[TOC]
作者:痴者工良
博客园:https://www.cnblogs.com/whuanle/
本教程地址:https://kafka.whuanle.cn/
本教程是关于 Kafka 知识的教程,从 C# 中实践编写 Kafka 程序,一边写代码一边了解 Kafka。
教程内容是过年期间写的,写到一半假期结束要上班了,将已完成的部分整理出来,就不继续写了。
1, 搭建 Kafka 环境
本章的内容比较简单,我们将使用 Docker 快速部署一个单节点的 Kafka 或 Kafka 集群,在后面的章节中,将会使用已经部署好的 Kafka 实例做实验,然后我们通过不断地实验,逐渐了解 Kafka 的知识点以及掌握客户端的使用。
这里笔者给出了单机和集群两种部署方式,但是为了便于学习后面的章节,请以集群的方式部署 Kafka。
安装 docker-compose
使用 docker-compose 部署 Kafka 可以减少很多没必要的麻烦,一个脚本即可完成部署,省下折腾时间。
安装 docker-compose 也是挺简单的,直接下载二进制可执行文件即可。
INSTALLPATH=/usr/local/bin
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o ${INSTALLPATH}/docker-compose
sudo chmod +x ${INSTALLPATH}/docker-compose
docker-compose --version如果系统没有映射
/usr/local/bin/路径,执行命令完成后,如果发现找不到docker-compose命令,请将文件下载到/usr/bin,即替换INSTALLPATH=/usr/local/bin为INSTALLPATH=/usr/bin。
单节点 Kafka 的部署
创建一个 docker-compose.yml 文件,文件内容如下:
---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.3.0
container_name: broker
ports:
# To learn about configuring Kafka for access across networks see
# https://www.confluent.io/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.156:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
volumes:
- /data/kafka/broker/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock请替换
PLAINTEXT://192.168.3.156中的 IP 。
然后执行命令开始部署应用:
docker-compose up -d接着,安装 kafdrop,这是一个 Kafka 管理界面,可以很方便地查看一些信息。
docker run -d --rm -p 9000:9000 \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e KAFKA_BROKERCONNECT=192.168.3.156:9092 \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop
Kafka 集群的部署
Kafka 集群的部署方法有很多,方法不尽相同,其中使用的配置参数(环境变量)也很多,这里笔者只给出自己在使用的快速部署参数,读者可以参阅官方文档,以便定制配置。
笔者的部署脚本中其中一些重要的环境变量说明如下:
KAFKA_BROKER_ID: 当前 Broker 实例的 id,Broker id 不能重复;KAFKA_NUM_PARTITIONS:默认 Topic 的分区数量,默认为 1,如果设置了这个配置,自动创建的 Topic 会根据这个大小设置分区数量。KAFKA_DEFAULT_REPLICATION_FACTOR:默认 Topic 分区的副本数;KAFKA_ZOOKEEPER_CONNECT:Zookeeper 地址;KAFKA_LISTENERS:Kafka Broker 实例监听的 ip;KAFKA_ADVERTISED_LISTENERS:外部如何访问当前实例,用于 Zookeeper 监控;
创建一个 docker-compose.yml 文件,文件内容如下:
---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka1:
image: confluentinc/cp-kafka:7.3.0
container_name: broker1
ports:
- 19092:9092
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_NUM_PARTITIONS: 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 2
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.158:19092
volumes:
- /data/kafka/broker1/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock
kafka2:
image: confluentinc/cp-kafka:7.3.0
container_name: broker2
ports:
- 29092:9092
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 2
KAFKA_NUM_PARTITIONS: 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 2
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.158:29092
volumes:
- /data/kafka/broker2/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock
kafka3:
image: confluentinc/cp-kafka:7.3.0
container_name: broker3
ports:
- 39092:9092
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 3
KAFKA_NUM_PARTITIONS: 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 2
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.158:39092
volumes:
- /data/kafka/broker3/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock由于三个 Broker 实例都在同一个虚拟机上面,因此这里通过暴露不同的端口,避免 Broker 冲突。
然后执行命令开始部署应用:
docker-compose up -d接着部署 kafdrop:
docker run -d --rm -p 9000:9000 \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e KAFKA_BROKERCONNECT=192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092 \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop
现在,已经部署好了 Kafka 环境以及管理面板。
2, Kafka 概念
在本章中,笔者会介绍 Kafka 的一些基本概念,文中的内容是笔者个人理解总结,可能会有错误或其它问题,如有疑问,欢迎指出。
基本概念
一个简单的 生产消息 -> 保存到 Broker -> 消费消息 的结构图示例如下:
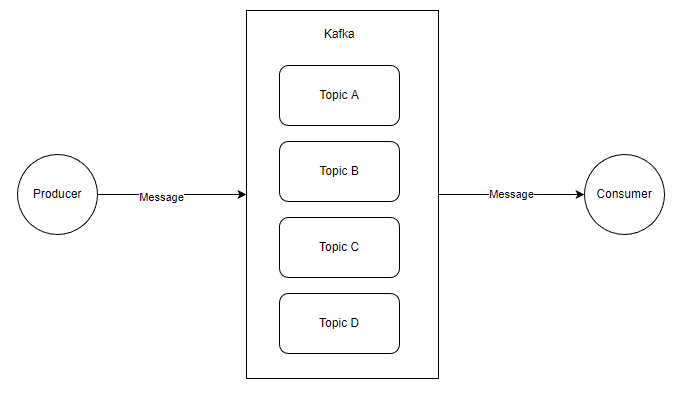
在这里,出现了四个对象:
生产者 Producer:产生 Message 的客户端;
消费者 Consumer :消费 Message 的客户端;
主题 Topic:逻辑上的东西;
消息 Message: 数据实体;
当然图中每一个对象本身都是很复杂的,这里为了便于学习,画了个简单的图,现在我们先从最简单的结构图开始了解这些东西。
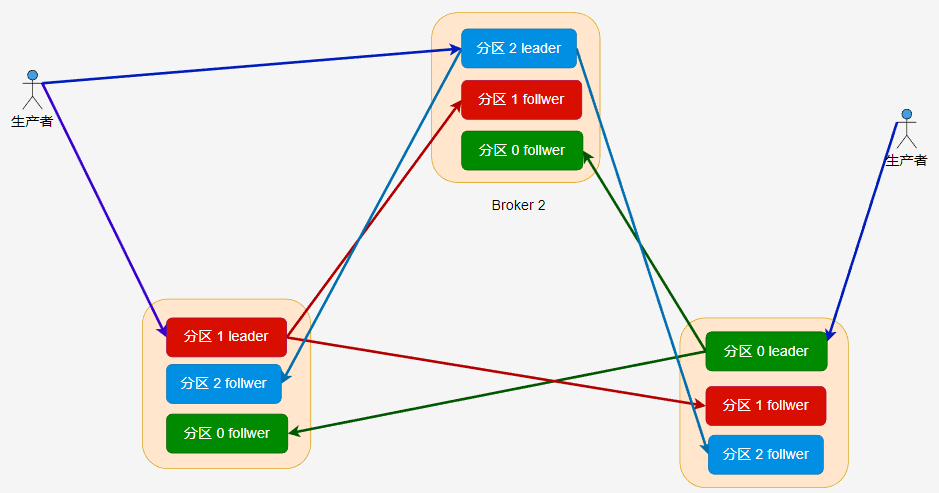
这里的图比较简单,大概是这样的, Kafka 中有多个 Topic,Producer 可以向指定的 Topic 生产一条消息,而 Consumer 可以消费指定 Topic 的消息。
Producer 和 Consumer 都是客户端应用,只是在执行的功能上有所区分,理论上 Kafka 的客户端库都是将两者的代码写在同一个模块,例如 C# 的 confluent-kafka-dotnet,同时具有生产者和消费者的 API。
然后就是这个 Message 了,Message 主要结构是:
Key
Value
其它元数据其中 Value 是我们自定义消息内容的地方。
关于 Message,我们这里简单了解即可,在后面的章节中会继续深入介绍。
在 Kafka 中,每个 Kafka 实例称为 Broker,每个 Broker 中可以保存多个 Topic。每个 Topic 可以划分为多个分区,每个分区保存的数据是不一样的,这些分区可以在同一个 Broker 中,也可以在散布在不同的 Broker 中。
一个 Broker 可以存储不同 Topic 的不同分区,也可以存储同一个 Topic 的不同分区。
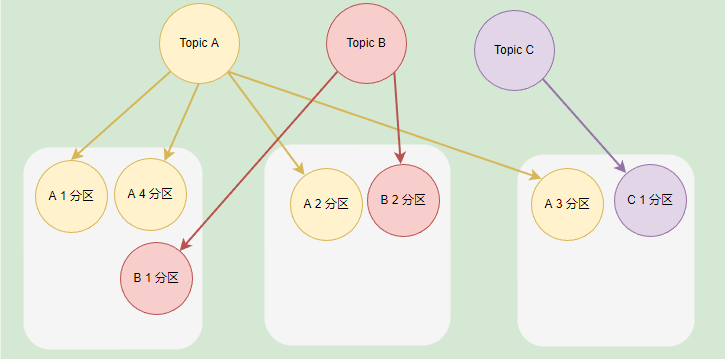
如果一个 Topic 有多个分区,一般来说其并发量会有所提高,通过增加分区数实现集群的负载均衡,一般情况下,分区均衡需要散布在不同的 Broker 才能合理地负载均衡,不然分区都在同一个 Broker 时,瓶颈在单个机器上。
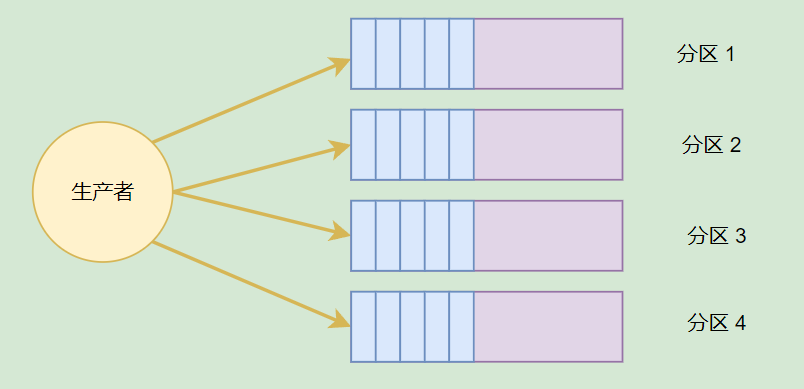
如果 Broker 的实例比较少,但是 Topic 划分了多个分区,那么这些分区会被部署到同一个 Broker 上。
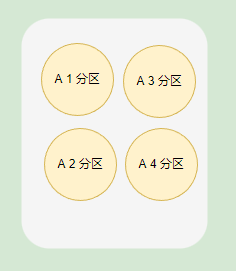
主题分区可以有效提高生产者或消费者的并发量,因为将消息分别存储到不同的分区中,可以同时往多个分区推送消息,会比只向一个分区推送消息的速度快。
前面提到,每个 Message 都有 Key 和 Value,Topic 可以根据 Message 的 Key 将一个 Message 存储到不同的分区。当然,我们也可以在生产消息的时候,指定向一个分区推送消息。
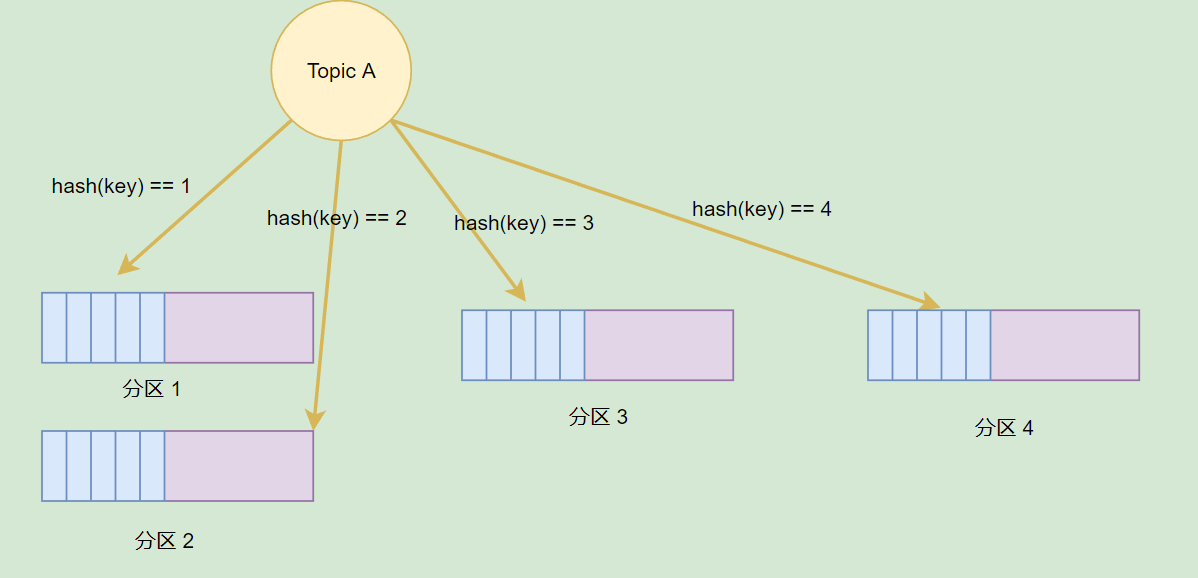
分区可以提高并发,但是如果一个 Broker 挂了,数据便会丢失,怎么办?
在 Kafka 中,分区可以设置多个分区副本,这些副本跟分区并不在同一个 Broker 上,这个当 Broker 挂了后,这些分区可以利用副本在其它 Broker 上复活。
提示
在 《Kafka权威指南(第2版)》 的 21 页中,指导了如何合理设置分区数量,以及分区的优势和缺点。
关于 Kafka 脚本工具
前面介绍了 Kafka 的一些简单概念,为了更加好地了解 Kafka,我们可以利用 Kafka 的脚本做一些实验。
打开其中一个 Kafka 容器(docker exec 命令进入容器),然后执行命令查看自带的二进制脚本:
ls -lah /usr/bin/ | grep kafka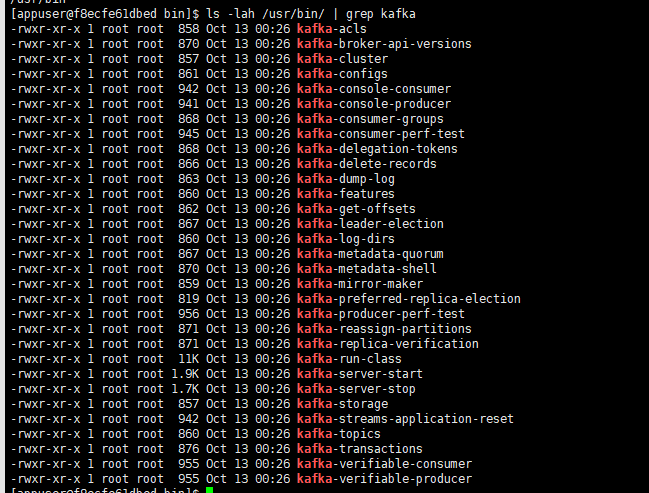
可以看到,里面有很多 CLI 工具,每种 CLI 工具说明文档可以到这里查看:
https://docs.cloudera.com/runtime/7.2.10/kafka-managing/topics/kafka-manage-basics.html
下面笔者介绍部分 CLI 工具的使用方法。
主题管理
kafka-topics 是用于主题管理的 CLI 工具,kafka-topics 提供基本操作如下所示:
- 操作:
--create:创建主题;--alter:变更这个主题,修改分区数等;--config:修改主题相关的配置;--delete:删除该主题;
在管理主题时,我们可以设置主题配置,主题配置存储时,其格式示例为 default.replication.factor ,如果用 CLI 工具操作,那么传递的参数示例为 --replication-factor,因此我们通过不同工具操作主题时,参数名称可能不同一样。
主题的所有配置参数可以查看官方文档:
kafka-topics 一些常用参数:
-
--partitions:分区数量,该主题划分成多少个分区; -
--replication-factor:副本数量,表示每个分区一共有多少个副本;副本数量需要小于或等于 Broker 的数量; -
--replica-assignment:指定副本分配方案,不能与--partitions或--replication-factor同时使用; -
--list: 列出有效的主题; -
--describe:查询该主题的信息信息。
下面是使用 CLI 手工创建主题的命令,创建主题时设置分区、分区副本。
kafka-topics --create --bootstrap-server 192.168.3.158:19092 \
--replication-factor 3 \
--partitions 3 \
--topic hello-topic
使用 CLI 时,可以通过
--bootstrap-server配置连接到一个 Kafka 实例,或者通过--zookeeper连接到 Zookeeper,然后 CLI 自动找到 Kafka 实例执行命令。
查看主题的详细信息:
kafka-topics --describe --bootstrap-server 192.168.3.158:19092 --topic hello-topicTopic: hello-topic TopicId: r3IlKv8BSMaaoaT4MYG8WA PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: hello-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: hello-topic Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: hello-topic Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1可以看到,创建的分区会被均衡分布到不同的 Broker 实例中;对于 Replicas 这些东西,我们后面的章节再讨论。
也可以打开 kafdrop 查看主题的信息。
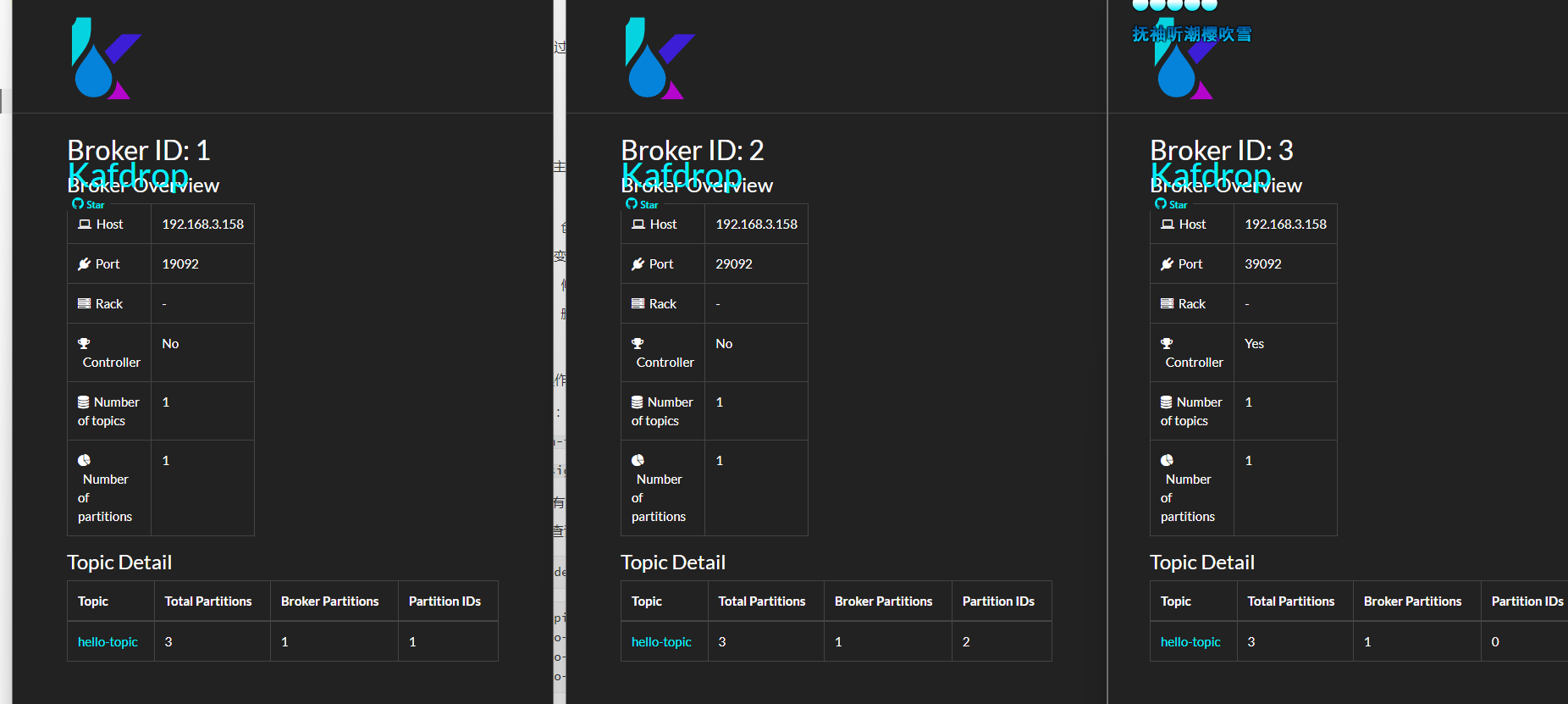
如果一个 Topic 的分区数量大于 Broker 数量呢?前面笔者已经提到,如果分区数量比较大时,部分 Broker 中会存在同一个主题的多个分区。
下面我们来实验验证一下:
kafka-topics --create --bootstrap-server 192.168.3.158:19092 \
--replication-factor 2 \
--partitions 4 \
--topic hello-topic1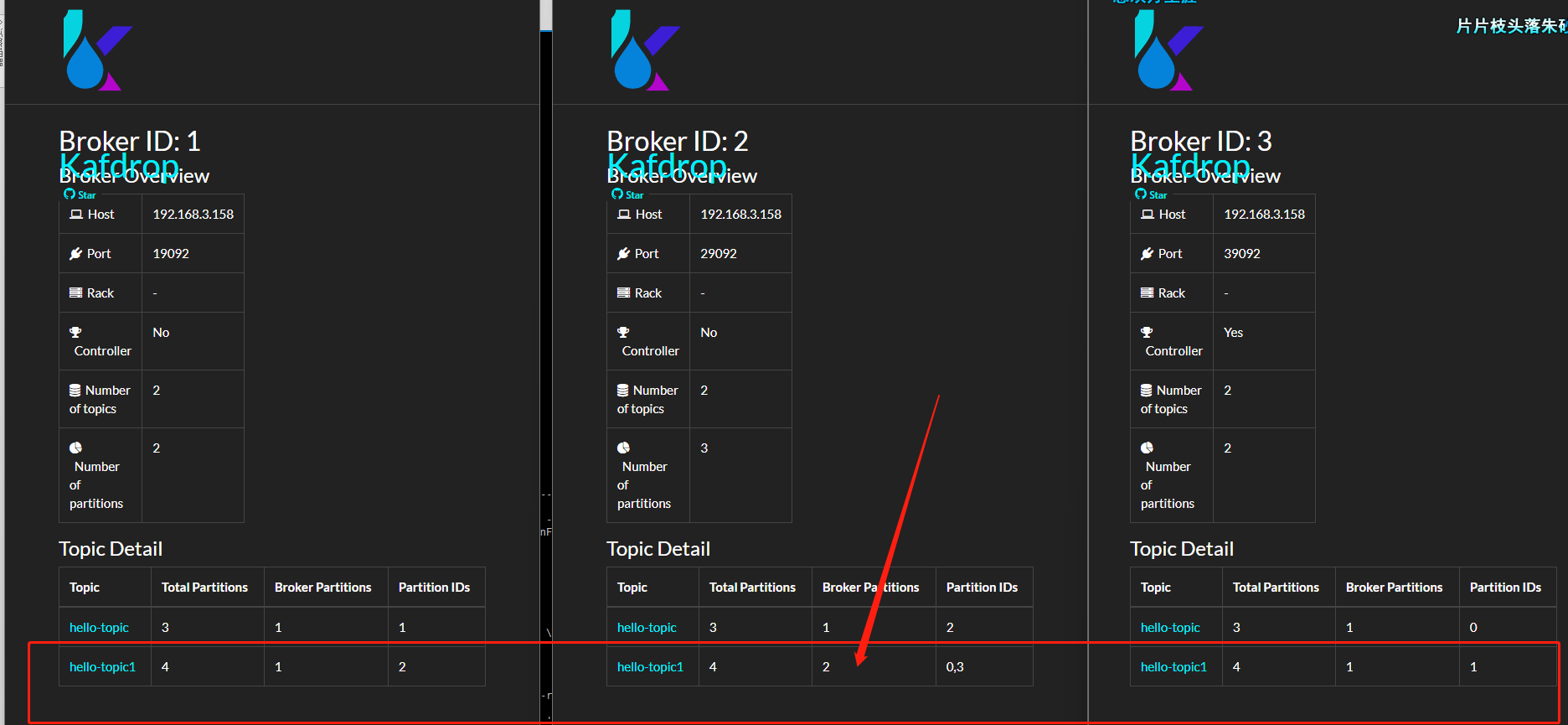
可以看到,Broker 2,分到了 hello-topic1 的两个分区。
使用 C# 创建分区
客户端库中可以利用接口管理主题,如 C# 的 confluent-kafka-dotnet,使用 C# 代码创建 Topic 的示例如下:
static async Task Main()
{
var config = new AdminClientConfig
{
BootstrapServers = "192.168.3.158:19092"
};
using (var adminClient = new AdminClientBuilder(config).Build())
{
try
{
await adminClient.CreateTopicsAsync(new TopicSpecification[] {
new TopicSpecification { Name = "hello-topic2", ReplicationFactor = 3, NumPartitions = 2 } });
}
catch (CreateTopicsException e)
{
Console.WriteLine($"An error occured creating topic {e.Results[0].Topic}: {e.Results[0].Error.Reason}");
}
}
}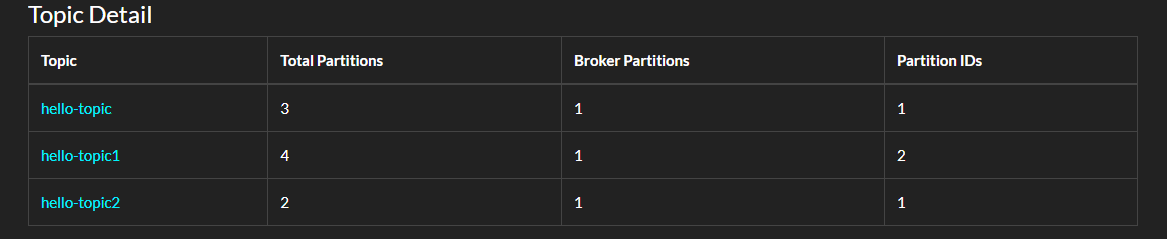
在 AdminClient 中还有很多方法可以探索。
分区与复制
在前面,我们创建了一个名为 hello-topic 的主题,并且为其设置三个分区,三个副本。
接着,使用 kafka-topics --describe 命令查看一个 Topic 的信息,可以看到:
Topic: hello-topic TopicId: r3IlKv8BSMaaoaT4MYG8WA PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: hello-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: hello-topic Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: hello-topic Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2这些数字都是指 Broker ID,Broker ID 可以是数字也可以是有英文。
主题的每个分区都有至少一个副本,也就是 --replication-factor 参数必须设置大于大于 1。副本分为 leader 和 follwer 两种,每个副本都需要消耗一个存储空间,leader 对外提供读写消息,而 follwer 提供冗余备份,leader 会及时将消息增量同步到所有 follwer 中。
Partition: 0 Leader: 3 Replicas: 3,1,2 表示分区 0 的副本分布在 ID 为 3、1、2 的 Kafka broker 中。
在 hello-topic 主题中,当分区只有一个副本时,或只关注 leader 副本时,leader 副本对应的 Broker 节点位置如下:
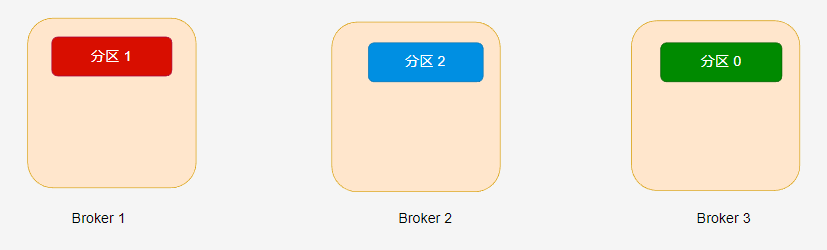
Kafka 分配分区到不同的节点有一定的规律,感兴趣的读者可参考 《Kafka 权威指南》第二版或官方文档。
如果设置了多个副本( --replication-factor=3 ) 时,leader 副本和 follwer 副本的位置如下所示:
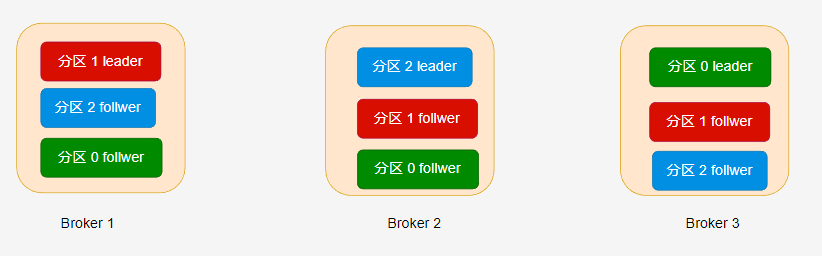
分区的副本数量不能大于 Broker 数量,每个 Broker 只能有此分区的一个副本,副本数量范围必须在
[1,{Broker数量}]中。也就是说,如果集群只有三个 Broker,那么创建的分区,其副本数量必须在[1,3]范围内。
在不同的副本中,只有 leader 副本能够进行读写,follwer 接收从 leader 推送过来的数据,做好冗余备份。
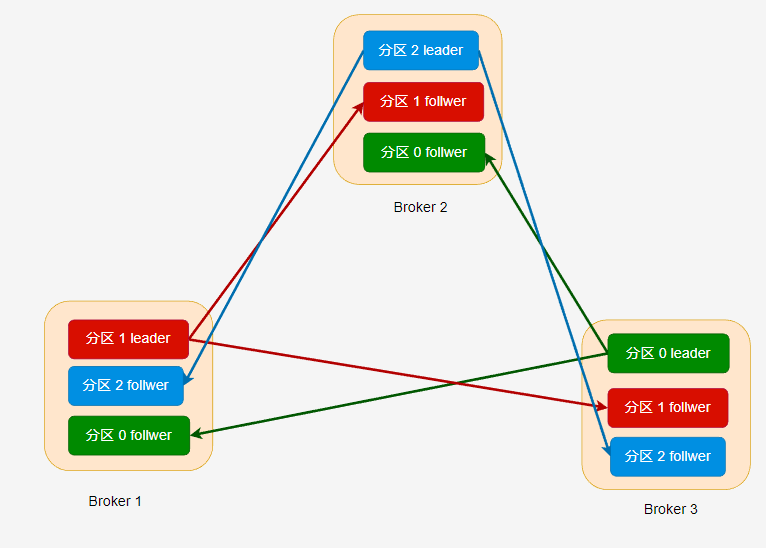
一个分区的所有副本统称为 AR(Assigned Repllicas),当 leader 接收到消息时,需要推送到 follwer 中,理想情况下,分区的所有副本的数据都是一致的。
但是 leader 同步到 follwer 的过程中可能会因为网络拥堵、故障等,导致 follwer 在一定时间内未能与 leader 中的数据一致(同步滞后),那么这些副本称为 OSR( Out-Sync Relipcas)。
如果副本中的数据为最新的数据,在给定的时间内同步没有出现滞后,那么这些副本称为 ISR。
AR = ISR + OSR如果 leader 故障,那么剩下的 follwer 会重新选举 一个 leader;但是如果 leader 接收到生产者的消息后还没有同步到 follwer 就故障了,那么这些消息就会丢失。为了避免这种情况,需要生产者设置合理的 ACK,在第四章中会讨论这个问题。
生产者消费者
kafka-console-producer 可以给指定的主题发送消息:
kafka-console-producer --bootstrap-server 192.168.3.158:19092 --topic hello-topic
kafka-console-consumer 则可以从指定主题接收消息:
kafka-console-consumer --bootstrap-server 192.168.3.158:19092 --topic hello-topic \
--group hello-group \
--from-beginning
订阅主题时,消费者需要指定消费者组。可以通过 --group 指定;如果不指定,脚本会自动为我们创建一个消费者组。
kafka-consumer-groups 则可以为我们管理消费者组,例如查看所有的消费者组:
kafka-consumer-groups --bootstrap-server 192.168.3.158:19092 --list
查看消费者组详细信息:
kafka-consumer-groups --bootstrap-server 192.168.3.158:19092 --describe --group hello-group
当然,也可以从 Kafdrop 界面中查看消费者组的信息。
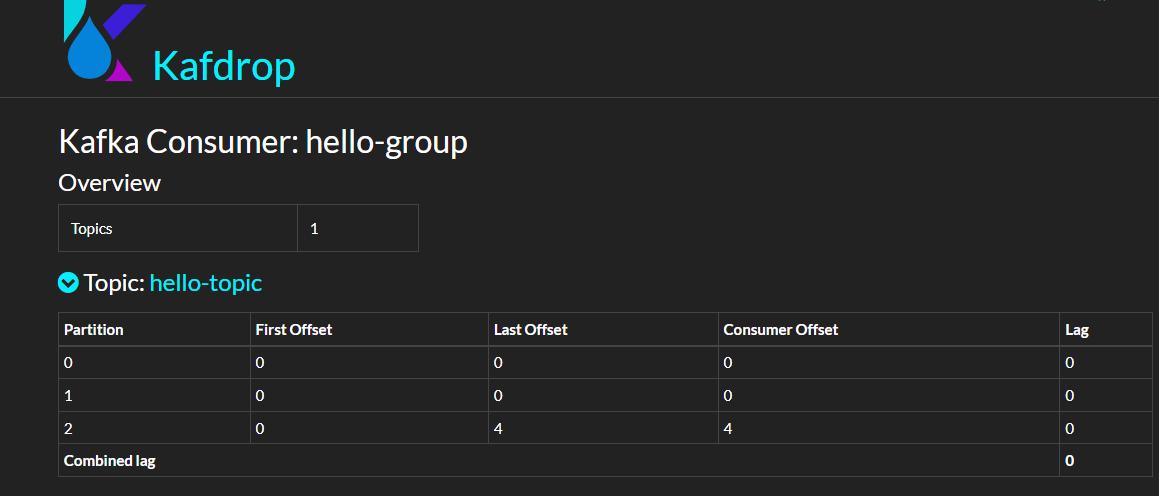
这些参数我们现在可以先跳过。
C# 部分并没有重要的内容要说,代码可以参考:
static async Task Main()
{
var config = new AdminClientConfig
{
BootstrapServers = "192.168.3.158:19092"
};
using (var adminClient = new AdminClientBuilder(config).Build())
{
var groups = adminClient.ListGroups(TimeSpan.FromSeconds(10));
foreach (var item in groups)
{
Console.WriteLine(item.Group);
}
}
}
对于消费者组来说,我们需要关注以下参数:
-
state:消费者组的状态; -
members:消费者组成员; -
offsets: ACK 偏移量;
修改配置
可以使用 kafka-configs 工具设置、描述或删除主题属性。
查看主题属性描述:
kafka-configs --bootstrap-server [HOST:PORT] --entity-type topics --entity-name [TOPIC] --describekafka-configs --bootstrap-server 192.168.3.158:19092 --entity-type topics --entity-name hello-topic --describe
使用 --alter 参数后,可以添加、修改或删除主题属性,命令格式:
kafka-configs --bootstrap-server [HOST:PORT] --entity-type topics --entity-name [TOPIC] --alter --add-config [PROPERTY NAME]=[VALUE]kafka-configs --bootstrap-server [HOST:PORT] --entity-type topics --entity-name [TOPIC] --alter --delete-config [PROPERTY_NAME]例如 Kafka 默认限制发送的消息最大为 1MB,为了修改这个限制,可以使用以下命令:
kafka-configs --bootstrap-server 192.168.3.158:19092 --entity-type topics --entity-name hello-topic --alter --add-config 'max.message.bytes=1048576'
其中还有很多参数,请参考:
https://kafka.apache.org/10/documentation.html#topicconfigs
此外,我们还可以通过 kafka-configs 查看 Broker 的配置:
kafka-configs --bootstrap-server 192.168.3.158:19092 --describe --broker 13, Kafka .NET 基础
在第一章中,笔者介绍了如何部署 Kafka;在第二章中,笔者介绍了 Kafka 的一些基础知识;在本章中,笔者将介绍如何使用 C# 编写程序连接 kafka,完成生产和消费过程。
在第二章的时候,我们已经使用到了 confluent-kafka-dotnet ,通过 confluent-kafka-dotnet 编写代码调用 Kafka 的接口,去管理主题。
confluent-kafka-dotnet 其底层使用了一个 C 语言编写的库 librdkafka,其它语言编写的 Kafka 客户端库也是基于 librdkafka 的,基于 librdkafka 开发客户端库,官方可以统一维护底层库,不同的编程语言可以复用代码,还可以利用 C 语言编写的库提升性能。
此外,因为不同的语言都使用了相同的底层库,也使用了相同的接口,因此其编写的客户端库接口看起来也会十分接近。大多数情况下,Java 和 C# 使用 Kafka 的代码是比较相近的。
接着说一下 confluent-kafka-dotnet,Github 仓库中对这个库的其中一个特点介绍是:
- High performance : confluent-kafka-dotnet 是一个轻量级的程序包装器,它包含了一个精心调优的 C 语言写的 librdkafka 库。
Library dkafka 是 Apache Kafka 协议的 C 库实现,提供了 Producer、 Consumer 和 Admin 客户端。它的设计考虑到信息传递的可靠性和高性能,目前的性能超过 100万条消息/秒 的生产和 300万条消息/秒 的消费能力(原话是:current figures exceed 1 million msgs/second for the producer and 3 million msgs/second for the consumer)。
现在,这么牛逼的东西,到 nuget 直接搜索 Confluent.Kafka 即可使用。
回归正题,下面笔者将会介绍如果使用 C# 编写生产者、消费者程序。在本章中,我们只需要学会怎么用就行,大概了解过程,而不必深究参数配置,也不必细究代码的功能或作用,在后面的章节中,笔者会详细介绍的。
生产者
编写生产者程序大概可以分为两步,第一步是定义 ProducerConfig 配置,里面是关于生产者的各种配置,例如 Broker 地址、发布消息重试次数、缓冲区大小等;第二步是定义发布消息的过程。例如要发布什么内容、如何记录错误消息、如何拦截异常、自定义消息分区等。
下面是生产者代码的示例:
using Confluent.Kafka;
using System.Net;
public class Program
{
static void Main()
{
var config = new ProducerConfig
{
BootstrapServers = "host1:9092",
...
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
...
}
}
}如果要将消息推送到 Kafka,那么代码是这样写的:
var result = await producer.ProduceAsync("weblog", new Message<Null, string> { Value="a log message" });
Value就是消息的内容。其实一条消息的结构比较复杂的,除了 Value ,还有 Key 和各种元数据,这个在后面的章节中我们再讨论。
下面是发布一条消息的实际代码示例:
using Confluent.Kafka;
using System.Net;
public class Program
{
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
var result = await producer.ProduceAsync("weblog", new Message<Null, string> { Value = "a log message" });
}
}
}运行这段代码后,可以打开 kafdrop 面板查看主题信息。
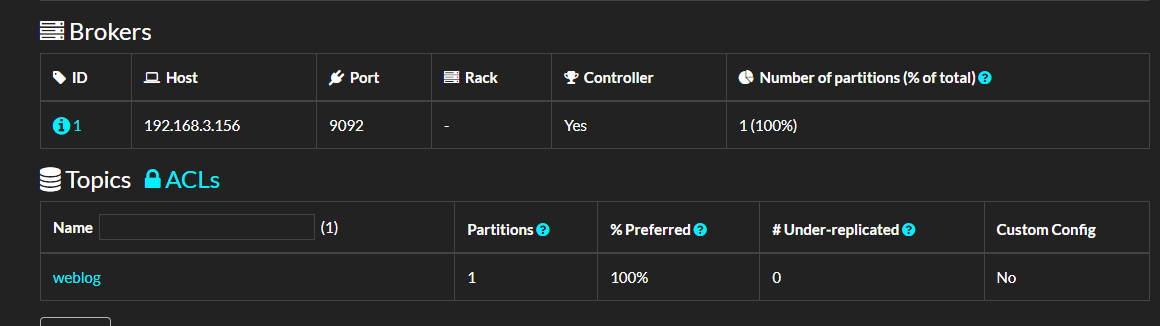
如果我们断点调试 ProduceAsync 后的内容,可以看到有比较多的信息,例如:
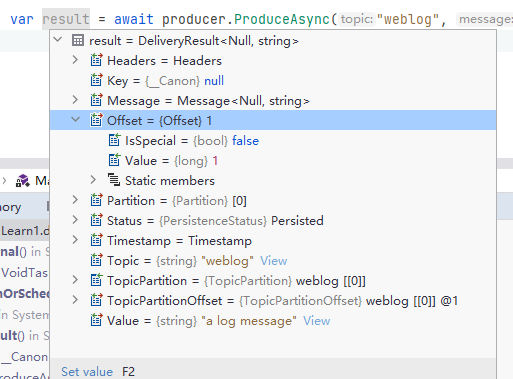
这些信息记录了当前消息是否被 Broker 接收并确认(ACK),该条消息被推送到哪个 Broker 的哪个分区中,消息偏移量数值又是什么。
当然,这里暂时不需要关注这个。
批量生产
这一节中,我们来了解如何通过代码批量推送消息到 Broker。
下面是代码示例:
using Confluent.Kafka;
using System.Net;
public class Program
{
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int i = 0; i < 10; ++i)
{
producer.Produce("my-topic", new Message<Null, string> { Value = i.ToString() }, handler);
}
}
// 帮忙程序自动退出
Console.ReadKey();
}
public static void handler(DeliveryReport<Null, string> r)
{
Console.WriteLine(!r.Error.IsError
? $"Delivered message to {r.TopicPartitionOffset}"
: $"Delivery Error: {r.Error.Reason}");
}
}
可以看到,这里批量推送消息使用了 Produce,而之前我们使用的异步代码用了 ProduceAsync。
其实两者都是异步的,但是 Product 方法更直接地映射到底层的 librdkafka API,能够利用 librdkafka 中高性能的接口批量推送消息。而 ProduceAsync 则是 C# 实现的异步,相对来说Product 的开销小一些,但是 ProduceAsync 仍然非常高性能——在典型的硬件上每秒能够产生数十万条消息
如果说最最直观的差异,那么就是两者的返回结果。
从定义来看:
Task<DeliveryResult<TKey, TValue>> ProduceAsync(string topic, Message<TKey, TValue> message, ...);
void Produce(string topic, Message<TKey, TValue> message, Action<DeliveryReport<TKey, TValue>> deliveryHandler = null);ProduceAsync 可以直接获得 Task,然后通过等待 Task 获取响应结果。
而 Produce 并不能直接获得结果,而是通过回调方式获取推送结果,由 librdkafka 执行回调。
由于 Produce 是框架底层异步的,但是没有 Task,所以不能 await ,为了避免在批量消息处理完成之前,producer 生命周期结束了,所以需要使用 producer.Flush(TimeSpan.FromSeconds(10)) 这样的代码等待批量消息完成推送。
调用 Flush 方法可使所有缓冲记录立即可用于发送,并在与这些记录关联的请求完成时发生阻塞。
Flush 有两个重载:
int Flush(TimeSpan timeout);
void Flush(CancellationToken cancellationToken = default(CancellationToken));int Flush() 会等待指定的时间,如果时间到了,队列中的消息只发送一部分,那么会返回没成功发送的消息数量。
示例代码如下:
using Confluent.Kafka;
using System.Net;
public class Program
{
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int i = 0; i < 10; ++i)
{
producer.Produce("my-topic", new Message<Null, string> { Value = i.ToString() }, handler);
}
// 只等待 10s
var count = producer.Flush(TimeSpan.FromSeconds(10));
// 或者使用
// void Flush(CancellationToken cancellationToken = default(CancellationToken));
}
// 不让程序自动退出
Console.ReadKey();
}
public static void handler(DeliveryReport<Null, string> r)
{
Console.WriteLine(!r.Error.IsError
? $"Delivered message to {r.TopicPartitionOffset}"
: $"Delivery Error: {r.Error.Reason}");
}
}如果将 Kafka 服务停止,客户端肯定是不能推送消息的,那么我们在使用批量推送代码时会有什么现象呢?
这里可以停止所有 Broker 或者给 BootstrapServers 参数设置一个错误的地址,然后启动程序,会发现 producer.Flush(TimeSpan.FromSeconds(10)); 会等待 10s,但是此时 handler 不会起效。
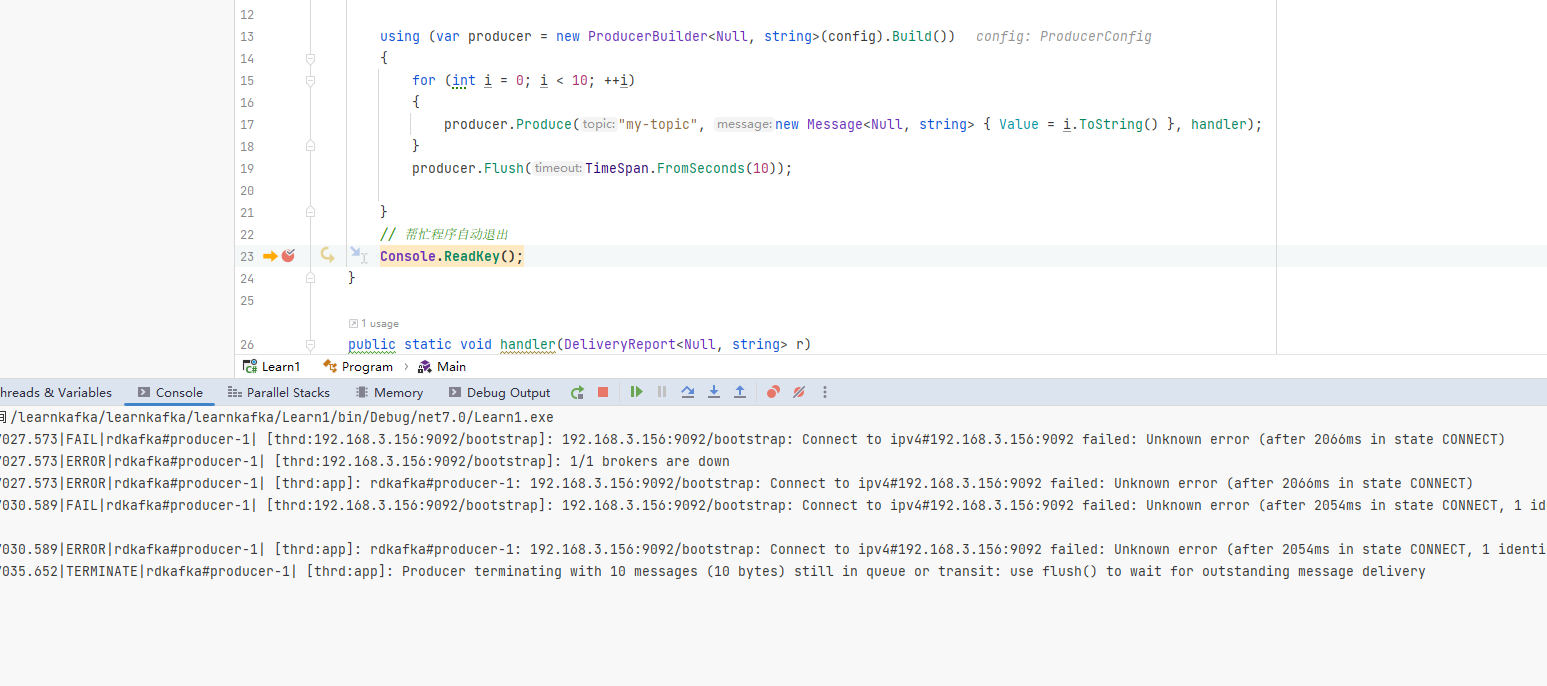
可以看到,如果使用批量消息,需要注意使用 Flush,即使连接不上 Broker,程序也不会报错。
所以我们使用批量消息时,一定要注意与 Broker 的连接状态,以及处理 Flush 返回的失败数量。
var result = producer.Flush(TimeSpan.FromSeconds(10));
Console.WriteLine(result);
使用 Tasks.WhenAll
前面提到了使用 Produce 方法来批量推送消息,除了框架本身的批量提交,我们也可以利用 Tasks.WhenAll 来实现批量提交获取返回结果,不过性能并没有 produce - Flush 好。
示例代码如下:
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
List<Task> tasks = new();
for (int i = 0; i < 10; ++i)
{
var task = producer.ProduceAsync("my-topic", new Message<Null, string> { Value = i.ToString() });
tasks.Add(task);
}
await Task.WhenAll(tasks.ToArray());
}如何进行性能测试
produce - Flush 的性能到底有多好呢?
我们可以使用 BenchmarkDotNet 做性能测试,来评估推送不同消息数量时,消耗的时间和内存。由于不同服务器的 CPU、内存、磁盘速度,以及客户端与服务器之间的网络带宽、时延都是影响消息吞吐量的重要因素,因此有必要编写代码来进行性能测试,来评估客户端以及服务器需要多高的性能来运行程序。
示例代码如下:
using Confluent.Kafka;
using System.Net;
using System.Security.Cryptography;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using BenchmarkDotNet.Jobs;
public class Program
{
static void Main()
{
var summary = BenchmarkRunner.Run<KafkaProduce>();
}
}
[SimpleJob(RuntimeMoniker.Net70)]
[SimpleJob(RuntimeMoniker.NativeAot70)]
[RPlotExporter]
public class KafkaProduce
{
// 每批消息数量
[Params(1000, 10000,100000)]
public int N;
private ProducerConfig _config;
[GlobalSetup]
public void Setup()
{
_config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
}
[Benchmark]
public async Task UseAsync()
{
using (var producer = new ProducerBuilder<Null, string>(_config).Build())
{
List<Task> tasks = new();
for (int i = 0; i < N; ++i)
{
var task = producer.ProduceAsync("ben1-topic", new Message<Null, string> { Value = i.ToString() });
tasks.Add(task);
}
await Task.WhenAll(tasks);
}
}
[Benchmark]
public void UseLibrd()
{
using (var producer = new ProducerBuilder<Null, string>(_config).Build())
{
for (int i = 0; i < N; ++i)
{
producer.Produce("ben2-topic", new Message<Null, string> { Value = i.ToString() }, null);
}
producer.Flush(TimeSpan.FromSeconds(60));
}
}
}在示例代码中,笔者除了记录时间速度外,也开启了 GC 记录。
Ping 服务器的结果以及 BenchmarkDotNet 性能测试结果如下:
正在 Ping 192.168.3.156 具有 32 字节的数据:
来自 192.168.3.156 的回复: 字节=32 时间=1ms TTL=64
来自 192.168.3.156 的回复: 字节=32 时间=2ms TTL=64
来自 192.168.3.156 的回复: 字节=32 时间=2ms TTL=64
来自 192.168.3.156 的回复: 字节=32 时间=1ms TTL=64| Method | Job | Runtime | N | Mean | Error | StdDev | Gen0 | Gen1 | Gen2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|---|
| UseAsync | .NET 7.0 | .NET 7.0 | 1000 | 125.1 ms | 2.21 ms | 2.17 ms | - | - | - | 1055.43 KB |
| UseLibrd | .NET 7.0 | .NET 7.0 | 1000 | 124.7 ms | 2.26 ms | 2.12 ms | - | - | - | 359.18 KB |
| UseAsync | NativeAOT 7.0 | NativeAOT 7.0 | 1000 | 124.8 ms | 1.83 ms | 1.62 ms | - | - | - | 1055.43 KB |
| UseLibrd | NativeAOT 7.0 | NativeAOT 7.0 | 1000 | 125.1 ms | 1.76 ms | 1.64 ms | - | - | - | 359.18 KB |
| UseAsync | .NET 7.0 | .NET 7.0 | 10000 | 143.9 ms | 3.70 ms | 10.86 ms | 1250.0000 | 750.0000 | 250.0000 | 10577.22 KB |
| UseLibrd | .NET 7.0 | .NET 7.0 | 10000 | 140.6 ms | 2.74 ms | 4.80 ms | 250.0000 | - | - | 3523.29 KB |
| UseAsync | NativeAOT 7.0 | NativeAOT 7.0 | 10000 | 145.7 ms | 3.25 ms | 9.59 ms | 1250.0000 | 750.0000 | 250.0000 | 10577.22 KB |
| UseLibrd | NativeAOT 7.0 | NativeAOT 7.0 | 10000 | 140.6 ms | 2.78 ms | 5.56 ms | 250.0000 | - | - | 3523.29 KB |
| UseAsync | .NET 7.0 | .NET 7.0 | 100000 | 407.3 ms | 7.17 ms | 9.58 ms | 13000.0000 | 7000.0000 | 2000.0000 | 105185.91 KB |
| UseLibrd | .NET 7.0 | .NET 7.0 | 100000 | 259.7 ms | 5.72 ms | 16.78 ms | 4000.0000 | - | - | 35164.82 KB |
| UseAsync | NativeAOT 7.0 | NativeAOT 7.0 | 100000 | 419.8 ms | 8.31 ms | 13.19 ms | 14000.0000 | 8000.0000 | 2000.0000 | 105194.3 KB |
| UseLibrd | NativeAOT 7.0 | NativeAOT 7.0 | 100000 | 255.3 ms | 6.31 ms | 18.62 ms | 4000.0000 | - | - | 35164.72 KB |
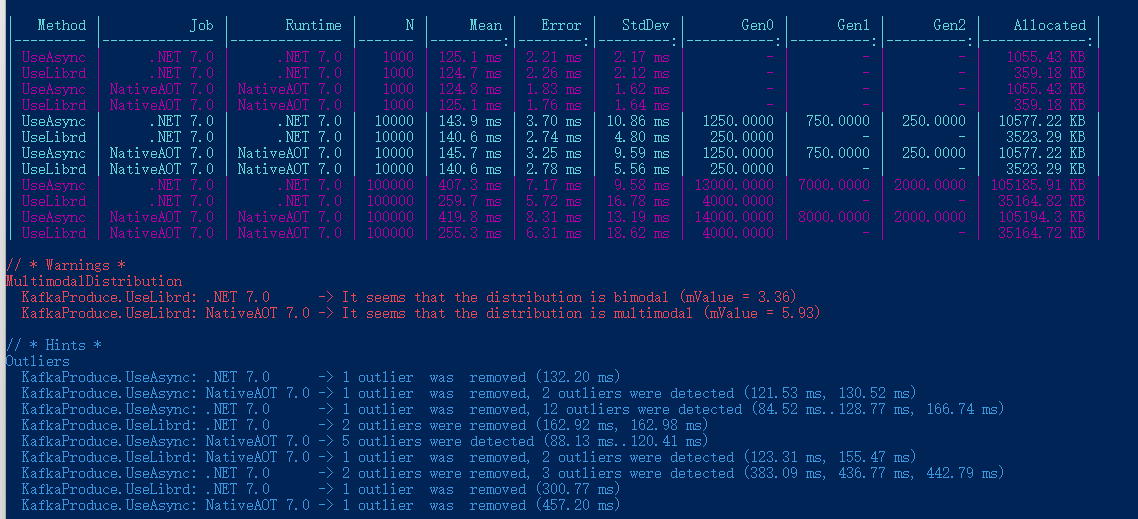
可以看到使用了 librdkafka 批量推送,比使用 Task.WhenAll 性能要好一些,特别是消息数量比较大的情况下。
不过这个性能测试的结果意义也不大,主要是让读者了解如何使用 BenchmarkDotNet 进行性能测试,客户端推送消息到 Broker,能够实现每秒多大的负载,以此评估在当前环境下可以承载多大的流量。
消费
生产消息后,接着编写消费者程序处理消息,消费的代码分为 ConsumerConfig 配置和消费两步,其示例代码如下:
using System.Collections.Generic;
using Confluent.Kafka;
...
var config = new ConsumerConfig
{
// 这些配置后面的章节中笔者会介绍,这里跳过。
BootstrapServers = "host1:9092,host2:9092",
GroupId = "foo",
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
...
}消费者配置默认会自动提交确认(ACK),所以消费后不需要编写代码确认消息,所以笔者编写的消费者示例代码如下:
using Confluent.Kafka;
using System.Net;
public class Program
{
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.156:9092",
GroupId = "test1",
AutoOffsetReset = AutoOffsetReset.Earliest
};
CancellationTokenSource source = new CancellationTokenSource();
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
// 订阅主题
consumer.Subscribe("my-topic");
// 循环消费
while (!source.IsCancellationRequested)
{
var consumeResult = consumer.Consume(source.Token);
Console.WriteLine(consumeResult.Message.Value);
}
consumer.Close();
}
}
}在本章中,关于 Kafka .NET 的基础就到这里,接下来笔者会详细讲解生产者和消费者的代码编写方法以及各种参数配置的使用方法。
4,生产者
在第三章中,我们学习到了 Kafka C# 客户端的一些使用方法,学习了如何编写生产者程序。
在本章中,笔者将会详细介绍生产者程序的参数配置、接口使用方法,以便在项目中更加好地应用 Kafka,以及应对可能发生的故障。
下图是一个生产者推送消息的流程:
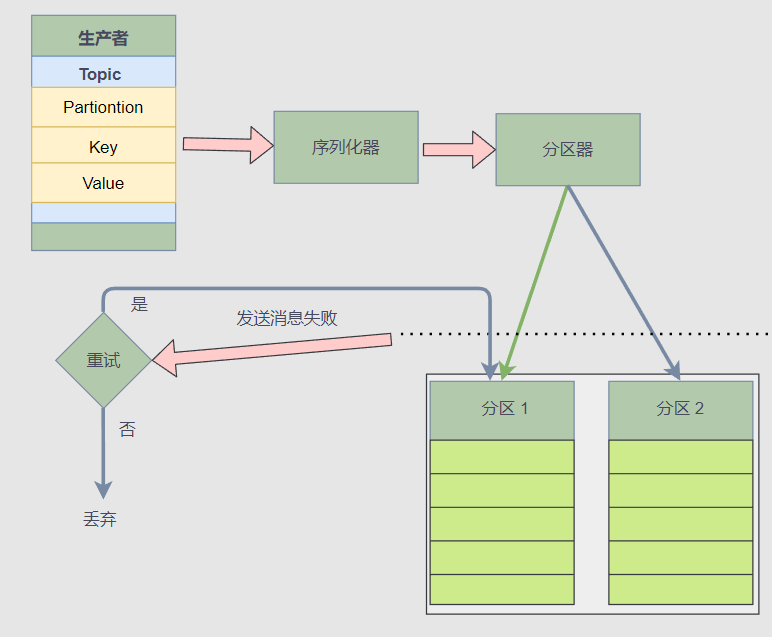
使用客户端库编写生产者是比较简单的,但是消息推送过程是比较复杂的,从上图中可以看到生产者推送消息时,客户端库会先用序列化器将消息序列化为二进制,然后通过分区器算出 Topic 的消息需要推送到哪个 Broker 、哪个分区中 。
接着,如果推送消息失败,那么客户端库还要确认是否重试,重试次数、时间间隔等。
所以说,推送消息虽然很简单,但是怎么处理故障,确保消息不会丢失,还有生产者的配置,这些都需要开发者根据场景考虑,设计合理的生产者程序逻辑。
就 “避免消息丢失” 这个话题来说,除了生产者需要关注消息是否已经推送到 Broker,还要关注 leader 副本是否及时与 follwer 副本同步。否则即使客户端已经将消息推送到 Broker,Broker 的 leader 还没有同步最新的消息到 follwer 副本就挂了,那么此条消息还是会丢失的,所以客户端还需要设置合理的 ACK。
说明了消息会不会丢失,不仅跟生产者的状态有关,还跟 Broker 状态有关。
下面笔者将详细介绍生产者推送消息时,一些日常开发中会遇到的配置以及细节。
连接 Broker
生产者连接 Broker,需要定义 ProducerConfig ,首先是 BootstrapServers 属性,填写所有 Broker 的服务器地址,格式如下:
host1:9092,host2:9092,...using Confluent.Kafka;
using System.Net;
public class Program
{
static void Main()
{
var config = new ProducerConfig
{
BootstrapServers = "host1:9092",
...
};
... ...
}
}如果需要通过加密连接,ProducerConfig 可以参考下面的代码:
var config = new ProducerConfig
{
BootstrapServers = "<your-IP-port-pairs>",
SslCaLocation = "/Path-to/cluster-ca-certificate.pem",
SecurityProtocol = SecurityProtocol.SaslSsl,
SaslMechanism = SaslMechanism.ScramSha256,
SaslUsername = "ickafka",
SaslPassword = "yourpassword",
};客户端并不需要填写所有 Broker 的地址,因为生产者在建立连接之后,便可以从已连接的 Broker 中查找集群信息,获取到所有 Broker 地址。但是建议至少填写两个 Broker 地址,因为如果第一个 Broker 地址不可用,客户端还可以从其它 Broker 中获取当前集群的信息,不至于完全连不上服务器。
例如服务器有三个 Broker,客户端只填写了一个 BootstrapServers 地址,然后客户端推送消息,这些消息还是会被自动推送到对应的分区中的。
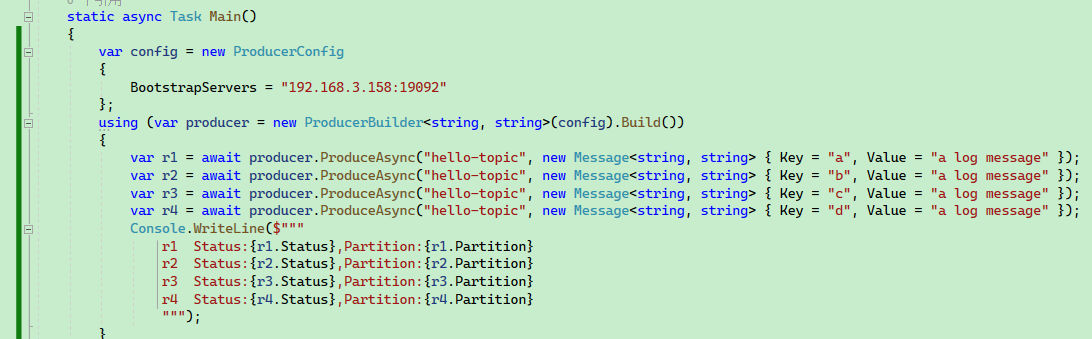
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092"
};
using (var producer = new ProducerBuilder<string, string>(config).Build())
{
var r1 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "a", Value = "a log message" });
var r2 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "b", Value = "a log message" });
var r3 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "c", Value = "a log message" });
var r4 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "d", Value = "a log message" });
Console.WriteLine($"""
r1 Status:{r1.Status},Partition:{r1.Partition}
r2 Status:{r2.Status},Partition:{r2.Partition}
r3 Status:{r3.Status},Partition:{r3.Partition}
r4 Status:{r4.Status},Partition:{r4.Partition}
""");
}
}
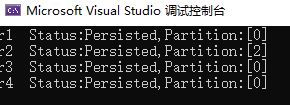
可以看到,即使只填写一个 Broker,消息依然可以被正确分区。
Key 分区
本节会介绍 Key 的使用方法。
提前创建了一个 hello-topic 主题,并设置了 3 个分区,3 个副本,其创建命令如下所示:
kafka-topics --create --bootstrap-server 192.168.3.158:19092 \
--replication-factor 23 \
--partitions 3 \
--topic hello-topic在前面的章节中,笔者介绍了如何编写生产者以及推送消息,但是代码比较简单,只设置了 Value。
new Message<Null, string> { Value = "a log message" }然后是关于分区的问题。
首先是分区器,分区器决定将当前消息推送到哪个分区,而分区器位于客户端。
推送消息时,我们可以在客户端显示指定将消息推送到哪个分区,如果没有显式指定分区位置,那么就会由分区器基于 Key 决定将消息推送到哪个分区中。
如果一个消息没有设置 Key,即 Key 是 null,那么这些没有 Key 的消息,会被均衡分布到各个分区上,按照 p0 => p1 => p2 => p0 这样的顺序推送消息。
接下来,笔者介绍 Key 使用。
创建主题后,我们来看一下 C# 代码中的生产者构造器以及 Message<TKey, TValue> 的定义。
ProducerBuilder<TKey, TValue> 和 Message<TKey, TValue> 两者都具有相同的泛型参数。
public class ProducerBuilder<TKey, TValue> public class Message<TKey, TValue> : MessageMetadata
{
//
// 摘要:
// Gets the message key value (possibly null).
public TKey Key { get; set; }
//
// 摘要:
// Gets the message value (possibly null).
public TValue Value { get; set; }
}然后,在编写代码时,我们需要为 Key 和 Value 设置对应的类型。
生产者的代码示例如下:
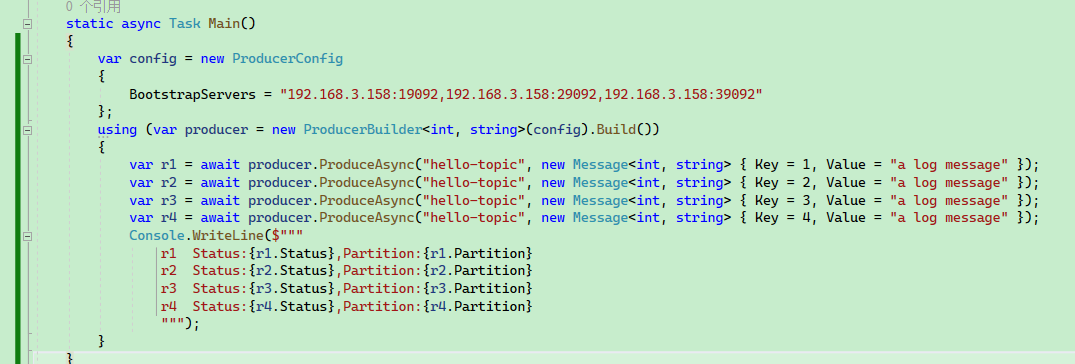
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092"
};
using (var producer = new ProducerBuilder<int, string>(config).Build())
{
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 1, Value = "a log message" });
var r2 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 2, Value = "a log message" });
var r3 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 3, Value = "a log message" });
var r4 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 4, Value = "a log message" });
Console.WriteLine($"""
r1 Status:{r1.Status},Partition:{r1.Partition}
r2 Status:{r2.Status},Partition:{r2.Partition}
r3 Status:{r3.Status},Partition:{r3.Partition}
r4 Status:{r4.Status},Partition:{r4.Partition}
""");
}
}
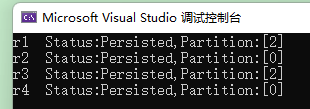
响应结果中可以看到消息被推送到哪个分区中。
接下来还有一个疑问,如果向 Broker 推送具有相同值的 Key,那么会覆盖之前的消息?
正常情况下应该不会。
主题有个
cleanup.policy参数,设置日志保留策略,如果保留策略是compact(压实),那么只为每个 key 保留最新的值。
下面我们可以来做使用,首先向 Broker 推送 20 条消息,一共有 10 个 Key,两两重复。
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
};
using (var producer = new ProducerBuilder<string, string>(config)
.Build())
{
int i = 1;
while (i <= 10)
{
var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "1" });
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
i++;
}
i = 1;
while (i <= 10)
{
var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "2" });
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
i++;
}
}
}或者:
int i = 1; while (i <= 10) { var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "1" }); Console.WriteLine($"id:{r1.Key},status:{r1.Status}"); var r2 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "2" }); Console.WriteLine($"id:{r1.Key},status:{r2.Status}"); i++; }
然后打开 kafdrop,查看每个分区的消息数量,。
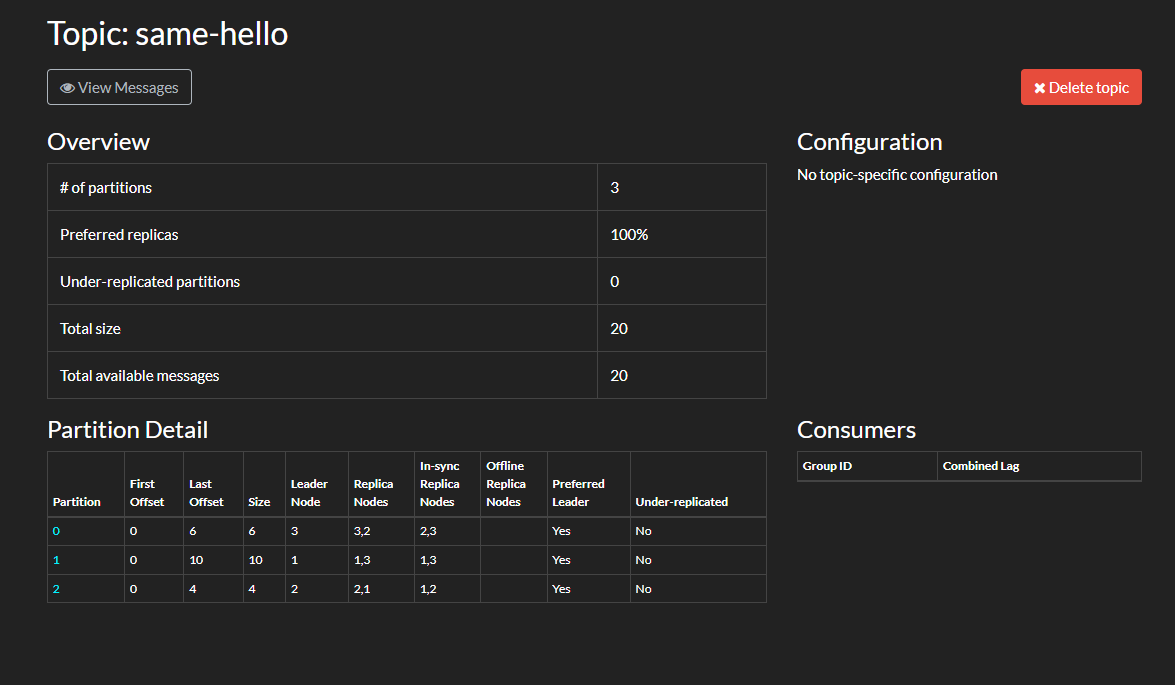
可以看到,消息数量总数为 20 条,虽然部分 key 重复,但是消息还在,不会丢失。
接着打开其中一个分区,会发现分区器依然是正常工作,相同的 key 依然会被划分到同一个分区中。
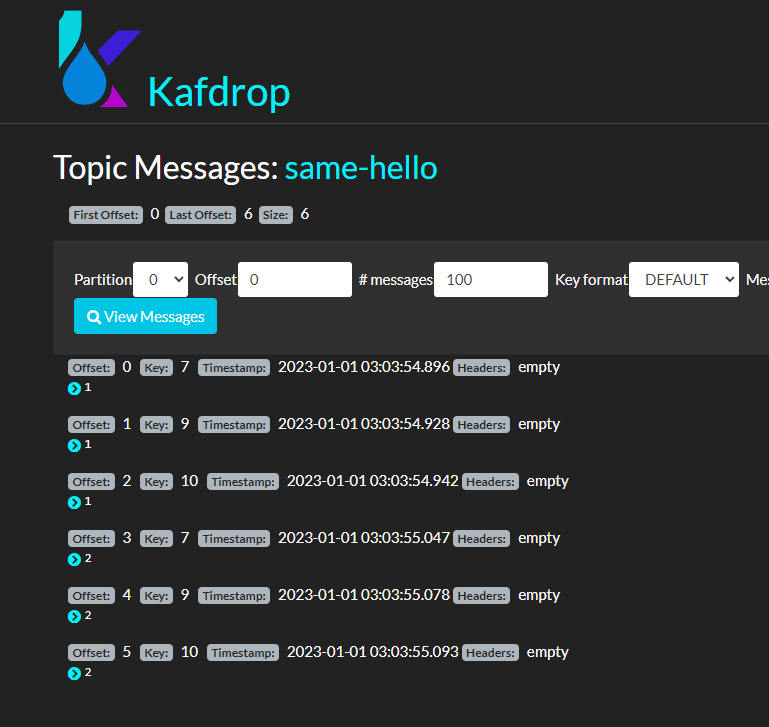
所以我们并不需要担心 Key 为空,以及相同的 Key 覆盖消息。
评估消息发送时间
下面是推送一条消息的步骤。
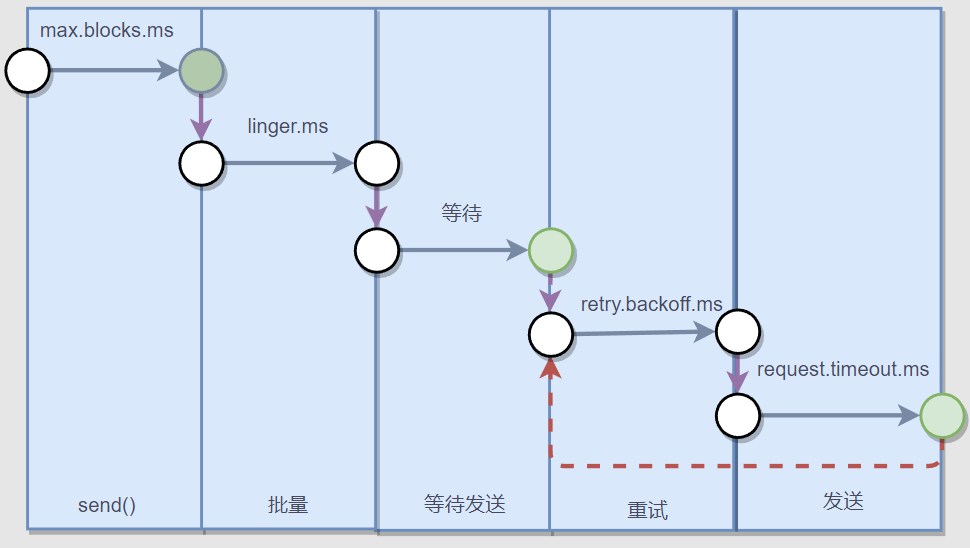
这里的批量指的是缓冲区。
客户端库里面设计到了好几个时间配置,在《Kafka权威指南(第2版)》,给出了一个时间公式:
delivery.timeout.ms >= linger.ms + retry.backoff.ms + request.timeout.msdelivery.timeout.ms 设置将消息放到缓冲区、推送消息到 Broker、获得 Ack、以及重试的总时间不能超过这个范围,否则视为超时。
在 C# 中没有这么详细的时间配置,然后这些时间的配置验证比较麻烦,因此这里笔者只给出简单的说明,详细每个时间配置,读者可以参考 《Kafka权威指南(第2版)》 的 41 页。
生产者配置
本节主要参考文章:
https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f
部分图片来源于此文章。
参考资料还包括 《Kafka权威指南(第2版)》。
本节介绍生产者的以下配置:
acksbootstrap.serversretriesenable.idempotencemax.in.flight.requests.per.connectionbuffer.memorymax.block.mslinger.msbatch.sizecompression.type
查看 ProducerConfig 的源码可以发现,每个属性字段都对应了一个 Kafka 配置项。
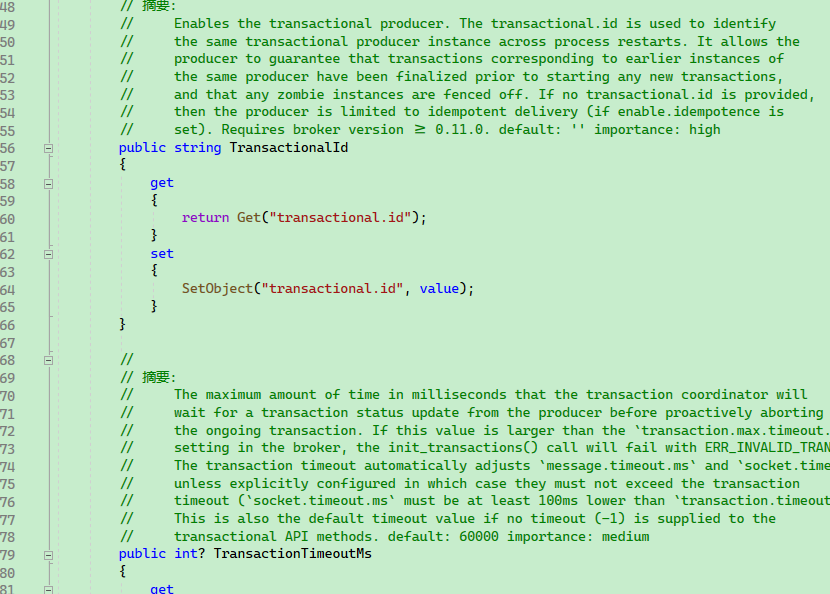
完整的生产者配置文档:https://docs.confluent.io/platform/current/installation/configuration/producer-configs.html#
接下来笔者对日常开发中比较容易用到的配置项进行一一说明。
acks
C# 中对应的枚举如下:
public enum Acks
{
None = 0,
Leader = 1,
All = -1
}使用示例:
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:9092",
Acks = Acks.Leader
};默认值是
Acks.Leader。
acks 指定了生产者推送消息时,需要多少个分区副本全部收到消息的情况下,才会认为消息写入成功。
在默认情况下,在首领副本收到消息后,即可向客户端回应消息已写入成功,这有助于控制发送的消息的持久性。
下面是 akcs 配置的说明:
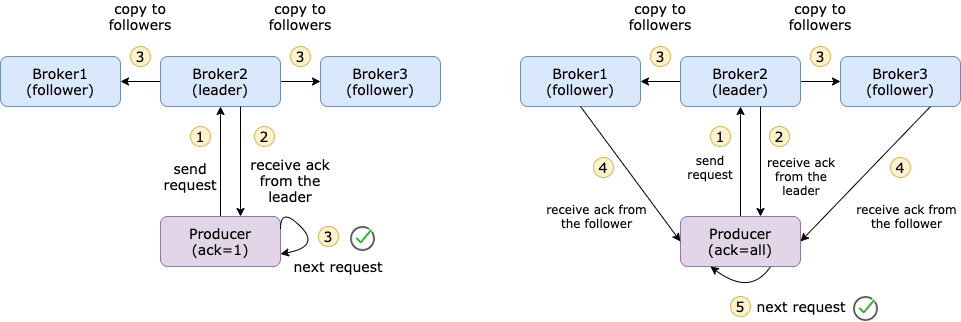
acks=0: 这意味着该记录将立即添加到套接字缓冲区并被视为已发送,如果网络故障或其它原因消息没有推送到 Broker,那么抱歉,这个消息就会被丢弃;acks=1: 只要生产者收到 Leader 副本的确认,它就会将其视为成功的提交。不过在 Leader 副本发生崩溃的情况下,消息还是有可能丢失的;acks=all: 消息提交后必须等待来自该主题的所有副本的确认,它提供了最强大的可用消息持久性,但是耗时会增加。
在第二章和第三章都提到过这个 leader 和 follwer 的情况。
acks 的默认值为 1,这意味着只要生产者从该主题的 Leader 副本收到 ack,它就会将其视为成功的提交并继续下一条消息。
acks= all 将确保生产者从该主题的所有同步副本中获得 acks 才会认为消息已经提交,它提供了最强的消息持久性,但是它也需要较长的时间,从而导致较高的延迟。
下图是 acks=1 和 acks=all 的区别。
acks=all也可以写成acks=-1。
【图源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
bootstrap.servers
前面提到过,这里不再赘述。
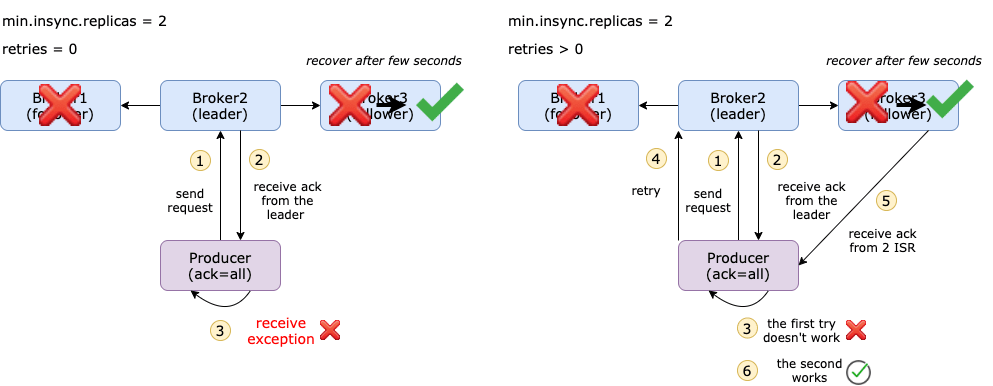
retries
默认情况下,如果消息提交失败,生产者不会重新发送记录,即不会重试,即默认重试次数为 0。
可以通过可以设置 retries = n 让发送失败的消息重试 n 次。
在 C# 中,可以通过 ProducerConfig 的 MessageSendMaxRetries 设置最大重试次数。
public int? MessageSendMaxRetries
{
get
{
return GetInt("message.send.max.retries");
}
set
{
SetObject("message.send.max.retries", value);
}
}
【图源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
另外,还可以设置重试的间隔时间,默认为 100ms。
public int? RetryBackoffMs
{
get
{
return GetInt("retry.backoff.ms");
}
set
{
SetObject("retry.backoff.ms", value);
}
}enable.idempotence
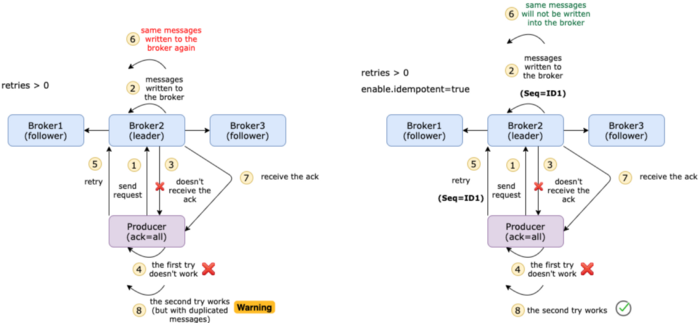
简单地说,幂等性是某些操作在不改变结果的情况下多次应用的性质。当打开时,生产者将确保只有一个记录副本被发布到流。默认值为 false,这意味着生产者可以将消息的副本写入流。要打开幂等函数,请使用下面的命令
enable.idempotent=true幂等生产者被启用时,生产者将给发送的每一条消息都加上一个序列号。
在某些情况下,消息实际上已经提交给所有同步副本,但由于网络问题,代理无法发送回一个 ack (例如,只允许单向通信)。同时,我们设置 retry = 3,然后生成器将重新发送消息3次。这可能导致主题中出现重复消息。
最理想的情况是精确一次语义,即使生产者重新发送消息,使用者也应该只收到相同的消息一次。
它是怎么工作的?消息以批处理方式发送,每个批处理都有一个序号。在代理端,它跟踪每个分区的最大序列号。如果进入一个序列号较小或相等的批处理,代理将不会将该批处理写入主题。通过这种方式,它还可以确保批次的顺序。
【图源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
max.in.flight.requests.per.connection
Connection Kafka Producer Config 表示客户机在阻塞之前在单个连接上发送的未确认请求的最大数量。默认值为5。
如果启用了重试,并且 max.in.flight.requests.per.connect 设置为大于1,则存在消息重新排序的风险。
确保顺序的另一个重要配置是 max.in.flight.requests.per.connect,默认值为5。这表示可以在生产者端缓冲的未确认请求的数量。如果重试次数大于1,第一个请求失败,但第二个请求成功,那么第一个请求将被重试,消息的顺序将错误。
请注意,如果此设置大于1,并且发送失败,则由于重试(即,如果启用了重试) ,存在消息重新排序的风险。
如果没有设置 enable.idempotent=true,但仍希望保持消息的顺序,则应将此设置配置为1。
但是如果已经启用了 enable.idempotent=true,那么就不需要显式定义这个配置。卡夫卡将选择适当的值,正如这里所述。
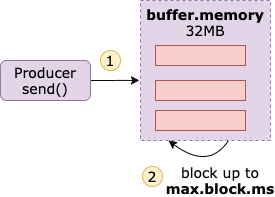
buffer.memory
`buffer.memory 表示生产者可以用来缓冲等待发送到服务器的消息的总内存字节数。
默认值是 32 MB,如果生产者发送记录的速度快于它们传送到服务器的速度,那么缓冲区被耗尽之后,在缓冲区里面的消息减少之前,其它消息需要等待加入缓冲区,此时生产者发送消息就会被阻塞。
另外,有个 max.block.ms 参数可以配置消息等待进入缓冲区的最大时间,默认是 60s,如果消息一直不能进入缓冲区,那么就会抛出异常。
【图源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
另外两个可以使用的配置是 linger.ms 和 batch.size。 linger.ms 是缓冲区批量发送之前的延迟时间,默认值为 0,这意味着即使批量消息中只有 1 条消息,也会立即发送批处理。
可以将 linger.ms 设置大一些,以减少请求数量,一次性将多个消息批量推送,提高吞吐量,但这将导致更多的消息堆积在内存中。
有一个与 linger.ms 等价的配置,即 batch.size,这是单个批处理的最大消息数量。
当满足这两个要求中的任何一个时,批量消息将被发送。
batch.size
Whenever multiple records are sent to the same partition, the producer attempts to batch the records together. This way, the performance of both the client and the server can be improved. batch.size represents the maximum size (in bytes) of a single batch.
每当多条记录被发送到同一个分区时,生产者就会尝试将这些记录批处理在一起。通过这种方式,可以提高客户机和服务器的性能。Size 表示单个批处理的最大大小(以字节为单位)。
Small batch size will make batching irrelevant and will reduce throughput, and a very large batch size will lead to memory wastage as a buffer is usually allocated in anticipation of extra records.
小批量将使批处理无关紧要,并将降低吞吐量,而且非常大的批处理大小将导致内存浪费,因为缓冲区通常是在预期额外记录的情况下分配的。
compression.type
在默认情况下,生产者发送的消息是未经压缩的。这个参数可以被设置为snappy、gzip、lz4或zstd,这指定了消息被发送给broker之前使用哪一种压缩算法。snappy压缩算法由谷歌发明,虽然占用较少的CPU时间,但能提供较好的性能和相当可观的压缩比。如果同时有性能和网络带宽方面的考虑,那么可以使用这种算法。gzip压缩算法通常会占用较多的CPU时间,但提供了更高的压缩比。如果网络带宽比较有限,则可以使用这种算法。使用压缩可以降低网络传输和存储开销,而这些往往是向Kafka发送消息的瓶颈所在。
生产者拦截器
Library dkafka 有一个拦截器 API,但是您需要用 C 编写它们,并且不能轻松地从 C # 代码中共享状态。
https://github.com/confluentinc/confluent-kafka-dotnet/issues/1454
序列化器
有 Key 和 Value 两种序列化器。
.SetKeySerializer(...)
.SetValueSerializer(...)基本上,ApacheKafka 提供了我们可以轻松发布和订阅记录流的能力。因此,我们可以灵活地创建自己的定制序列化程序和反序列化程序,这有助于使用它传输不同的数据类型。
但是,将对象转换为字节流以进行传输的过程称为序列化(Serialization)。尽管如此,ApacheKafka 在其队列中存储并传输这些字节数组。
然而,序列化的对立面是反序列化。在这里,我们将数组的字节转换为所需的数据类型。但是,确保 Kafka 只为少数几种数据类型提供序列化器和反序列化器,例如
- String 绳子
- Long 很长
- Double 双倍
- Integer 整数
- Bytes 字节
换句话说,在将整个消息传输给代理之前,让生产者知道如何使用序列化器将消息转换为字节数组。类似地,要将字节数组转换回对象,使用者使用反序列化器。
在 C# 中,Serializers 定义了几个默认的序列化器。
Utf8
Null
Int64
Int32
Single
Double
ByteArray由于 byte[] 转对应的类型并不复杂,因此这里将部分序列化器的源码显示出来:
private class Utf8Serializer : ISerializer<string>
{
public byte[] Serialize(string data, SerializationContext context)
{
if (data == null)
{
return null;
}
return Encoding.UTF8.GetBytes(data);
}
}
private class NullSerializer : ISerializer<Null>
{
public byte[] Serialize(Null data, SerializationContext context)
{
return null;
}
}
private class Int32Serializer : ISerializer<int>
{
public byte[] Serialize(int data, SerializationContext context)
{
return new byte[4]
{
(byte)(data >> 24),
(byte)(data >> 16),
(byte)(data >> 8),
(byte)data
};
}
}如果需要支持更多类型,则可以继承 ISerializer<T> 来实现。
由于 C# 有泛型,因此在使用 new ProducerBuilder<TKey, TValue> 的时候,会自动从默认的几种序列化器中找到合适的 ISerializer<T> ,如果不是默认的这几种类型,则需要自行实现序列化器。
生产者设置了对应的序列化器,客户端同样可以设置对应的反序列化器,以便能够正确从 Message 中还原对应的结构。
同样,有这几种默认的反序列化器,在 Deserializers 中可以找到,因为生产者、消费者这部分配置是关联相通的,因此后面讲解消费者的时候,就不提及了。
using (var consumer = new ConsumerBuilder<Ignore, string>(config)
.SetKeyDeserializer(Deserializers.Ignore)
.Build())
{
}标头
标头是消息中的元数据,主要目的在于向消息中加入一些数据,例如来源、追踪信息等。
在 C# 中,一个消息的定义如下:
public class MessageMetadata
{
public Timestamp Timestamp { get; set; }
public Headers Headers { get; set; }
}
public class Message<TKey, TValue> : MessageMetadata
{
public TKey Key { get; set; }
public TValue Value { get; set; }
}我们可以通过在消息的 Headers 中加入自定义的消息,其示例如下:
var message = new Message<Null, string>
{
Value = "666",
Headers = new Headers()
{
{ "Level",Encoding.ASCII.GetBytes("Info")},
{ "IP",Encoding.ASCII.GetBytes("192.168.3.66")}
}
};
var result = await producer.ProduceAsync("my-topic", message);生产者处理器
SetStatisticsHandler
SetKeySerializer
SetValueSerializer
SetPartitioner
SetDefaultPartitioner
SetErrorHandler
SetLogHandlerStatistics 统计数据
通过将 statistics.interval.ms 配置属性设置一个固定值,library dkafka 可以配置为以固定的时间间隔发出内部指标,也就是说可以定期获取到 Kafka 集群的所有信息。
首先修改生产者配置中的 StatisticsIntervalMs 属性
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
StatisticsIntervalMs = 1000,
};然后使用 SetStatisticsHandler 设置处理器,其委托定义为:Action<IProducer<TKey, TValue>, string> statisticsHandler。
委托中一共有两个参数变量,前者 IProducer<TKey, TValue> 就是当前生产者实例,后者 string 是 Json 文本,记录了当前所有 Broker 的所有详细信息。
由于表示的内容很多,读者可以参考:
https://github.com/confluentinc/librdkafka/blob/master/STATISTICS.md
使用实例如下:
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
StatisticsIntervalMs = 1000,
};
using (var producer = new ProducerBuilder<int, string>(config)
.SetStatisticsHandler((producer, json) =>
{
Console.WriteLine(producer.Name);
Console.WriteLine(json);
})
.Build())
{
int i = 100;
while (true)
{
Thread.Sleep(1000);
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = i, Value = "a log message" });
i++;
}
}
}SetPartitioner、SetDefaultPartitioner
由于指定生产者在向 Broker 推送消息时,消息向指定分区写入。
SetPartitioner 的定义如下:
SetPartitioner:
SetPartitioner(string topic, PartitionerDelegate partitioner)
-- PartitionerDelegate:
Partition PartitionerDelegate(string topic, int partitionCount, ReadOnlySpan<byte> keyData, bool keyIsNull);SetDefaultPartitioner 的定义如下:
SetDefaultPartitioner(PartitionerDelegate partitioner)SetPartitioner、SetDefaultPartitioner 的区别在于 SetPartitioner 可以对指定的 topic 有效,SetDefaultPartitioner 则对当前生产者中的所有 topic 有效。
代码示例如下:
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
StatisticsIntervalMs = 1000,
};
using (var producer = new ProducerBuilder<int, string>(config)
.SetPartitioner("hello-topic", (topic, partitionCount, keyData, keyIsNull) =>
{
return new Partition(0);
})
.SetDefaultPartitioner((topic, partitionCount, keyData, keyIsNull) =>
{
return new Partition(0);
})
.Build())
{
int i = 100;
while (true)
{
Thread.Sleep(1000);
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = i, Value = "a log message" });
i++;
}
}
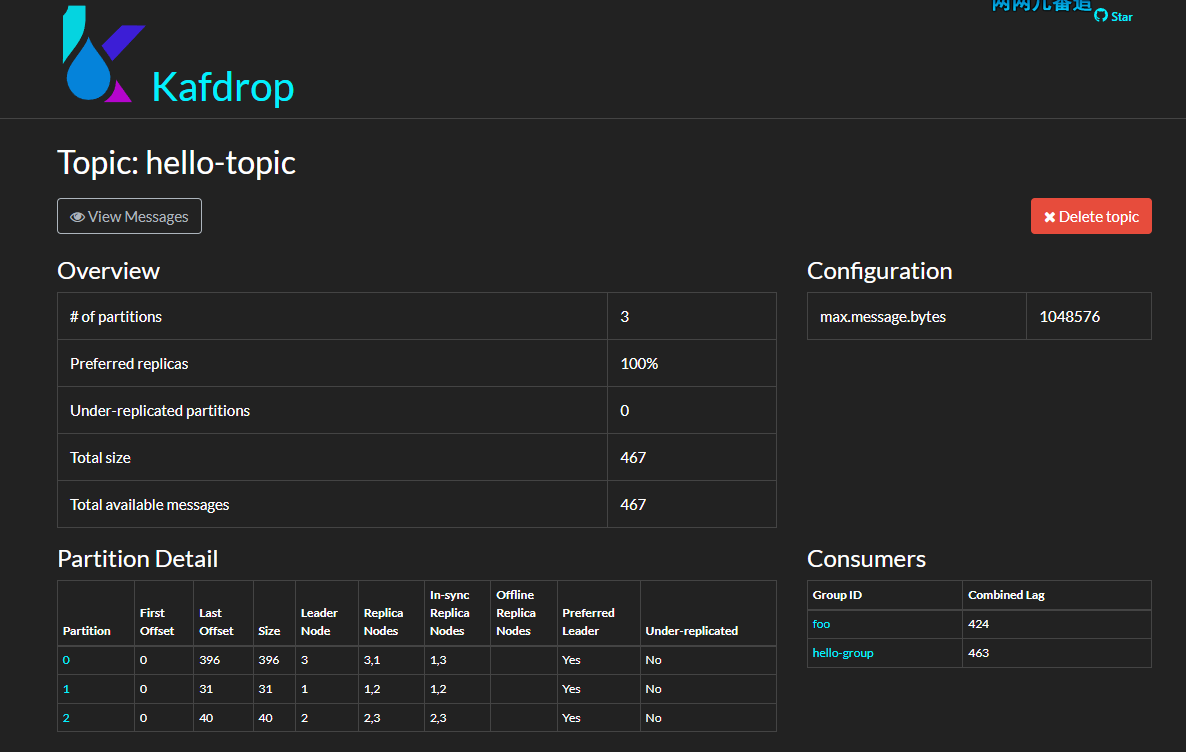
}可以看到,现在所有 topic 都向指定的分区 0 写入:
剩下的两个 SetErrorHandler、SetLogHandler,用于记录错误日志、普通日志,读者可根据其它资料自行实验,这里笔者就不再赘述了。
using (var producer = new ProducerBuilder<int, string>(config)
.SetErrorHandler((p, err) =>
{
Console.WriteLine($"Producer Name:{p.Name},error:{err}");
})
.SetLogHandler((p, log) =>
{
Console.WriteLine($"Producer Name:{p.Name},log messagge:{JsonSerializer.Serialize(log)}");
})
.Build())
{
}异常处理和重试
生产者推送消息有三种发送方式:
-
发送并忘记
-
同步发送
-
异步发送
发送消息时,一般有两种异常情况,一种是可重试异常,例如网络故障、Broker 故障等;另一种是不可重试故障,例如服务端限制了单条消息的最大字节数,但是客户端的消息超过了这个限制,此时会直接抛出异常,而不能重试。
using (var producer = new ProducerBuilder<string, string>(config)
.Build())
{
try
{
var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = "1", Value = "1" });
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
}
catch (ProduceException<string, string> ex)
{
Console.WriteLine($"Produce error,key:[{ex.DeliveryResult.Key}],errot message:[{ex.Error}],trace:[{ex.StackTrace}]");
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}消息发送后会返回 DeliveryResult<TKey, TValue>,其 Status 字段表示了消息的状态,有三种状态。
// 消息持久状态的枚举。
public enum PersistenceStatus
{
// 消息从未传输到 Broker,或者失败,并出现错误,指示未将消息写入日;应用程序重试可能导致排序风险,但不会造成复制风险。
NotPersisted,
// 消息被传输到代理,但是没有收到确认;应用程序重试有排序和复制的风险。
PossiblyPersisted,
// 消息被写入日志并由 Broker 确认。在发生代理故障转移的情况下,应使用 <code>acks='all'</code> 选项使其完全受信任。
Persisted
}在消息发送失败时,客户端可以进行重试,可以设置重试次数和重试间隔,还可以设置是否重新排序。
是否重新排序可能会对业务产生极大的影响。
例如发送顺序为
[A,B,C,D],当客户端发送 A 失败时,如果不允许重新排序,那么客户端会重试 A,A 成功后继续发送[B,C,D],这一过程是阻塞的。如果允许重新排序,那么客户端会在稍候对 A 进行重试,而现在先发送
[B,C,D];这样可能会导致 Broker 收到的消息顺序是[B,C,D,A]。
示例代码如下:
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
// 接收来自所有同步副本的确认
Acks = Acks.All,
// 最大重试次数
MessageSendMaxRetries = 3,
// 重试时间间隔
RetryBackoffMs = 1000,
// 如果不想在重试时对消息重新排序,则设置为 true
EnableIdempotence = true
};
using (var producer = new ProducerBuilder<string, string>(config)
.SetLogHandler((_, message) =>
{
Console.WriteLine($"Facility: {message.Facility}-{message.Level} Message: {message.Message}");
})
.SetErrorHandler((_, e) =>
{
Console.WriteLine($"Error: {e.Reason}. Is Fatal: {e.IsFatal}");
})
.Build())
{
try
{
var result = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = "1", Value = "1" });
Console.WriteLine($"[{result.Key}] 发送状态; {result.Status}");
// 消息没有收到 Broker 的 ACK
if (result.Status != PersistenceStatus.Persisted)
{
// 自动重试失败后,此消息需要手动处理。
}
}
catch (ProduceException<string, string> ex)
{
Console.WriteLine($"Produce error,key:[{ex.DeliveryResult.Key}],errot message:[{ex.Error}],trace:[{ex.StackTrace}]");
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
}Broker 限制速率
在 Kafka 中,生产者、消费者都是客户端,两者都有一个 client.id,消费者还有一个消费者组的概念,但生产者只有 client.id,没有其它标识了。
一般来说,并不需要设定 生产者的 client.id,框架会自动设置,如:
rdkafka#producer-1 var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
StatisticsIntervalMs = 1000,
ClientId = "abcdef"
};新的 client.id:
abcdef#producer-1回归正题,在 Kafka 中,可以根据 client.id ,对生产者或消费者进行限制流量,多个客户端(消费者或生产者)可以用同一个 client.id。或者通过其它认证机制标识客户端身份。
可以通过以下方式表示客户端。
-
user
-
client id
-
user + client id
笔者选择使用最简单的 client.id 做实验。
kafka-configs --alter --bootstrap-server 192.168.3.158:19092 --add-config 'producer_byte_rate=1024,consumer_byte_rate=1024' --entity-type clients --entity-name 'abcdef'限制 1kb/s。
然后编写使用下面的代码测试,会发现推送消息速度变得很慢。
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
StatisticsIntervalMs = 1000,
ClientId = "abcdef"
};
using (var producer = new ProducerBuilder<int, string>(config)
.Build())
{
int i = 1000;
var str = string.Join(",", Enumerable.Range(0, 1024).Select(x => x.ToString("X16")));
while (true)
{
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = i, Value = str });
i++;
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
}
}
}5.消费者
在第四章中的生产者中,介绍了比较多的生产者特性,而消费者很多特性跟生产者是一样的,因此本章简单介绍消费者程序的编写方式和一些问题的解决方法,不再过多介绍消费者的参数。
消费者和消费者组
创建一个消费者时,可以指定这个消费者所属的组(GroupId),如果不指定,Kafka 默认会给其分配一个。
给消费者指定一个消费者组 C 的方式如下:
var config = new ConsumerConfig
{
BootstrapServers = "host1:9092,host2:9092",
GroupId = "C",
AutoOffsetReset = AutoOffsetReset.Earliest
};消费者组是一个很重要的配置。
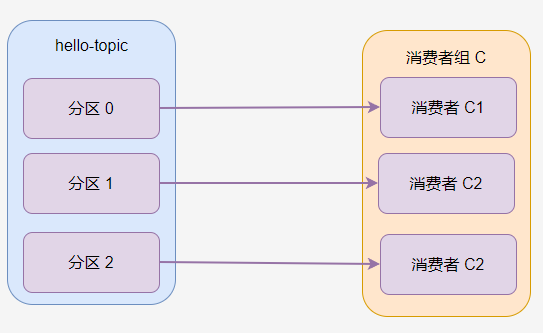
如果一个主题只有一个分区,并且只有一个消费者组,只有一个消费者,那么消费过程如图。
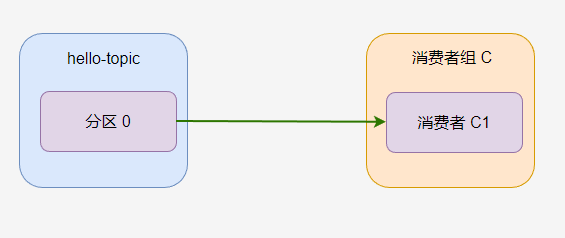
hello-topic 中的所有消息都会被
C-C1消费。
一个分区只能被消费者组中的一个消费者消费!消费者组 C 中,无论有多少个消费者,分区 0 只有一个消费者可以消费。
如果 C1 消费者程序挂了,C2 消费者开始消费,那么默认是从 C1 消费者上次消费的位置开始消费。
如果一个主题有多个消费者组,那么每个消费者组都可以消费这个分区的所有消息。
每个消费者组都有自己的消费标记。
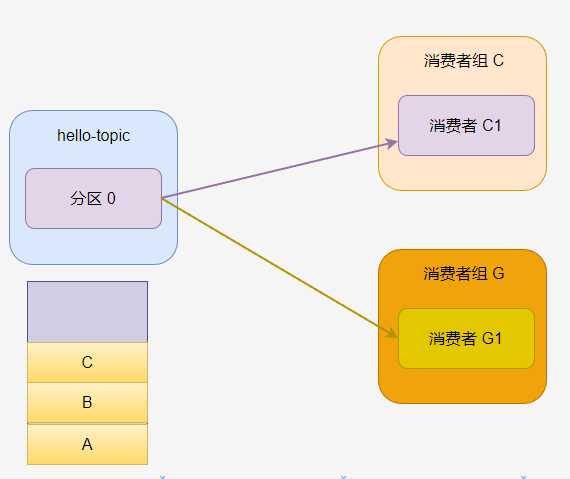
如果一个消费者组中有多个消费者,那么一个分区只会分配给其中一个消费者。
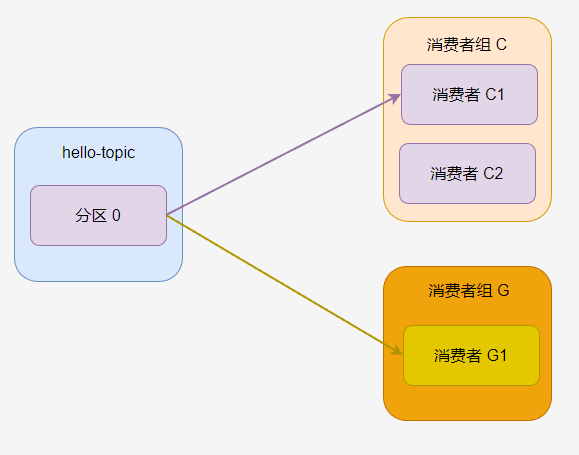
此时 C2 一直没有活干。
如果主题有多个分区,那么分区会被一定规则分配给消费者组的消费者,例如下图中,消费者 C1 被分配到 分区 0 和分区 2,消费者 C2 分到 分区 1。
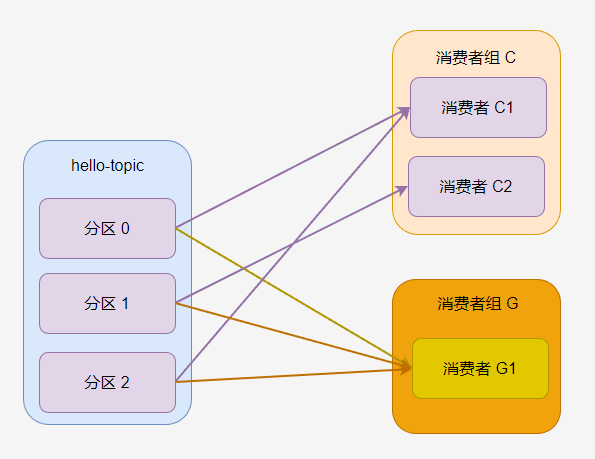
消费者组 G 中只有一个消费者,因此 G1 被分配了所有分区。
一般来说,一个消费者组的消费者数量跟分区数量一致最好,这样每个消费者可以消费一个分区。过多的消费者会导致部分消费者不能消费消息,过少的消费者会导致单个消费者需要处理多个分区的消息。
在消费者连接到 Broker 之后,Broker 便会给消费者分配主题分区。
在默认情况下,消费者的群组成员身份标识是临时的。当一个消费者离开群组时,分配给它的分区所有权将被撤销;当该消费者重新加入时,将通过再均衡协议为其分配一个新的成员 ID 和新分区。可以给消费者分配一个唯一的 group.instance.id,让它成为群组的固定成员。
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092",
GroupId = "C",
GroupInstanceId = "C1",
AutoOffsetReset = AutoOffsetReset.Earliest,
};如果两个消费者使用相同的 group.instance.id 加入同一个群组,则第二个消费者会收到错误,告诉它具有相同 ID 的消费者已存在。
消费位置
默认情况下,消费者的 AutoOffsetReset 参数是 AutoOffsetReset.Earliest,会自动从消费者组最近消费到的位置开始消费。
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092",
GroupId = "foo",
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var consumer = new ConsumerBuilder<int, string>(config).Build())
{
consumer.Subscribe("hello-topic");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine(consumeResult.Message.Value);
}
}
}AutoOffsetReset 的定义如下:
public enum AutoOffsetReset
{
Latest,
Earliest,
Error
} public AutoOffsetReset? AutoOffsetReset
{
get
{
return (AutoOffsetReset?)GetEnum(typeof(AutoOffsetReset), "auto.offset.reset");
}
set
{
SetObject("auto.offset.reset", value);
}
}下面是三个枚举的使用说明:
-
latest(default) which means consumers will read messages from the tail of the partition最新(默认) ,这意味着使用者将从分区的尾部读取消息,只消费最新的信息,即自从消费者上线后才开始推送来的消息。那么会导致忽略掉之前没有处理的消息。
-
earliestwhich means reading from the oldest offset in the partition这意味着从分区中最早的偏移量读取;自动从消费者上次开始消费的位置开始,进行消费。
-
nonethrow exception to the consumer if no previous offset is found for the consumer's group如果没有为使用者的组找到以前的偏移量,则不会向使用者抛出异常。
可以在 Kafdrop 中看到消费的偏移量。
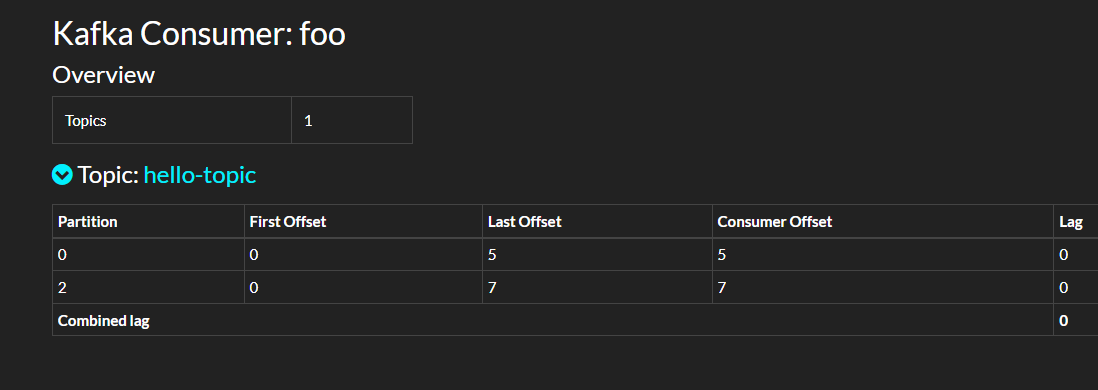
手动提交
客户端可以设置手动活自动确认消息。
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
GroupId = "foo",
// 是否自动提交,对自行定位消费位置无影响
EnableAutoCommit = false
}; var consumeResult = consumer.Consume();
consumer.Commit();消费定位
消费者可以自行设置要消费哪个分区的消息以及设置偏移量。
示例程序如下:
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
GroupId = "foo",
// 是否自动提交,对自行定位消费位置无影响
EnableAutoCommit = true
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
// 重新设置此消费组在某个分区的偏移量
consumer.Assign(new TopicPartitionOffset(new TopicPartition("hello-topic", new Partition(0)), new Offset(0)));
consumer.Assign(new TopicPartitionOffset(new TopicPartition("hello-topic", new Partition(1)), new Offset(0)));
consumer.Assign(new TopicPartitionOffset(new TopicPartition("hello-topic", new Partition(2)), new Offset(0)));
consumer.Subscribe("hello-topic");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine(consumeResult.Message.Value);
}
}
}如果要从指定时间开始消费,示例如下:
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
GroupId = "foo",
// 是否自动提交,对自行定位消费位置无影响
EnableAutoCommit = true
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
var timestamp = new Timestamp(DateTime.Now.AddDays(-1));
// 重新设置此消费组在某个分区的偏移量
consumer.Assign(consumer.OffsetsForTimes(new List<TopicPartitionTimestamp>
{
new TopicPartitionTimestamp(new TopicPartition("hello-topic", new Partition(0)),timestamp),
new TopicPartitionTimestamp(new TopicPartition("hello-topic", new Partition(1)),timestamp),
new TopicPartitionTimestamp(new TopicPartition("hello-topic", new Partition(2)),timestamp)
}, timeout: TimeSpan.FromSeconds(100)));
consumer.Subscribe("hello-topic");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine(consumeResult.Message.Value);
}
}
}
条件订阅
RabbitMQ 中有模糊订阅,但是 Kafka 中没有,所以如果想订阅符合条件的 Topic,需要先拿到集群中的所有 Topic,筛选后,订阅这些 Topic。
示例代码如下:
static async Task Main()
{
var adminConfig = new AdminClientConfig
{
BootstrapServers = "192.168.3.158:19092"
};
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092",
GroupId = "C",
GroupInstanceId = "C1",
AutoOffsetReset = AutoOffsetReset.Earliest,
};
List<string> topics = new List<string>();
using (var adminClient = new AdminClientBuilder(adminConfig).Build())
{
// 获取集群所有 topic
var metadata = adminClient.GetMetadata(TimeSpan.FromSeconds(10));
var topicsMetadata = metadata.Topics;
var topicNames = metadata.Topics.Select(a => a.Topic).ToList();
topics.AddRange(topicNames.Where(x => x.StartsWith("hello-")));
}
using (var consumer = new ConsumerBuilder<string, string>(config)
.Build())
{
consumer.Subscribe(topics);
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine($"key:{consumeResult.Message.Key},value:{consumeResult.Message.Value},partition:{consumeResult.Partition}");
}
}
}消费者中的反序列化器、拦截器、处理器,可以参考第四章中的生产者,这里不在赘述。

文章评论