允许开发者的应用程序直接从原始缓冲区访问字节,而无需复制;
- 它们允许开发者直接访问内存而无需复制内存。这在使用本机库或与其他语言进行互操作时特别有用;
- 它们允许开发者在性能至关重要的紧密循环(如加密或网络包检查)中消除边界检查;
- 它们允许开发者消除与通用集合(如 List)相关的装箱和取消装箱成本;
- 通过使用单一数据类型(Span)而不是两种不同类型(Array 和 ArraySegment),它们可以编写更容易理解的代码;
连续和非连续内存缓冲区
连续内存缓冲区是将数据保存在顺序相邻位置的内存块,换句话说,所有的字节在内存中都是相邻的。数组表示连续的内存缓冲区。
例如:
int[] values = new int[5];
上面示例中的五个整数将从第一个元素(值[0])开始,按顺序放置在内存中的五个位置。
与连续缓冲区不同,开发者可以使用非连续缓冲区来处理多个数据块并不相邻的情况,或者在使用非托管代码时使用非连续缓冲区,Span 和 Memory 类型是专门为非连续缓冲区设计的,并提供了使用它们的方便方法。
非连续的内存区域不能保证元素以任何特定的顺序存储,也不能保证元素在内存中紧密地存储在一起。非连续缓冲区(如 ReadOnlySequence(与段一起使用时))驻留在内存的单独区域中,这些区域可能分散在堆中,不能被单个指针访问。
例如,IEnumable 是非连续的,因为在开发者逐个枚举每个项之前,无法知道下一个项将在哪里。为了表示段之间的这些间隔,必须使用附加数据来跟踪每个段的开始和结束位置。
不连续的缓冲区: ReadOnly 序列
让作者们假设开发者正在使用一个不连续的缓冲区。例如,数据可能来自网络流、数据库调用或文件流。这些场景中的每一个都可以有多个大小不同的缓冲区。一个 ReadOnlySequence 实例可以包含一个或多个内存段,每个段可以有自己的 Memory 实例。因此,单个 ReadOnlySequence 实例可以更好地管理可用内存,并提供比许多串联内存实例更好的性能。
开发者可以使用 SequenceReader 类上的工厂方法 Create() 以及 AsReadOnlySequence() 等其他方法创建 ReadOnlySequence 实例。
Create() method has several overloads that allow developers to pass in byte[] or ArraySegment, a sequence of byte arrays (IEnumerable), or a collection of byte arrays (byte[]) and ArraySegment such as IReadOnlyCollection, IReadOnlyList, or IList, ICollection.
Developers now know that Span<T> and Memory<T> provide support for contiguous memory buffers (such as arrays). The System.Buffer namespace includes a structure named ReadOnlySequence<T>, which supports processing non-contiguous memory buffers. The following code snippet illustrates how to use ReadOnlySequence<T> in C#:
int[] array = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
var readOnlySequence = new ReadOnlySequence<int>(array);
var slicedReadOnlySequence = readOnlySequence.Slice(1, 5);
Developers can also use ReadOnlyMemory<T> as follows:
int[] array = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
ReadOnlyMemory<int> memory = array;
var readOnlySequence = new ReadOnlySequence<int>(memory);
var slicedReadOnlySequence = readOnlySequence.Slice(1, 5);
Real-World Scenario
Now let's talk about a real-world scenario and how Span<T> and Memory<T> come into play. Consider the following array of strings, which contains log data retrieved from a log file:
string[] logs = new string[]
{
"a1K3vlCTZE6GAtNYNAi5Vg::05/12/2022 09:10:00 AM::http://localhost:2923/api/customers/getallcustomers",
"mpO58LssO0uf8Ced1WtAvA::05/12/2022 09:15:00 AM::http://localhost:2923/api/products/getallproducts",
"2KW1SfJOMkShcdeO54t1TA::05/12/2022 10:25:00 AM::http://localhost:2923/api/orders/getallorders",
"x5LmCTwMH0isd1wiA8gxIw::05/12/2022 11:05:00 AM::http://localhost:2923/api/orders/getallorders",
"7IftPSBfCESNh4LD9yI6aw::05/12/2022 11:40:00 AM::http://localhost:2923/api/products/getallproducts"
};
Keep in mind that developers may have millions of log entries, so performance is crucial. This example represents log data extracted from a large volume of logs. Each line of data consists of an HTTP request ID, the DateTime of the HTTP request, and the endpoint URL. Now, suppose the developer needs to extract the request ID and endpoint URL from this data.
The developer requires a high-performance solution. Using the Substring method of the String class would create many string objects, which would decrease the application's performance. The best solution is to use Span<T> here to avoid allocations. The solution to this problem is to use Span<T> along with the Slice method, as illustrated in the next section.
Benchmarking
It's time to measure performance. Now the authors will benchmark the performance of the Span<T> struct against the Substring method of the String class.
Installing NuGet Packages
So far, so good. The next step is to install the necessary NuGet packages. To install the required package into the project, right-click on the solution and select Manage NuGet Packages for Solution.... Now search for the package named BenchmarkDotNet in the search box and install it. Alternatively, developers can also type the following command in the NuGet Package Manager console:
PM> Install-Package BenchmarkDotNet
Benchmarking Span
Now let’s investigate how to benchmark the performance of the Substring and Slice methods. Use the code from Listing 1 to create a new class called BenchmarkPerformance. Developers should note how the data is set up in the GlobalSetup method and the use of the GlobalSetup attribute.
[MemoryDiagnoser]
[Orderer(BenchmarkDotNet.Order.SummaryOrderPolicy.FastestToSlowest)]
[RankColumn]
public class BenchmarkPerformance
{
[Params(100, 200)]
public int N;
string countries = null;
int index, numberOfCharactersToExtract;
[GlobalSetup]
public void GlobalSetup()
{
countries = "India, USA, UK, Australia, Netherlands, Belgium";
index = countries.LastIndexOf(",", StringComparison.Ordinal);
numberOfCharactersToExtract = countries.Length - index;
}
}
Now, write two methods named Substring and Span as shown in Listing 2. The former uses the Substring method from the String class to retrieve the last country name, while the latter uses the Slice method to extract the last country name.
[Benchmark]
public void Substring()
{
for(int i = 0; i < N; i++)
{
var data = countries.Substring(index + 1, numberOfCharactersToExtract - 1);
}
}
[Benchmark(Baseline = true)]
public void Span()
{
for(int i = 0; i < N; i++)
{
var data = countries.AsSpan().Slice(index + 1, numberOfCharactersToExtract - 1);
}
}

Executing the Benchmark
class Program
{
static void Main()
{
BenchmarkRunner.Run<BenchmarkPerformance>();
}
}
To execute the benchmark, set the project's build configuration to "Release" and run the following command in the same directory as the project file:
dotnet run -c Release
The diagram below shows the results of the benchmark execution.
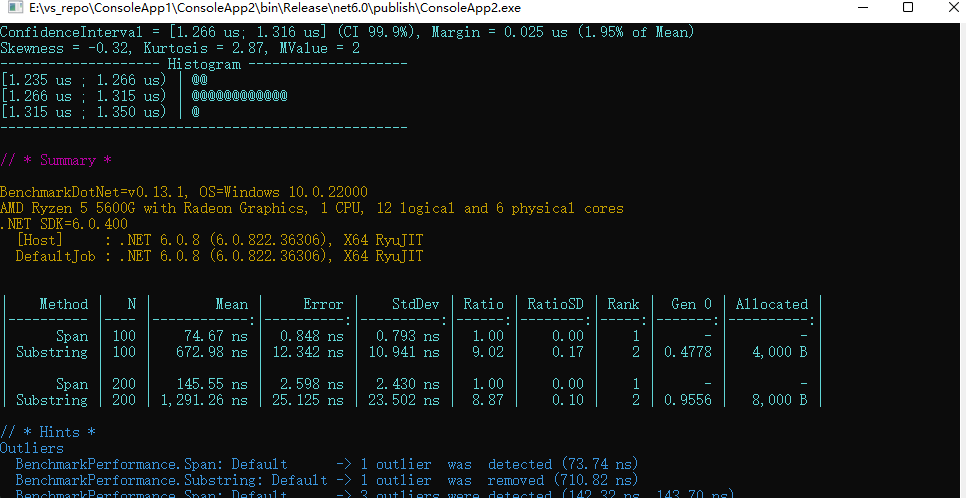
Interpreting Benchmark Results
As shown in the diagram from the previous section, there was absolutely no allocation when using the Slice method to extract the string. For each benchmark method, a line of result data is generated. Since there are two benchmark methods, there are two lines of benchmark result data. The benchmark results indicate the average execution time, Gen0 collections, and allocated memory. From the benchmark results, it is evident that Span is over 7.5 times faster than the Substring method (the result in the graphic is 9 times).
Limitations of Span
Span<T> is stack-only, which means it is not suitable for storing references to buffers on the heap, such as in routines that perform asynchronous calls. It is allocated on the stack, not in the managed heap, and it does not support boxing to prevent upgrading to the managed heap. Span<T> cannot be used as a generic type, but it can be used as a field type in a ref struct. Span<T> cannot be assigned to variables of dynamic type, object type, or any other interface type. It cannot be used as a field in a reference type and cannot be used across await and yield boundaries. Furthermore, since Span<T> does not implement IEnumerable, it cannot be used with LINQ.
It is important to note that a class cannot have Span<T> fields, Span<T> arrays cannot be created, nor can Span<T> instances be included. Note that neither Span<T> nor Memory<T> implements IEnumerable<T>, therefore developers cannot use LINQ to operate on either of them. However, developers can utilize libraries like SpanLinq, NetFabric, and Hyperlinq to work around this limitation.
Conclusion
In this article, the authors explored the features and advantages of Span<T> and Memory<T>, as well as how to implement them in applications. The authors also discussed a real-world scenario where SpanSpan<T> is more versatile and performs better than Memory<T>, but it does not completely replace it.

文章评论