显卡驱动安装和深度学习环境搭建,可以参考笔者的文章:
https://www.whuanle.cn/archives/21624
https://torch.whuanle.cn/01.base/01.env.html
测试环境
AMD EPYC 7V13 64-Core 24核
220GB 内存
NVIDIA A100 80GB PCIe
下载安装 ollama
打开 https://ollama.com/,直接下载安装即可。
配置 ollama
有三个环境变量要配置。
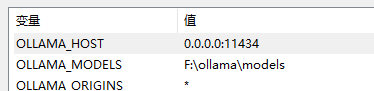
# api 服务监听地址
OLLAMA_HOST=0.0.0.0:1234
# 允许跨域访问
OLLAMA_ORIGINS=*
# 模型文件下载位置
OLLAMA_MODELS=F:\ollama\models退出所以 ollama 程序,然后在控制台执行命令启动 ollama:
ollama serve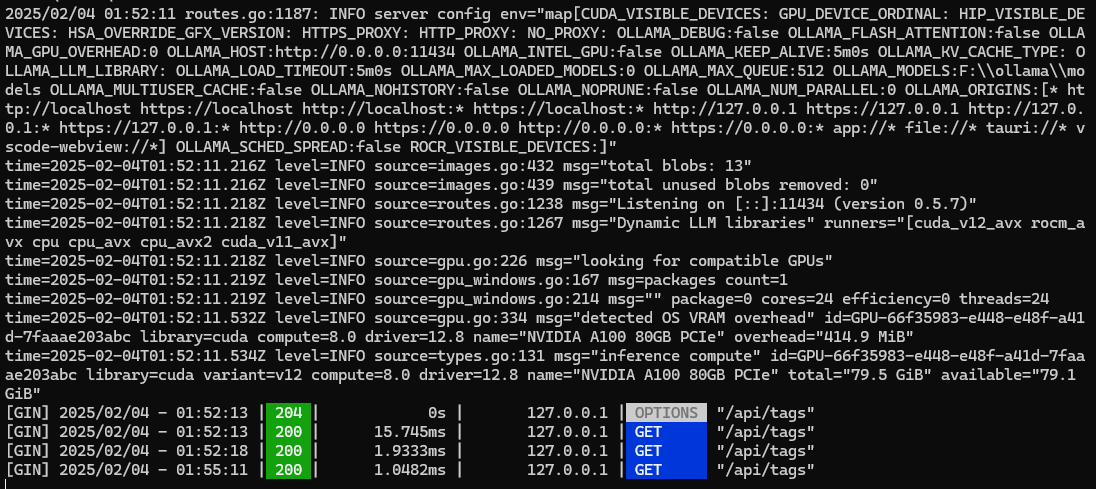
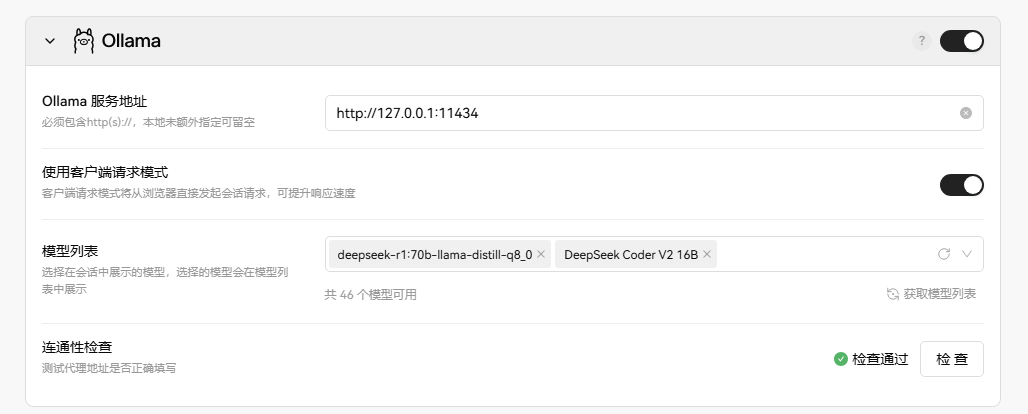
在 lobechat 中配置使用 ollama 的模型:
使用 RAM 内存扩展显卡内存
默认情况下,显卡的内存决定了可以运行多大的模型,当时有 ollama 运行模型出现以下情况的报错时,说明显存不足以运行该模型。
Error: llama runner process has terminated: error loading model: unable to allocate CUDA_Host buffer
Error: llama runner process has terminated: error loading model: unable to allocate CUDA0 bufferdeepseek-r1:671b 模型文件大约 404GB,但是笔者的显卡是 80GB,RAM 是 220GB,都凑一块还是不够,那么就需要使用 RAM 内存扩展显存,接着使用 VRAM 内存扩展 RAM 内存。
按下 Windows + R 键,输入 systempropertiesadvanced 打开系统属性面板,按下图所示进入虚拟内存管理。
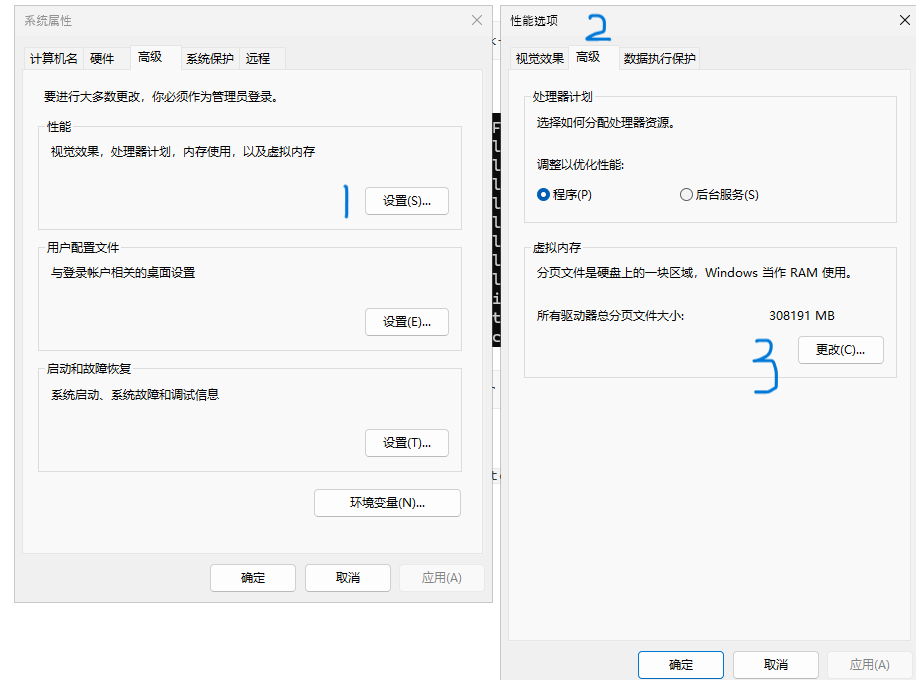
按照下图所示,找一个 IO 读写速度最快的驱动器,设置自定义大小空间,然后点击 “设置” 保存配置。
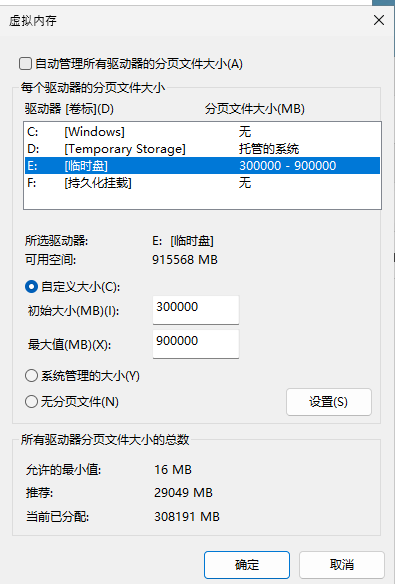
查看任务管理器,检查虚拟内存是否成功分配,如下图所示,笔者的机器已经扩展到 521GB 内存。

执行命令 nvidia-smi ,查看显卡有多少内存。

然后添加环境变量,设置 OLLAMA_GPU_OVERHEAD=81920000000,即 80GB,ollama 会在显卡上使用 80GB 的显存,然后使用 RAM、VRAM 加载模型。
退出 ollama ,退出终端控制台,重新执行 ollama run deepseek-r1:671b。
运行模型
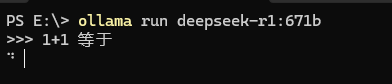
ollama run deepseek-r1:671b
由于使用了 RAM 和 VRAM,因此加载模型需要非常长的时间,这里耐心等待。

回答问题非常慢。

文章评论