Initialization
When KernelMemory starts, it checks the configuration, even if the current code does not utilize the relevant features.
var hasQueueFactory = (this._memoryServiceCollection.HasService<QueueClientFactory>());
var hasContentStorage = (this._memoryServiceCollection.HasService<IContentStorage>());
var hasMimeDetector = (this._memoryServiceCollection.HasService<IMimeTypeDetection>());
var hasEmbeddingGenerator = (this._memoryServiceCollection.HasService<ITextEmbeddingGenerator>());
var hasMemoryDb = (this._memoryServiceCollection.HasService<IMemoryDb>());
var hasTextGenerator = (this._memoryServiceCollection.HasService<ITextGenerator>());
if (hasContentStorage && hasMimeDetector && hasEmbeddingGenerator && hasMemoryDb && hasTextGenerator)
{
return hasQueueFactory ? ClientTypes.AsyncService : ClientTypes.SyncServerless;
}
Since KernelMemory itself has default services, only ITextEmbeddingGenerator and ITextGenerator must be configured.
var memory = new KernelMemoryBuilder()
// Configure document parsing vector model
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = Environment.GetEnvironmentVariable("AzureOpenAI:ApiKey")
})
// Configure text generation model
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIKey = Environment.GetEnvironmentVariable("AzureOpenAI:ApiKey"),
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})
Importing Documents
If only importing documents and generating vectors, only the Embedding model will be used.
var memory = new KernelMemoryBuilder()
// Store files
.WithSimpleFileStorage("files")
// Configure document parsing vector model
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = Environment.GetEnvironmentVariable("AzureOpenAI:ApiKey")
})
// Configure text generation model
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "aaa",
Endpoint = Environment.GetEnvironmentVariable("AzureOpenAI:Endpoint"),
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
// This can be anything, as it is not needed
APIKey = "11111111111",
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})
//// Store vectors
//.WithSimpleVectorDb(new SimpleVectorDbConfig
//{
// Directory = "aaa"
//})
.Build();
// Import webpage
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02").ConfigureAwait(false);
// Wait for ingestion to complete, usually 1-2 seconds
Console.WriteLine("Processing document, please wait...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02").ConfigureAwait(false))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500)).ConfigureAwait(false);
}
After importing the document, it will be split into multiple .txt files.
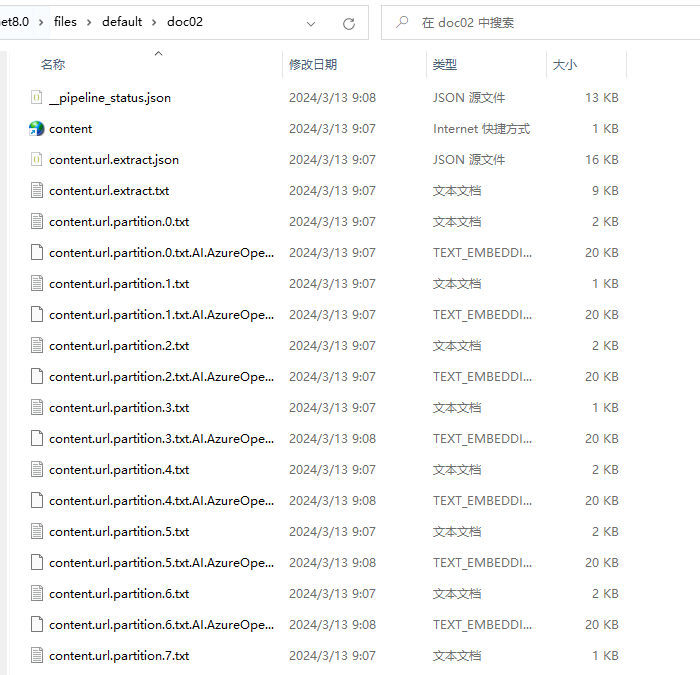
Since the vector storage location is not configured, vectors will default to generation in the same command, such as content.url.partition.0.txt.AI.AzureOpenAI.AzureOpenAITextEmbeddingGenerator.TODO.text_embedding. Each document fragment will generate a portion of the vector.
If you choose to store the files in a directory, they will be stored in a {index}/{documentId} manner. If index is not set, it will default to default.
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02", index: "test").ConfigureAwait(false);
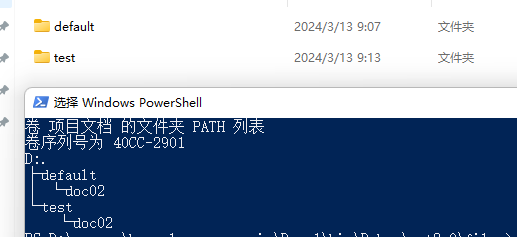
Storing Vectors in the Database
By default, vectors are stored in the directory where the files are located.
If Memory is configured, it will specify where to store, such as using a Postgres database to store vectors.
// Store vectors
.WithPostgresMemoryDb(new PostgresConfig
{
ConnectionString = "Host=0.0.0.0;Port=5432;Username=postgres;Password=password;"
})
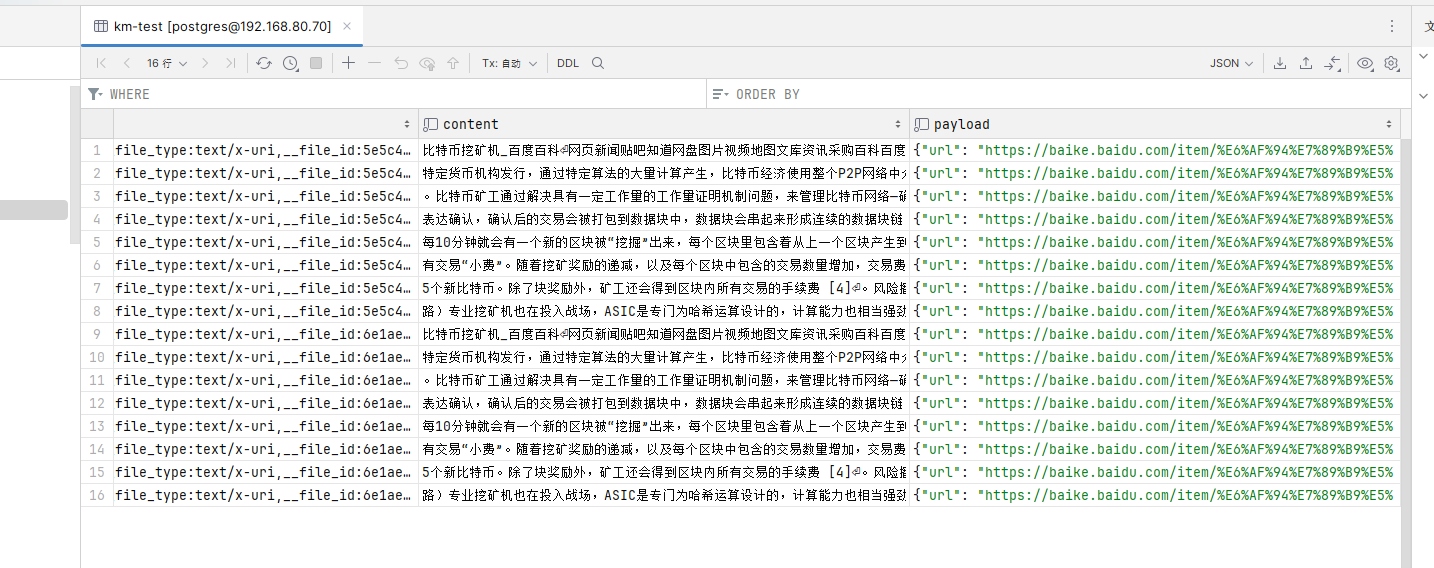
By default, it will be stored in the km-test table of the public database.
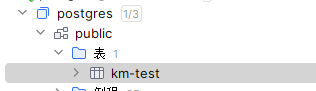
The main fields are embedding and content.
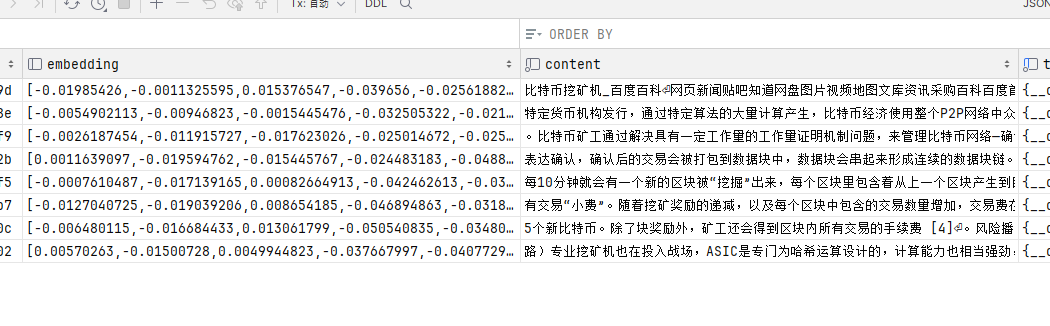
Content is each segment of text after splitting the document, and each segment will generate vectors in the embedding field.
Here is the full code example:
var memory = new KernelMemoryBuilder()
// Store files
.WithSimpleFileStorage("files")
// Configure document parsing vector model
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
//
})
// Store vectors
.WithPostgresMemoryDb(new PostgresConfig
{
ConnectionString = //
})
// Configure text generation model
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
//
})
.Build();
// Import webpage
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02", index: "test").ConfigureAwait(false);
// Wait for ingestion to complete, usually 1-2 seconds
Console.WriteLine("Processing document, please wait...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02", index: "test")).ConfigureAwait(false))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500)).ConfigureAwait(false);
}
You can modify the default database name and table prefix:
// Store vectors
.WithPostgresMemoryDb(new PostgresConfig
{
ConnectionString = "Host=0.0.0.0;Port=5432;Username=postgres;Password=password;",
Schema = "Database Name",
TableNamePrefix = "km-"
})
You cannot directly set the table name, only the prefix, so the final table name will be {TableNamePrefix}{index}.
Thus, generally, the ID string of the knowledge base acts as the index, with one table per knowledge base and multiple files/documents under each knowledge base.
If we use a database or other means to store vectors, there is no need to set up Storage, and this configuration can be removed:
// Store files
.WithSimpleFileStorage("files")
Additionally, the framework likely has no unique detection, so the same document, when index and documentId are the same, can still be imported. However, this will lead to duplicate text fragments being created.
You need to implement duplicate detection to avoid importing the same document multiple times.
Document Splitting Processing
When we import documents or import webpage addresses, the framework performs some relatively complex processing on the document.
// Import webpage
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02", index: "test").ConfigureAwait(false);
The definition of ImportWebPageAsync is as follows:
public Task<string> ImportWebPageAsync(
string url,
string? documentId = null,
TagCollection? tags = null,
string? index = null,
IEnumerable<string>? steps = null,
CancellationToken cancellationToken = default);
There is a steps parameter in ImportWebPageAsync, which indicates how to process the document.
By default, four steps are automatically set:

All the steps supported by the framework are as follows:
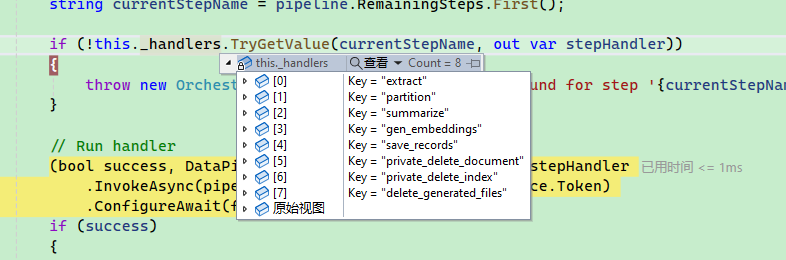
Finally, the document is processed in multiple steps based on steps, with each step corresponding to an IPipelineStepHandler type.

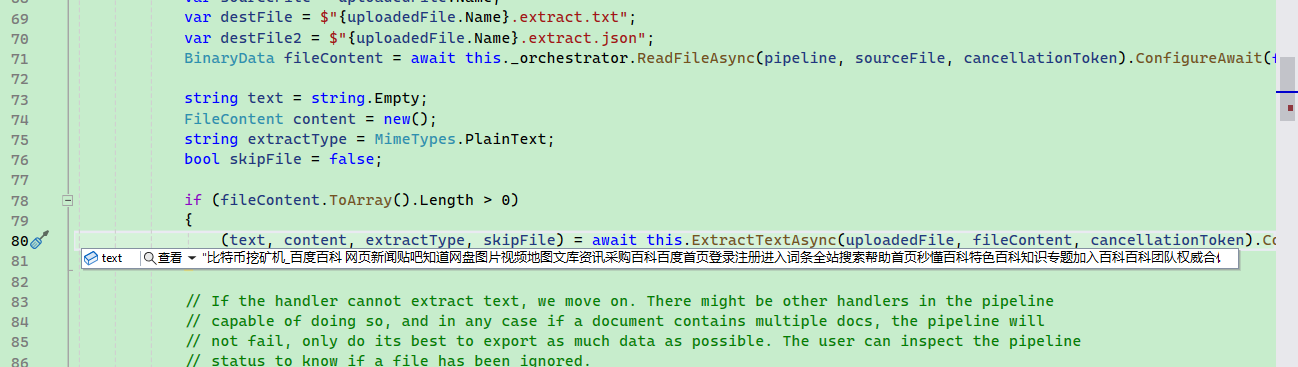
For example, the extract memory ingestion pipeline handler is responsible for extracting text from files and saving it to content storage, which is responsible for splitting document fragments; its processor is TextExtractionHandler, which can process text, Markdown, pdf, json, word, excel, html, images, etc. TextPartitioningHandler will divide the text into smaller chunks.
By default, the framework injects these handlers, and the code is located in service\Core\Handlers\DependencyInjection.cs.
/// <summary>
/// Register default handlers in the synchronous orchestrator (e.g. when not using queues)
/// </summary>
/// <param name="syncOrchestrator">Instance of <see cref="InProcessPipelineOrchestrator"/></param>
public static InProcessPipelineOrchestrator AddDefaultHandlers(this InProcessPipelineOrchestrator syncOrchestrator)
{
syncOrchestrator.AddHandler<TextExtractionHandler>(Constants.PipelineStepsExtract);
syncOrchestrator.AddHandler<TextPartitioningHandler>(Constants.PipelineStepsPartition);
syncOrchestrator.AddHandler<SummarizationHandler>(Constants.PipelineStepsSummarize);
syncOrchestrator.AddHandler<GenerateEmbeddingsHandler>(Constants.PipelineStepsGenEmbeddings);
syncOrchestrator.AddHandler<SaveRecordsHandler>(Constants.PipelineStepsSaveRecords);
syncOrchestrator.AddHandler<DeleteDocumentHandler>(Constants.PipelineStepsDeleteDocument);
syncOrchestrator.AddHandler<DeleteIndexHandler>(Constants.PipelineStepsDeleteIndex);
syncOrchestrator.AddHandler<DeleteGeneratedFilesHandler>(Constants.PipelineStepsDeleteGeneratedFiles);
return syncOrchestrator;
}
public static IServiceCollection AddHandlerAsHostedService<THandler>(
this IServiceCollection services, string stepName) where THandler : class, IPipelineStepHandler
{
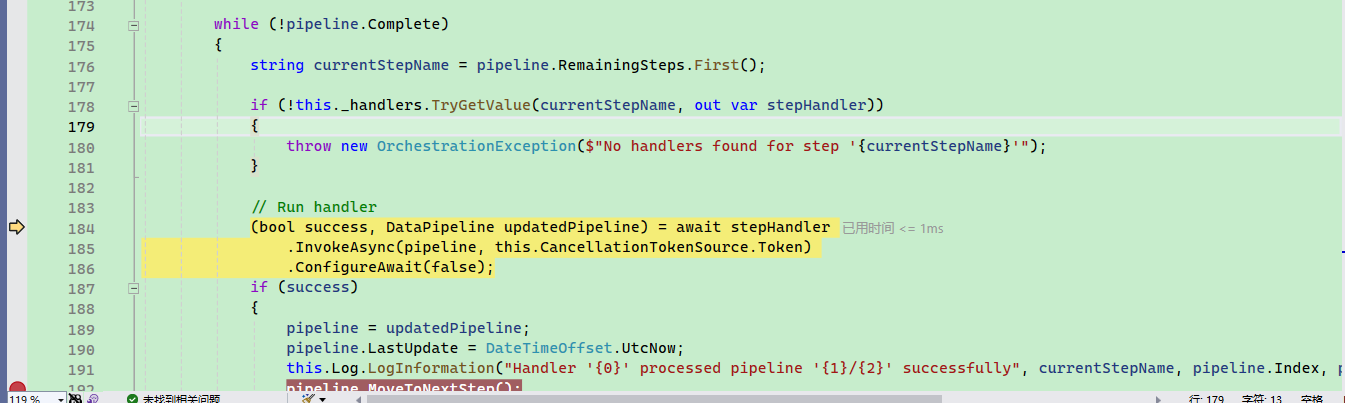
services.AddTransient<THandler>(
serviceProvider => ActivatorUtilities.CreateInstance<THandler>(serviceProvider, stepName));
services.AddHostedService<HandlerAsAHostedService<THandler>>(
serviceProvider => ActivatorUtilities.CreateInstance<HandlerAsAHostedService<THandler>>(serviceProvider, stepName));
return services;
}
Each handler has its own configuration, such as the maximum number of tokens for the TextPartitioningHandler configured through TextPartitioningOptions.
However, the KernelMemory framework does not allow developers to manipulate these executors directly. If configuration of relevant handlers is required, it needs to use extension functions, such as configuring document slicing:
.WithCustomTextPartitioningOptions(new TextPartitioningOptions
{
// Max 99 tokens per sentence
MaxTokensPerLine = 99,
// When sentences are merged into paragraphs (aka partitions), stop at 299 tokens
MaxTokensPerParagraph = 299,
// Each paragraph contains the last 47 tokens from the previous one
OverlappingTokens = 47,
})
Knowledge Base Search
To search and ask questions through the knowledge base, it requires using a text generation model; of course, chat models can also be utilized. When asking a question, it is best to set the index. As mentioned earlier, there should be one index per knowledge base. Therefore, when asking questions, the framework first searches the corresponding index (which correlates to a table) for associated knowledge, then pushes that knowledge and the question to the AI to summarize and answer.
var memory = new KernelMemoryBuilder()
// Configure the document parsing vector model
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
})
// Store vectors
.WithPostgresMemoryDb(new PostgresConfig
{
})
// Configure text generation model
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
})
.Build();
// Ask a question
var answer = await memory.AskAsync("What is Bitcoin?", index: "test").ConfigureAwait(false);
Console.WriteLine($"\nAnswer: {answer.Result}");
In the SearchClient.AskAsync method, the code for these searches and questions can be found.
Search:
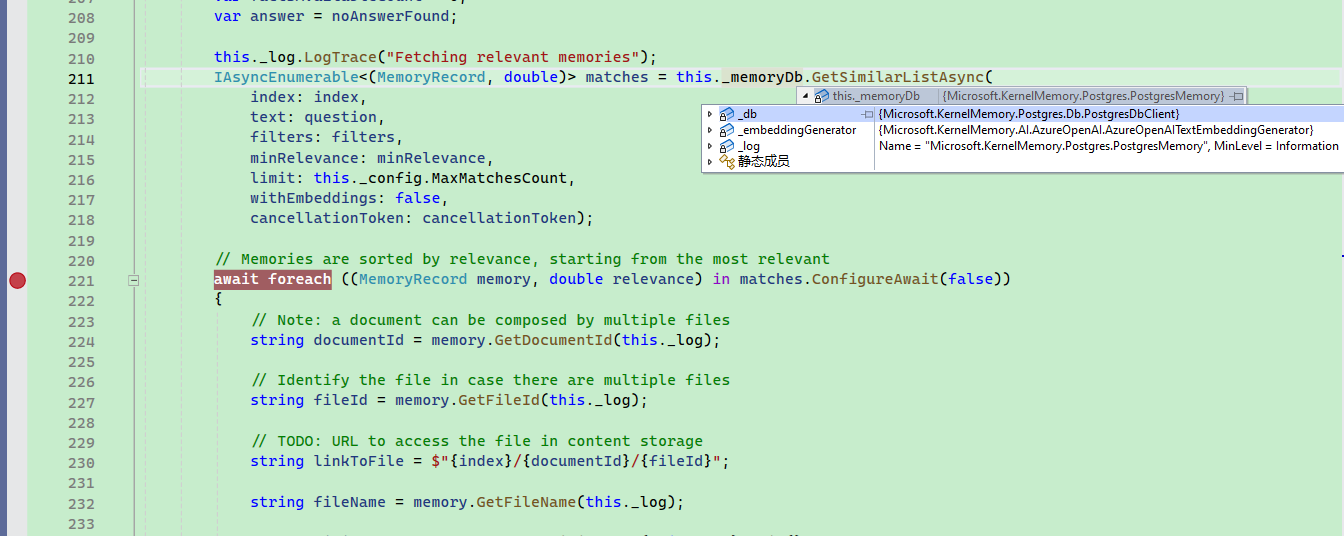
When searching in the vector database, multiple relevant texts and their relevancy scores are provided.
These texts are then merged together and sent to the AI along with the question. The framework generates the prompt engineering for these texts and the question.
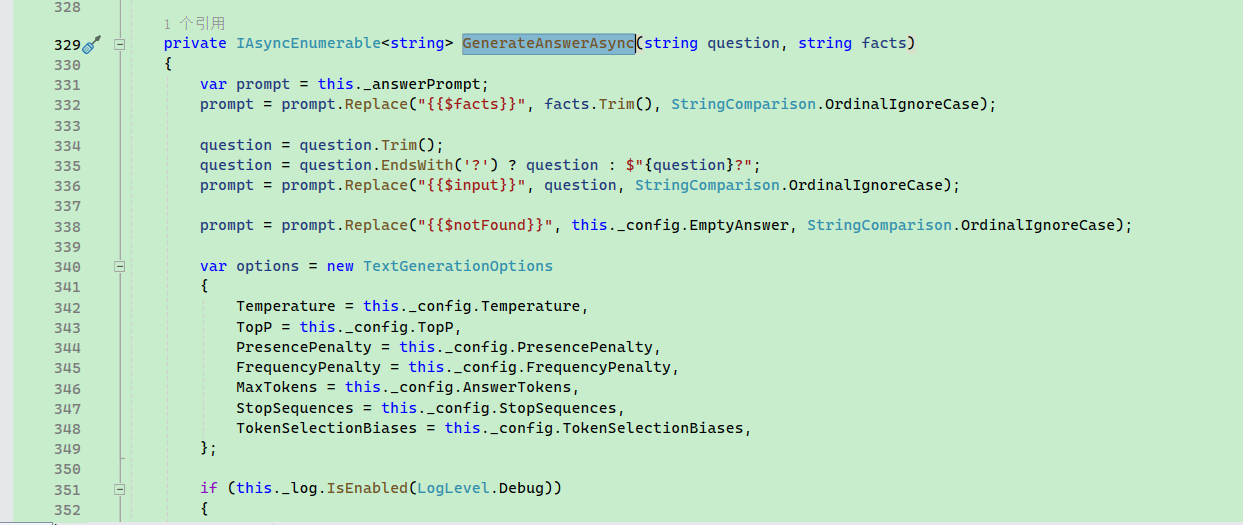
Finally, var x in this.GenerateAnswerAsync(question, facts.ToString()) returns the text in a streaming manner.

To allow for configuration use during searches, the configuration needs to be injected when building the service.
static async Task Main(string[] args)
{
var memoryBuilder = new KernelMemoryBuilder()
// ...
;
memoryBuilder.Services.AddSearchClientConfig(new SearchClientConfig
{
});
var memory = memoryBuilder.Build();
Search
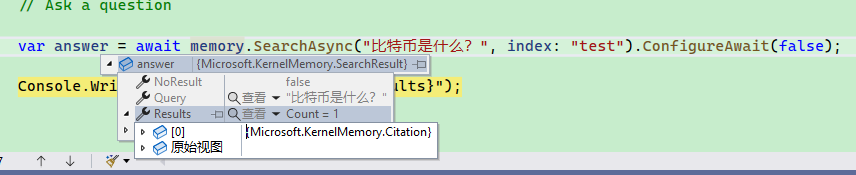
You can use KernelMemory to search within the knowledge base without asking the AI a question. An example is as follows:
var answer = await memory.SearchAsync("What is Bitcoin?", index: "test").ConfigureAwait(false);
Console.WriteLine($"\nAnswer: {answer.Results}");
By default, there is no limit to the number of texts returned during searches. To avoid excessive numbers, you can set the limit parameter, which will use only the most relevant texts afterward.
var answer = await memory.SearchAsync("What is Bitcoin?", index: "test", limit: 2).ConfigureAwait(false);
A complete definition is as follows:
/// <summary>
/// Search for a list of relevant documents for the given query in the provided index.
/// </summary>
/// <param name="query">Question</param>
/// <param name="index">Index index</param>
/// <param name="filter">Filtering rules</param>
/// <param name="filters">Filters to match (using an OR logic). If 'filter' is also provided, this value will be merged into this list.</param>
/// <param name="minRelevance">Minimum cosine similarity requirement</param>
/// <param name="limit">Maximum number of results to return</param>
/// <param name="cancellationToken">Cancellation token for asynchronous tasks</param>
public Task<SearchResult> SearchAsync(
string query,
string? index = null,
MemoryFilter? filter = null,
ICollection<MemoryFilter>? filters = null,
double minRelevance = 0,
int limit = -1,
CancellationToken cancellationToken = default);
Example:
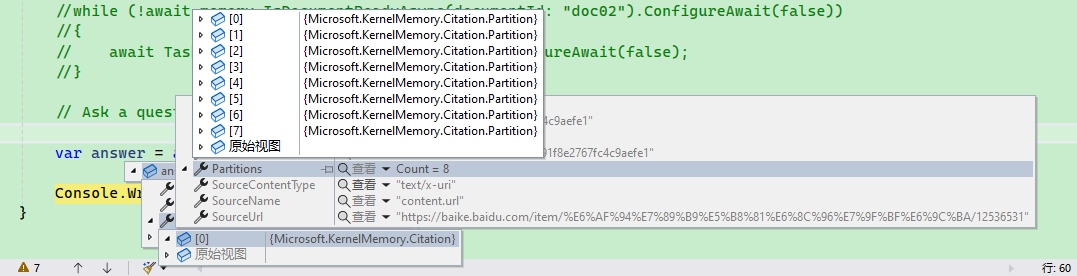
var searchResult = await memory.SearchAsync("What is Bitcoin?", index: "test", limit: 2).ConfigureAwait(false);
// Each Citation represents a document file
foreach (Citation citation in searchResult.Results)
{
// Text relevant to the search keywords
foreach (var partition in citation.Partitions)
{
Console.WriteLine(partition.Text);
}
}

Modify OpenAI API Request URL
By default, the OpenAI API can only request the openai.com address and cannot customize the API service URL. Often there is a need to customize access to platforms like oneapi, ollama, etc., thus necessitating a modification to the request address.
Define a DelegatingHandler:
public class ADelegatingHandler : DelegatingHandler
{
public ADelegatingHandler(HttpMessageHandler innerHandler)
: base(innerHandler)
{
}
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.RequestUri.AbsoluteUri.StartsWith("https://api.openai.com/v1"))
request.RequestUri = new Uri(request.RequestUri.AbsoluteUri.Replace("https://api.openai.com/v1", "http://localhost:11434/api"));
var result = await base.SendAsync(request, cancellationToken);
return result;
}
protected override HttpResponseMessage Send(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.RequestUri.AbsoluteUri.StartsWith("https://api.openai.com/v1"))
request.RequestUri = new Uri(request.RequestUri.AbsoluteUri.Replace("https://api.openai.com/v1", "http://localhost:11434/api"));
return base.Send(request, cancellationToken);
}
}
Configure HttpClient when building KernelMemory:
var memoryBuilder = new KernelMemoryBuilder()
// Document parsing vector storage location, can choose Postgres, etc.
// Here, selecting to use local temporary file storage for vectors
// Configure document parsing vector model
.WithSimpleFileStorage(new SimpleFileStorageConfig
{
Directory = "aaaa"
})
.WithPostgresMemoryDb(new PostgresConfig
{
})
.WithOpenAITextEmbeddingGeneration(new OpenAIConfig
{
EmbeddingModel = "nomic-embed-text",
APIKey = "0"
}, httpClient: new HttpClient(new ADelegatingHandler(new HttpClientHandler())))
// Configure text generation model
.WithOpenAITextGeneration(new OpenAIConfig
{
TextModel = "gemma:7b",
APIKey = "0"
}, httpClient: new HttpClient(new ADelegatingHandler(new HttpClientHandler())));

文章评论