显卡驱动安装和深度学习环境搭建,可以参考笔者的文章:
https://www.whuanle.cn/archives/21624
https://torch.whuanle.cn/01.base/01.env.html
Testing Environment
AMD EPYC 7V13 64-Core 24 Cores
220GB RAM
NVIDIA A100 80GB PCIe
Download and Install Ollama
Open https://ollama.com/, and simply download and install it.
Configure Ollama
There are three environment variables to configure.
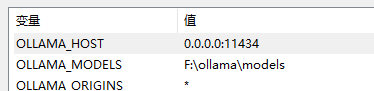
# API service listening address
OLLAMA_HOST=0.0.0.0:1234
# Allow cross-origin access
OLLAMA_ORIGINS=*
# Model file download location
OLLAMA_MODELS=F:\ollama\models
Exit all Ollama programs, and then execute the command in the console to start Ollama:
ollama serve
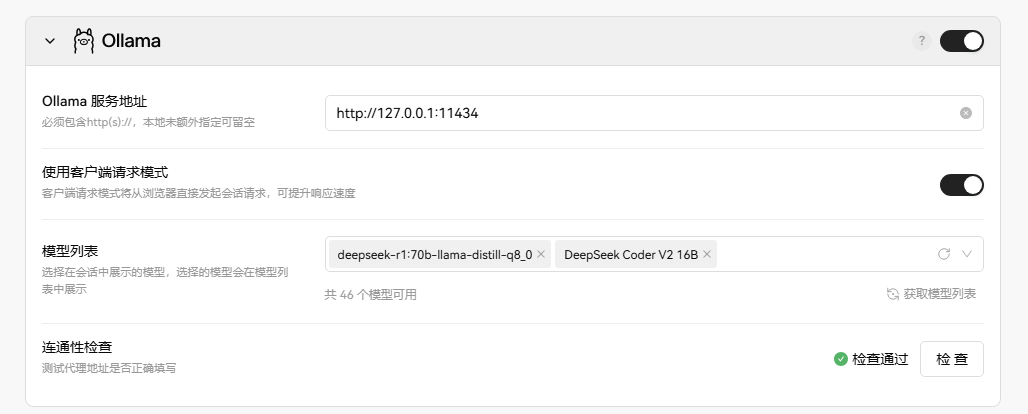
Configure the model used by Ollama in lobechat:
Using RAM to Extend GPU Memory
By default, the memory of the GPU determines the size of the models that can be run. If there is an error message like below when running a model with Ollama, it indicates that there is not enough VRAM to run the model.
Error: llama runner process has terminated: error loading model: unable to allocate CUDA_Host buffer
Error: llama runner process has terminated: error loading model: unable to allocate CUDA0 buffer
The deepseek-r1:671b model file is approximately 404GB, but my GPU has 80GB and RAM has 220GB, which is still insufficient. Therefore, we need to use RAM to extend GPU memory, and then use VRAM to extend RAM memory.
Press Windows + R, enter systempropertiesadvanced to open the System Properties panel, and enter the Virtual Memory management as shown in the figure.
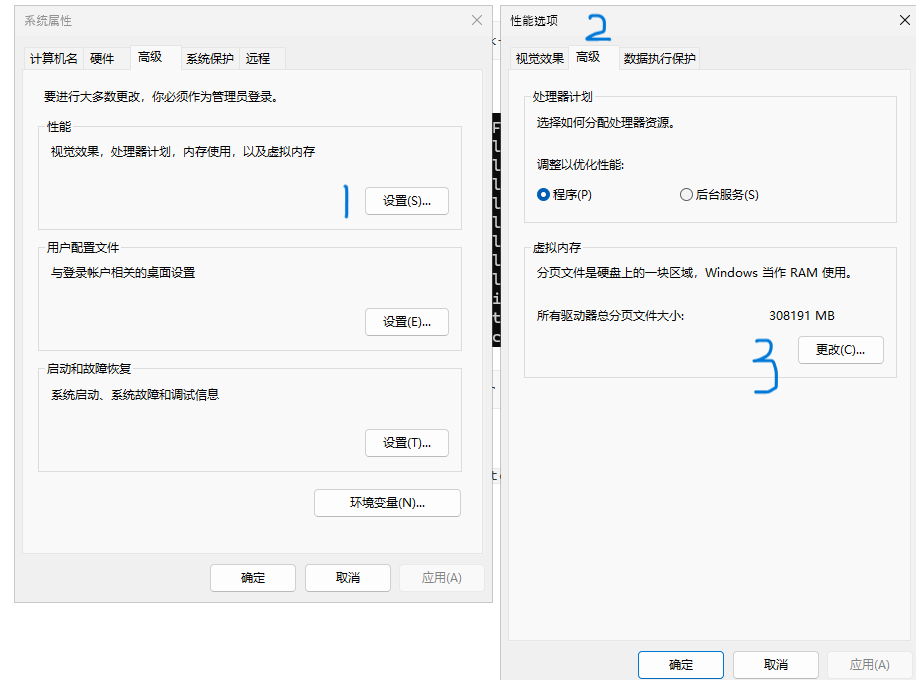
As shown in the figure below, find the drive with the fastest I/O read/write speed, set a custom size, and then click "Set" to save the configuration.
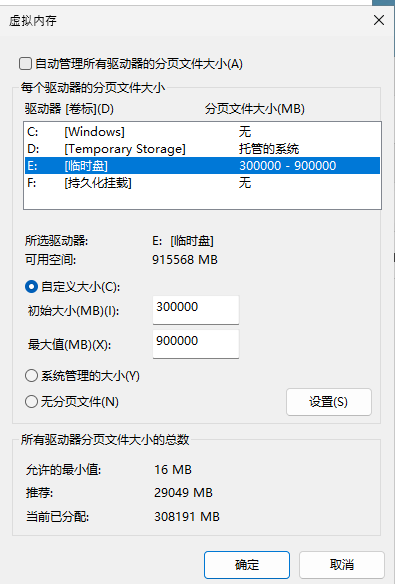
Check the Task Manager to ensure that the virtual memory has been successfully allocated, as shown in the figure below, my machine has been expanded to 521GB.

Execute the command nvidia-smi to check how much memory the GPU has.

Then add the environment variable and set OLLAMA_GPU_OVERHEAD=81920000000, which is 80GB, so Ollama will use 80GB of GPU memory and then load the model using RAM and VRAM.
Exit Ollama, exit the terminal console, and re-execute ollama run deepseek-r1:671b.
Running the Model
ollama run deepseek-r1:671b

As RAM and VRAM are being utilized, loading the model will take a long time, so please be patient.

Answering questions will be very slow.

文章评论