阅读《实现领域驱动设计》做的小笔记。
什么是 DDD
领域模型
什么是领域模型?领域模型是关于某个特定业务领域的软件模型。通常,领域模型通过对象模型来实现,这些对象同时包含了数据和行为,并且表达了准确的业务含义。
领域模型即 DDD 中强调的建模,要设计一个模型,需要考虑三点:
- 为什么要建模;
- 怎么建模才合理;
- “领域”模型具体指什么
为什么要建模;怎么建模才合理;“领域”模型具体指什么。
DDD 把模型分成四层。
- UI 层,负责界面展示。
- 应用层(Application Layer),负责业务流程。
- 领域层(Domain Layer),负责领域逻辑。
- 基建层(Infrastructure Layer),负责提供基建。
分类的依据是:越往上,预期变动越频繁;越往下,预期变动越少。
而在领域层中出现的模型,即领域模型。
容易混淆的是应用层和领域层,在这两层中存在的,就是应用模型和领域模型。
按 DDD 的定义,领域模型应该捕捉“业务规则”或者“领域逻辑”(business rules / domain logic),而应用模型则捕捉“应用逻辑”(application logic)。模型属于哪一层,有个粗略的判断方式。如果是一个实体(entity)和针对实体的增删改查,就属于领域层;如果是一个场景, 比如出现在 UI 菜单上的选项,就属于应用层。
“领域模型”就是“解决方案空间”,是针对特定领域里的关键事物及其关系的可视化表现,是为了准确定义需要解决问题而构造的抽象模型,是业务功能场景在软件系统里的映射转化,其目标是为软件系统构建统一的认知。
处理领域复杂性
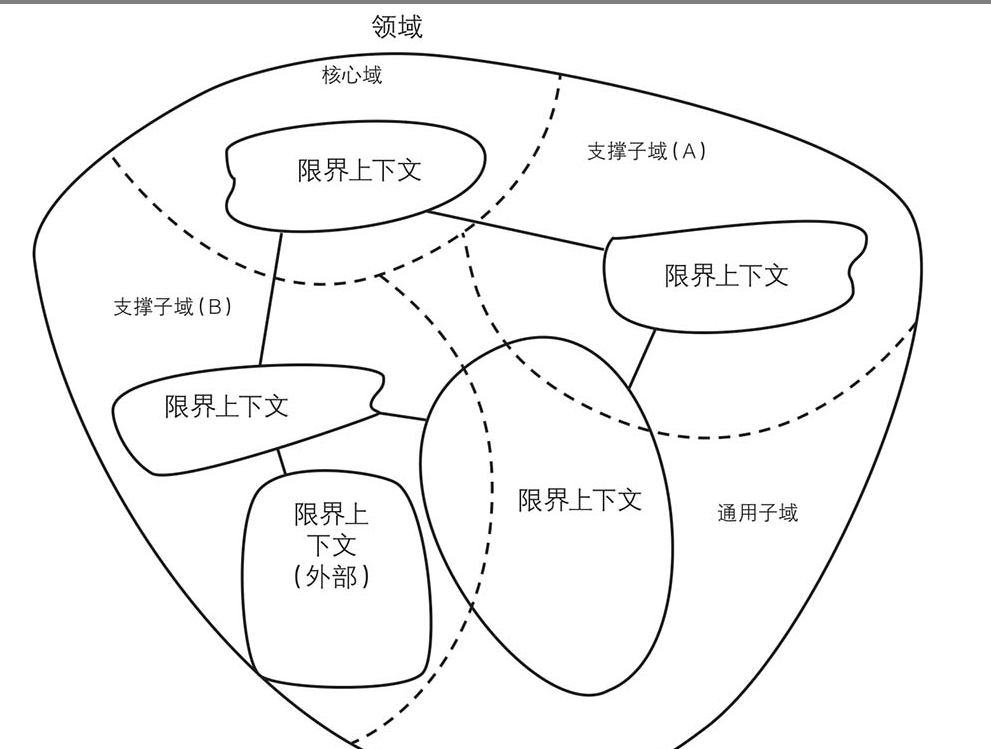
在使用DDD时,我们首先希望将它应用在最重要的业务场景下。对于那些可以轻易替换的软件来说,你是不会有所投入的。相反,值得你投入的是那些重要的、复杂的东西,因为这些东西将为你带来可观的回报。正因如此,我们将这样的模型命名为核心域(Core Domain,2),而那些相对次要的称为支撑子域(Supporting Subdomain,2)。那么现在,我们需要搞明白的是,“复杂”到底是什么意思?
DDD的作用是简化,而不是复杂化
在使用DDD时,我们应该采用最简单的方式对复杂领域进行建模,而不是使问题变得更加复杂。不同的业务领域对于复杂的定义是不一样的。另外,不同的公司所面临的挑战不一样;成熟度不一样;软件开发能力也不一样。因此,与其去定义什么是复杂的,还不如定义什么是重要的。这时,你的团队和管理层应该做出决定:你们开发的软件系统是否值得做出DDD投入。
计分卡
来决定你的项目是否值得做出DDD投入。如果你的项目情况在某行的描述范围之内,那么请在右边的列中记上相应的分数,最后将这些分数相加得到总分。如果得分为7分或者以上,那么,你应该考虑使用DDD了。
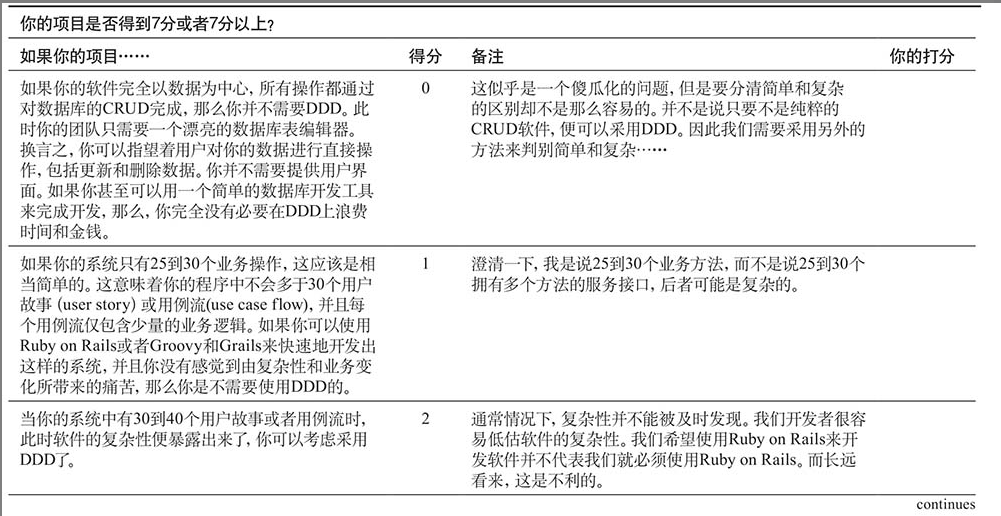
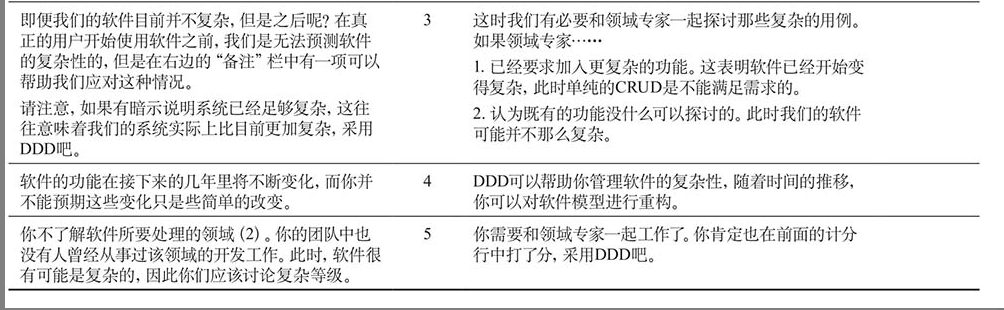
这意味着我们应该在项目计划早期便对简单性和复杂性做出判断,这将为我们节约很多时间和开销,并免除很多麻烦。一旦我们做出了重要的架构决策,并且已经在该架构下进行了深入地开发,通常我们也被绑定在这个架构下了,所以在决定时一定要慎重。
贫血症和失忆症
贫血症和失忆症贫血症严重危害着人类健康,并且伴随有危险的副作用。当贫血领域对象(Anemic Domain Object)[Fowler,Anemic]被首次提出来时,它并不是一个博得赞美的词汇,它描述的是一个缺少内在行为的领域对象。奇怪的是,人们对于贫血领域对象的态度褒贬不一。问题在于,多数开发者认为这样的领域对象是正常的,他们并没有意识到这是一个严重的问题。你是否想知道你所建模型的健康状况呢?如果你突然患上了技术上的“忧郁症”,这里你可以做个自我检查。你可能心情愉悦,也可能无比恐惧。通过表1.2中的步骤开始检查吧。
如何DDD
让我们暂时撇开关于实现细节的讨论,现在来看看DDD最具威力的特性之一:通用语言。通用语言和限界上下文(Bounded Context,2)同时构成了DDD的两大支柱,并且它们是相辅相成的。
上下文术语
就现在来说,可以将限界上下文看成是整个应用程序之内的一个概念性边界。这个边界之内的每种领域术语、词组或句子——也即通用语言,都有确定的上下文含义。在边界之外,这些术语可能表示不同的意思。我们将在第2章中对限界上下文做深入探讨。
通用语言
通用语言是团队共享的语言。领域专家和开发者使用相同的通用语言进行交流。事实上,团队中每个人都使用相同的通用语言。不管你在团队中的角色如何,只要你是团队的一员,你都将使用通用语言。
DDD 的业务价值

参考 https://weread.qq.com/web/reader/f5032ce071fd5a64f50b0f6k9bf32f301f9bf31c7ff0a60
持续建模和工具
DDD并不是画模型图,而是将领域专家的思维模型转化成有用的业务模型。DDD不是创建一个真实世界的模型,而是模仿现实。
在某个建模边界内部,团队将使用战术建模工具:聚合(Aggregate,10)、实体(Entity,5)、值对象(Value Object,6)、领域服务(Domain Service,7)和领域事件(Domain Event,8)等。
子域、限界上下文和上下文映射图
- 理解领域、子域和限界上下文
- 理解战略设计的重要性
- 学习一个真实的领域,其中包含多个子域
- 理解限界上下文
领域
从广义上讲,领域(Domain)即是一个组织所做的事情以及其中所包含的一切。
每个组织都有它自己的业务范围和做事方式。这个业务范围以及在其中所进行的活动便是领域。当你为某个组织开发软件时,你面对的便是这个组织的领域。这个领域对于你来说应该是明晰的,因为你在这个领域中工作。有一点需要注意的是,“领域”这个词可能承载了太多含义。领域既可以表示整个业务系统,也可以表示其中的某个核心域或者支撑子域。在本书中,我将尽可能地区分这些概念。当谈及到业务系统中的某个方面时,我会使用诸如“核心域”或者“子域”以示区别。
由于“领域模型”包含了“领域”这个词,我们可能会认为应该为整个业务系统创建一个单一的、内聚的、全功能式的模型。然而,这并不是我们使用DDD的目标。正好相反,在DDD中,一个领域被分为若干子域,领域模型在限界上下文中完成开发。事实上,在开发一个领域模型时,我们关注的通常只是这个业务系统的某个方面。试图创建一个全功能的领域模型是非常困难的,并且很容易导致失败。就像本章中所讲到的一样,对领域的拆分将有助于我们成功。那么,既然领域模型不能包含整个业务系统,我们应该如何来划分领域模型呢?几乎所有软件的领域都包含多个子域,这和软件系统本身的复杂性没有太大关系。有时,一个业务系统的成功取决于它所提供的多种功能,而将这些功能分开对待是有好处的。
统一语言必须在领域模型中表达出来,主要体现在领域模型中的名称上。
子域
零售商的领域可以分为4个主要的子域:产品目录(Product Catalog)、订单(Order)、发票(Invoicing)和物流(Shipping)。图2.1的上半部分表示了这样一个电子商务系统。
将关注点放在核心域上
下图是电费结算上下文最终涉及四个子域:结算实例、结算处理、清分结算和支付管理子域。
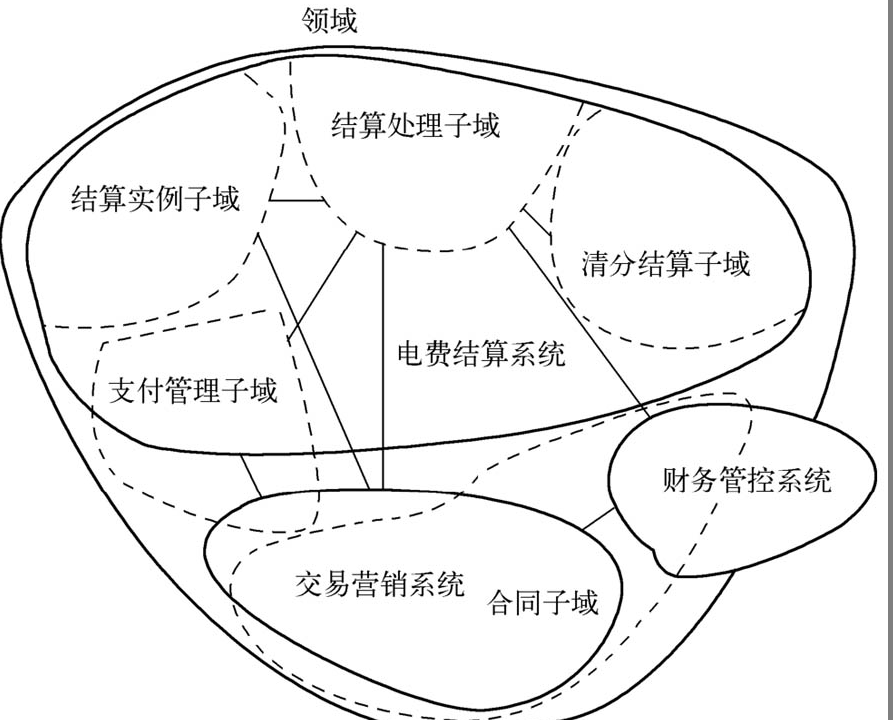
理解限界上下文
不要忘了,限界上下文是一个显式的边界,领域模型便存在于这个边界之内。领域模型把通用语言表达成软件模型。创建边界的原因在于,每一个模型概念,包括它的属性和操作,在边界之内都具有特殊的含义。如果你是建模团队中的一员,你便应该知道这些概念的确切含义。
限界上下文是显式的,充满语义的
限界上下文是一个显式边界,领域模型便存在于边界之内。在边界内,通用语言中的所有术语和词组都有特定的含义,而模型需要准确地反映通用语言。
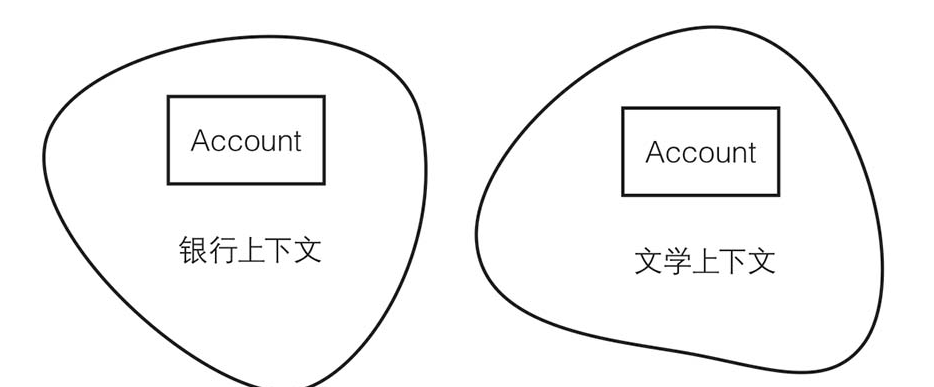
有界上下文是指在空间或时间上有边界的一段环境背景,它确定了每个模型的适用范围,模型体现了这个范围内的逻辑一致性。
这里有一个难点是:有界上下文是无形的,它不能直接反映出来,其逻辑一致性只能通过模型显现出来。模型的内部定义体现了其所在的上下文,例如从某个人说话的口音可以推断他是南方人还是北方人,南方或北方是上下文,口音是模型的内部定义。
例如对一个人来说,起模型如下定义:

注意,Person这个名称可能存在误导,对于一个人,他有工作,也有生活,因此,在Person里面放入工作和生活相关的属性都是允许的,所以,这里引出了命名问题。名称其实显式界定了该模型所处的有界上下文,这个名称可以称为统一语言,不过这个统一语言不是在整个领域统一的语言,而是在有界上下文边界内统一的语言。
这个模型内部有工号、职位,体现了这个模型是出于一个与职场有关的上下文,如果这个模型还有一个属性为“有几个孩子”,那么这个属性就出现与职位、工号等矛盾的地方了。
限界上下文包含的东西
限界上下文中可以包含多少领域模型中的基础部件呢,比如模块(9)、聚合(10)、领域事件(8)和领域服务(7)
核心领域之外的概念不应该包含在限界上下文中。
架构
分层
图4.1所示为一个典型的DDD系统所采用的传统分层架构,其中核心域只位于架构中的其中一层,其上为用户界面层(User Interface)和应用层(ApplicationLayer),其下是基础设施层(Infrastructure Layer)。
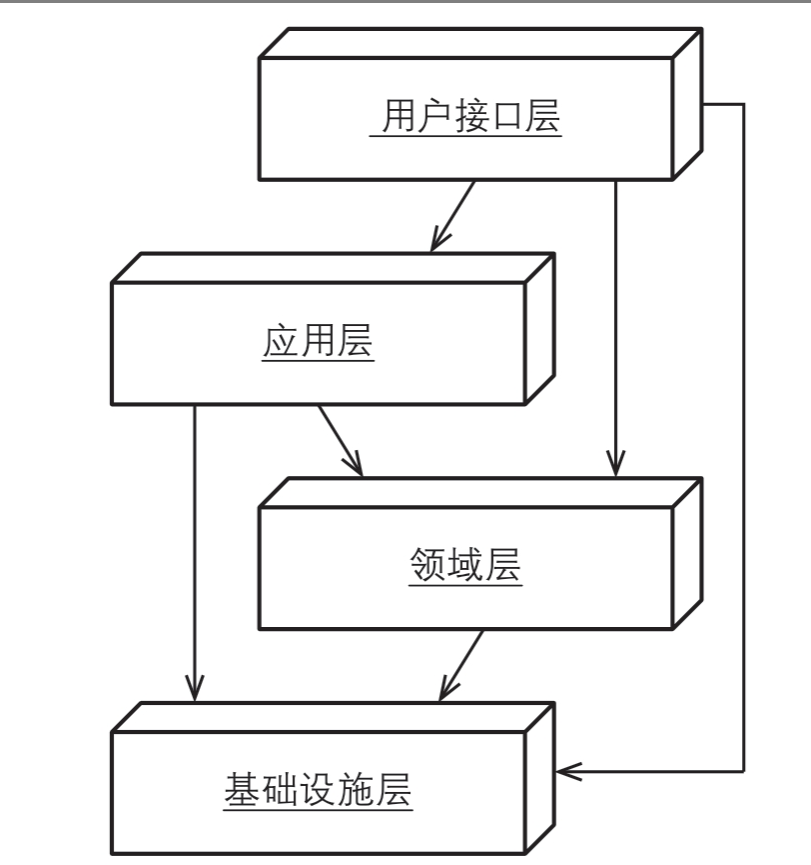
分层架构的一个重要原则是:每层只能与位于其下方的层发生耦合。分层架构也分为几种:在严格分层架构(Strict Layers Architecture)中,某层只能与直接位于其下方的层发生耦合;而松散分层架构(Relaxed Layers Architecture)则允许任意上方层与任意下方层发生耦合。由于用户界面层和应用服务通常需要与基础设施打交道,许多系统都是基于松散分层架构的。
当领域模型用于发布领域事件(Domain Events,8)时,应用层可以将订阅方注册到任意数量的事件上,这样的好处是可以对事件进行存储和转发。同时,领域模型只需要关注自己的核心逻辑;领域事件发布器(Domain Event Publisher,8)也可以保持轻量化,而不用依赖于消息机制的基础设施。
实体
开发者趋向于将关注点放在数据上,而不是领域上。这对于DDD新手来说也是如此,因为在软件开发中,数据库依然占据着主导地位。我们首先考虑的是数据的属性(对应数据库的列)和关联关系(外键关联),而不是富有行为的领域概念。
• 当对具有“唯一性”的事物进行建模时,为什么需要考虑使用实体。
• 学习如何生成实体的唯一标识。
• 学习如何从实体设计中捕获通用语言。
• 学习如何表达实体的角色和职责。
• 学习如何对实体进行验证和持久化。
当我们需要考虑一个对象的个性特征,或者需要区分不同的对象时,我们引入实体这个领域概念。一个实体是一个唯一的东西,并且可以在相当长的一段时间内持续地变化。我们可以对实体做多次修改,故一个实体对象可能和它先前的状态大不相同。但是,由于它们拥有相同的身份标识(identity),它们依然是同一个实体。
以 Tenant、User、UserPassword 来理解实体、聚合、聚合根的关系。
• User存在于某个Tenant之下,并受该Tenant控制
• 必须对系统中的User进行认证
• User可以处理自己的个人信息,包括名字和联系方式等
• User的个人信息可以被其本人和Manager修改
• User的安全密码是可以修改的
一个User应该具有唯一的标识,以区别于其他User。一个User同时还应该支持在其生命周期中的各种修改。显然,此时的User是一个实体。这里,我们并不关心如何对User的内部进行建模。
团队成员需要对以上的第一条需求做个澄清:
• User存在于某个Tenant之下,并受该Tenant控制
团队本来可以添加一些注释或者修改一下用词,以此来说明这里的意思是“Tenant拥有User”,但是他们并没有这么做。此时,团队成员们需要格外小心,因为他们不应该陷入技术和战术建模这样的细节中。最后,他们对User的描述做了以下修改:
• Tenant可以邀请多个User进行注册
• Tenant可以处于激活状态或失活状态
• 系统必须对User进行认证,并且只有当Tenant处于激活状态时才能对User进行认证
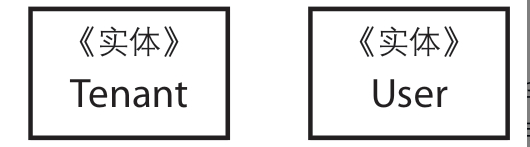
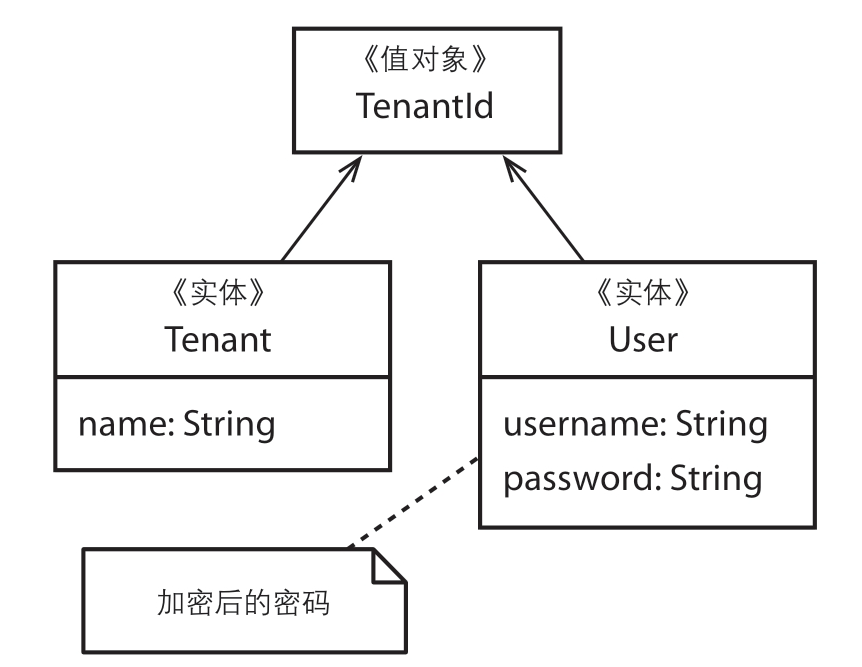
Tenant实体即为User实体的工厂,也是同一个模块中唯一能够访问User构造函数的类 。这样一来,只有Tenant能够创建User实例:


验证属性我们如何确保属性处于合法状态呢?正如我在本书其他地方所讲,我强烈建议使用自封装(Self-Encapsulation)来验证属性。
值对象
全然面向实体的思维方法不仅没有必要,而且还浪费开发时间。
在设计得当的情况下,我们可以对值对象实例进行创建和传递,甚至在使用完之后将其直接扔掉。我们不用担心客户端对值对象的修改。一个值对象的生命周期可长可短,它就像一个无害的过客在系统中来来往往。
虽然创建一个值对象类型非常简单,但是有时甚至连有经验的DDD开发者都面临这样一个难题:是应该建模成实体呢还是值对象?和如何实现值对象一道,我希望在本章中教你理清这些含糊的概念。

当你的模型中的确存在一个值对象时,不管你是否意识到,它都不应该成为你领域中的一件东西,而只是用于度量或描述领域中某件东西的一个概念。一个人拥有年龄,这里的年龄并不是一个实在的东西,而只是作为你出生了多少年的一种度量。一个人拥有名字,同样这里的名字也不是一个实在的东西,而是描述了如何称呼这个人。
一个值对象在创建之后便不能改变了。
那么,在什么情况下,一个操作不属于实体(5)或者值对象呢?要给出一个全面的原因列表是困难的,这里我罗列了以下几点。你可以使用领域服务来:
• 执行一个显著的业务操作过程。
• 对领域对象进行转换。
• 以多个领域对象作为输入进行计算,结果产生一个值对象。
需要明确的是,对于最后一点中的计算过程,它应该具有“显著的业务操作过程”的特点。这也是领域服务很常见的应用场景,它可能需要多个聚合作为输入。当一个方法不便放在实体或值对象上时,使用领域服务便是最佳的解决方法。请确保领域服务是无状态的,并且能够明确地表达限界上下文中的通用语言(1)
什么是领域服务
在全面的实体 Tenant 、User 中,他们都具有独立的操作方法。
根据创建领域服务的目的,有时对领域服务进行建模是非常简单的。你需要决定你所创建的领域服务是否需要一个独立接口[Fowler,P of EAA]。如果是,你的领域服务接口可能与以下接口相似:

独立接口有必要吗
由于这里的AuthenticationService并没有一个技术上的实现,我们真的有必要为其创建一个独立接口并将其与实现类分离在不同的层和模块中吗?这是没有必要的。我们只需要创建一个实现类即可,其名字与领域服务的名字相同。
对于领域服务来说,以上的例子同样是可行的。我们甚至会认为这样的例子更加合适,因为我们知道不会再有另外的实现类。但是,不同的租户可能有不同的安全认证标准,所以产生不同的认证实现类也是有可能的。然而此时,SaaSOvation的团队成员决定弃用独立接口,而是采用了上例中的实现方法。
给领域服务的实现类命名
在Java世界中,常见的命名实现类的方法便是给接口名加上Impl后缀。
按照这种方法,我们的认证实现类为AuthenticatioinServiceImpl
。此外,实现类和接口通常被放在相同的包下。这是一种好的做法吗?事实上,如果你采用这种方式来命名实现类,这往往意味着你根本就不需要一个独立接口。因此,在命名一个实现类时,我们需要仔细地思考。这里的AuthenticationServiceImpl并不是一个好的实现类名,而DefaultEncryptionAuthenticationService也不见得能好到哪里去。
基于这些原因,SaaSOvation的团队成员决定去除独立接口,而直接使用AuthenticationService作为实现类。
如果领域服务具有多个实现类,那么我们应该根据各种实现类的特点进行命名,而这往往又意味着在你的领域中存在一些特定的行为功能。


依赖倒置容器(比如Spring)将完成服务实例的注入工作。由于客户端并不负责服务的实例化,它并不知道接口类和实现类是分开的还是合并在一起的。
领域事件
在讨论领域事件之前,让我们先来看看当前对领域事件的定义:领域专家所关心的发生在领域中的一些事件。将领域中所发生的活动建模成一系列的离散事件。每个事件都用领域对象来表示……领域事件是领域模型的组成部分,表示领域中所发生的事情。[Evans,Ref,p.20]
在建模领域事件时,我们应该根据限界上下文中的通用语言来命名事件及其属性。如果事件由聚合上的命令操作产生,那么我们通常根据该操作方法的名字来命名领域事件。对于上面的例子,当我们向一个冲刺提交待定项时,我们将发布与之对应的领域事件:
聚合
将实体(5)和值对象(6)在一致性边界之内组成聚合(Aggregate)乍看起来是一件轻松的任务,但在DDD众多的战术性指导中,该模式却是最不容易理解的。
roduct首先被建模成了一个非常大的聚合。此时的Product作为一个根(root)对象而存在,它包含了所有的BacklogItem、Release和Sprint,而Product的接口设计避免了客户端对其所包含数据的意外删除。此时Product的实现代码如下,对应的UML图请参考图10.1:图10.1 Product被建模成了一个臃肿的聚合
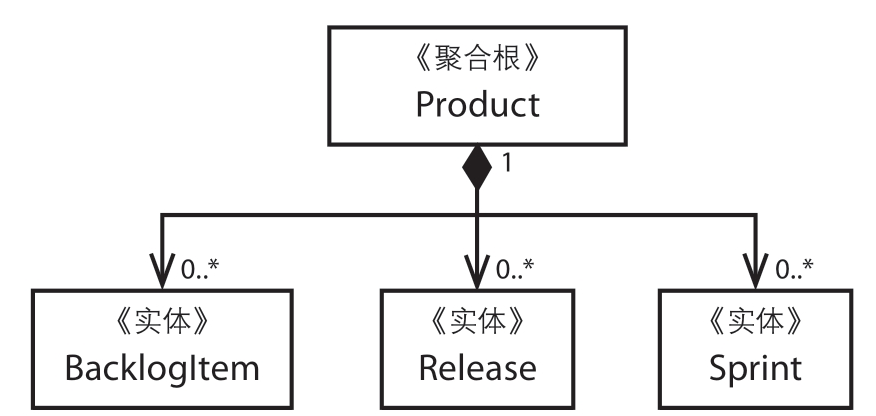
这个巨大的聚合看似诱人,但是却不实用。当系统运行于多租户环境中时,时常会出现事务失败的情况。让我们再进一步看看客户端是如何与这个技术性模型交互的。在持久化时,我们使用了乐观并发(optimistic concurrency)的方式以避免多个客户端同时修改一个Product实例。在实体(5)中我们讲到,持久化对象携带有一个递增的版本号,该版本号随着每次对该对象的修改而增加。如果对象在数据库中的版本号大于在客户端中的版本号,服务器将拒绝客户端的请求。
第二次尝试:多个聚合
现在,让我们来看看另一种方法,如图10.2所示,该方法使用了4个分离的聚合类。它们之间通过ProductId关联起来,ProductId是Product的唯一标识。此时,Product作为其他3个聚合类的父聚合而存在。
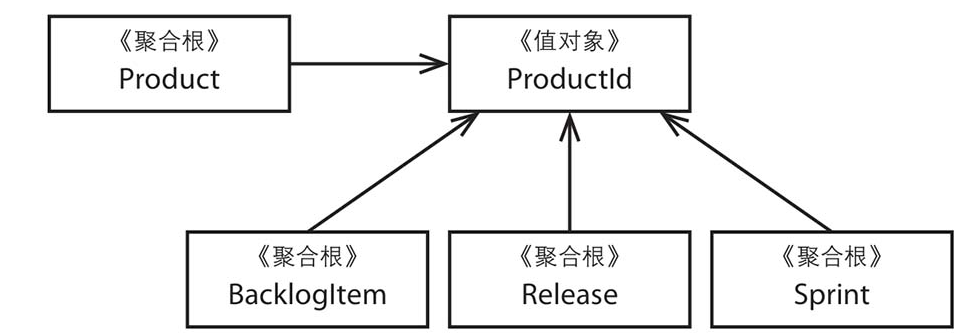
在将一个大的Product聚合拆分成4个相对较小的聚合时,Product类的方法签名也将发生改变。对于先前那个庞大的Product,它的方法签名如下:[插图]

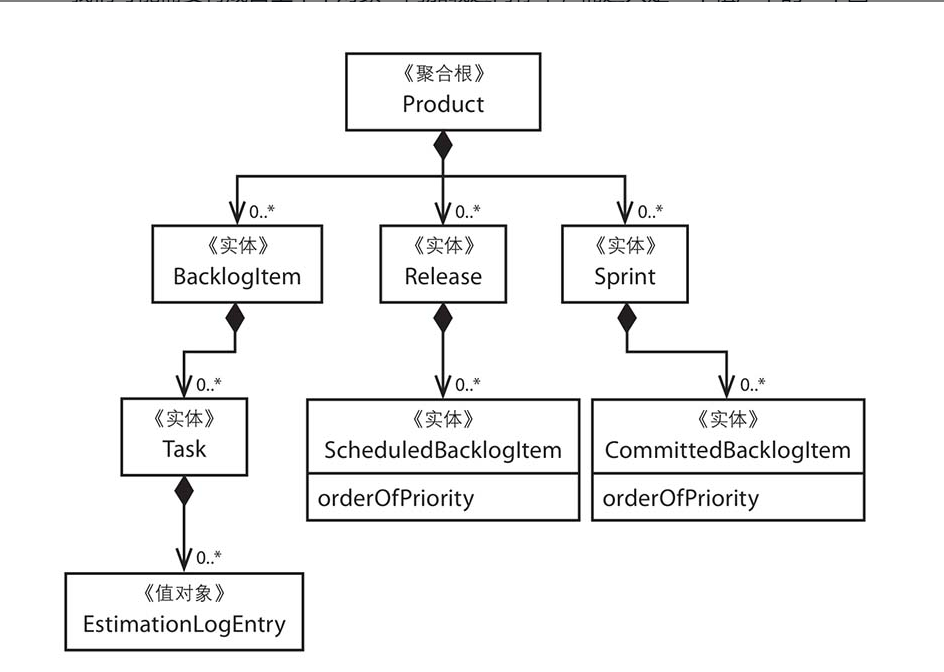
设计的聚合要尽可能小
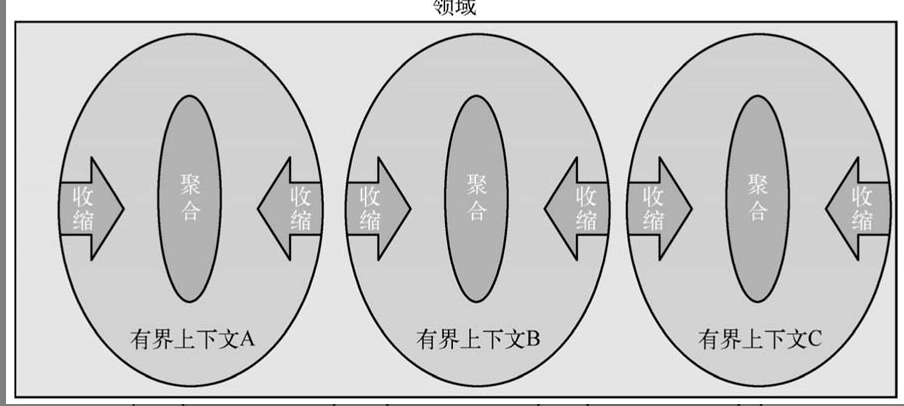
如果把有界上下文比喻为对土地进行划界,那么在划好界的土地上盖房子就类似于聚合;这些房子中有主要建筑和辅助建筑,是一群房子,而聚合也是一群对象,其中也有主从之分。建筑群与这块土地的关系类似于聚合与有界上下文的关系,聚合是一种领域模型,这种模型的意义取决于它所处的有界上下文,而有界上下文中逻辑一致性这样的核心概念也必须通过聚合等领域模型来体现,这是首要设计原则。
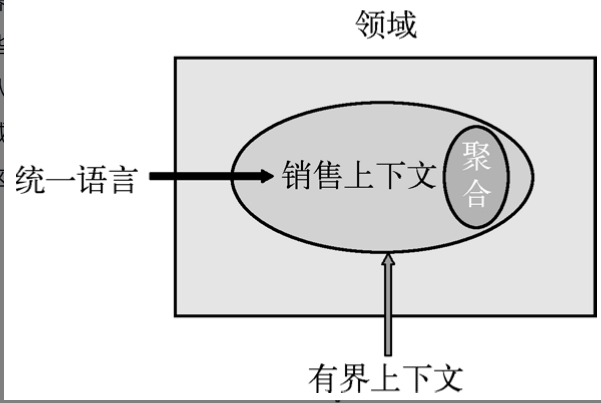
如果说有界上下文解决了领域内的划分,那么聚合就解决了有界上下文内对象之间的划分。所谓划分就是将紧密的放一起,让松散的更加松散,甚至没有关系。从这里能看出DDD的一种收缩趋势,各领域分别向以聚合为核心的方向设计,如图3-2所示。
聚合内部:
聚合是一个行为在逻辑上高度一致的对象群,注意,它是一个对象群体的总称。聚合的内部结构如同一棵树,每个聚合都有一个根,其他对象和聚合根之间都是枝叶与树根的关系。图3-3所示为聚合内部结构示意图。
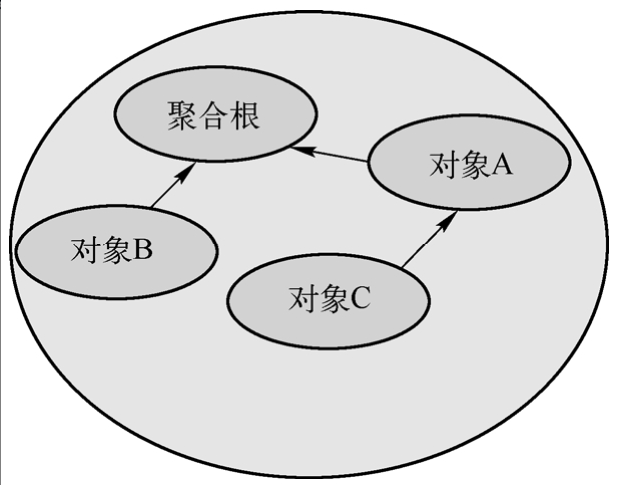
这样有序化的好处是:只有“根”能引用或指向其他对象,“根”自身不能被其他任何对象引用;“根”类似团队的小组长,队员都要向其汇报工作。这就是聚合根的设计来源,聚合根拥有自己边界内的数据所有权,以及行为职责的管理权限。

聚合设计实例:
https://weread.qq.com/web/reader/95932e2072052ac7959169dk98f3284021498f137082c2e

文章评论