Kubernetes 日志 和 EFK 日志方案
本文主要参考以下两个文章,对文章内容进行翻译整合。
https://devopscube.com/kubernetes-logging-tutorial/
https://devopscube.com/setup-efk-stack-on-kubernetes/
第一部分:Kubernetes 日志
在这个 Kubernetes 日志教程中,您将学习 Kubernetes 集群日志中涉及的关键概念和工作流。
当涉及到 Kubernetes 生产调试时,日志起着至关重要的作用。它可以帮助你理解正在发生的事情,哪里出了问题,甚至是哪里可能出问题。作为一名 DevOps 工程师,您应该清楚地了解 Kubernetes 日志以解决集群和应用程序问题。
Kubernetes Logging 是如何工作的
在 Kubernetes,大多数组件都是以容器方式运行的。在 kubernetes 架构中,一个应用程序 Pod 可以包含多个容器,大多数 Kubernetes 集群组件都是这样,如 api-server、 kube-scheduler、 Etcd、 kube 代理等等,会以容器方式运行。但是,kubelet 组件以本机 systemd 服务运行。
在这一节中,我们将看看日志是如何为 Kubernetes Pod 工作的。它可以是一个 Application Pod 或 Kubernetes component Pod。我们还将研究如何管理 kubelet systemd 日志。
通常,我们在 Kubernetes 上部署的任何 Pod 都会将日志写入 stdout 和 stderr 流,而不是将日志写入专用的日志文件。但是,来自每个容器的对 stdout 和 stderr 的流都以 JSON 格式存储在文件系统中。底层容器引擎完成这项工作,它被设计用来处理日志记录。例如,Docker 容器引擎。
笔者注:这段话的意思是容器应用的日志通过控制台输出时,会被容器引擎收集,这些日志流会被以 Json 文件的形式存储到文件系统中。
容器的日志收集方式后面提到。
注意: 所有 kubernetes 集群组件日志都是像处理其他容器日志一样处理的。
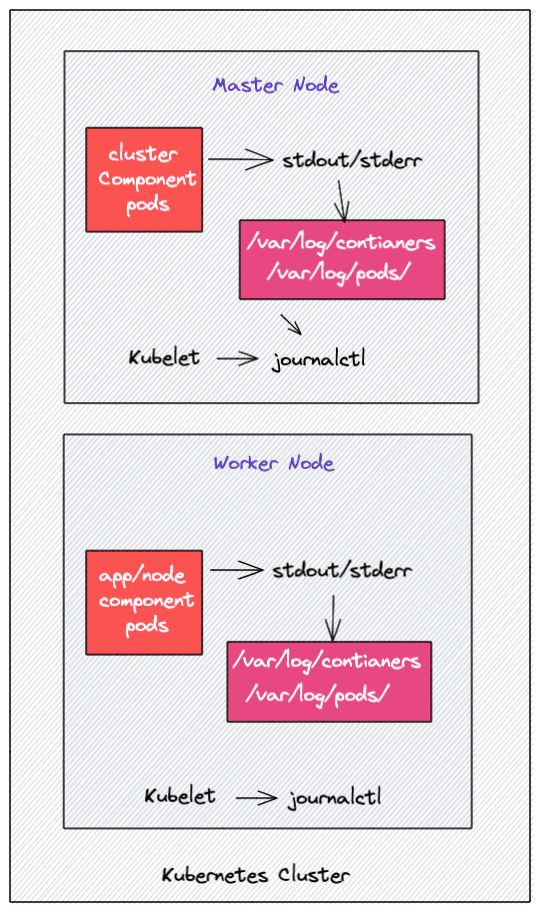
Kubelet 在所有节点上运行,以确保节点上的容器正常运行。它还负责运行的静态 Pod 以及,如果 kubelet 作为一个系统服务运行,它将日志记录到 journald(systemd-journald )。
另外,如果容器没有将日志传输到 stdout 和 stderr,您将不会使用 kubetl logs 命令获得日志,因为 kubelet 无法访问日志文件。
笔者注:例如 Pod 在节点 B 中运行,但是你在 A 节点执行
kubectl logs命令,Pod 的日志不会凭空飞过去,是通过 kubelet 传输过去的。
这一小节说的是,程序的日志要通过 stdout 和 stderr 输出,才会被 Kubernetes 利用(kubectl logs),而在节点间传输日志的组件叫 kubelet。因为 kubelet不是以 Pod 而是以 systemd 的形式运行,因此 kubelet 自身的日志要通过 systemd-journald 查看。
Kubernetes Pod 日志存储位置
您可以在以下每个工作节点的目录中找到 kubernetes 存储的 Pod 日志。
- /var/log/containers: 所有容器日志都存在于一个单独的位置;
- /var/log/pods/: 在此位置下,容器日志被组织到单独的 pod 文件夹中。
/var/log/pods/<namespace>_<pod_name>_<pod_id>/<container_name>/.每个 pod 文件夹包含单个容器文件夹及其各自的日志文件。每个文件夹都有一个命名方案;
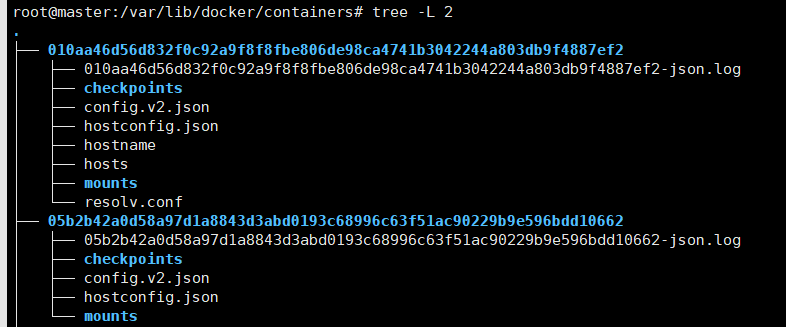
另外,如果您的底层容器工程师是 docker,您将在 /var/lib/docker/containers 文件夹中找到日志。
日志以 Json 的形式记录,还会记录日志的一些属性信息。
{"log":"Shutting down, got signal: Terminated\n","stream":"stderr","time":"2021-11-09T06:14:42.535854831Z"}
如果您登录到任何 Kubernetes 工作者节点并转到 /var/log/containers 目录,您将找到该节点上运行的每个容器的日志文件。日志文件命名方案遵循 /var/log/pods/<namespace>_<pod_name>_<pod_id>/<container_name>/。下面的图片显示了一个例子。
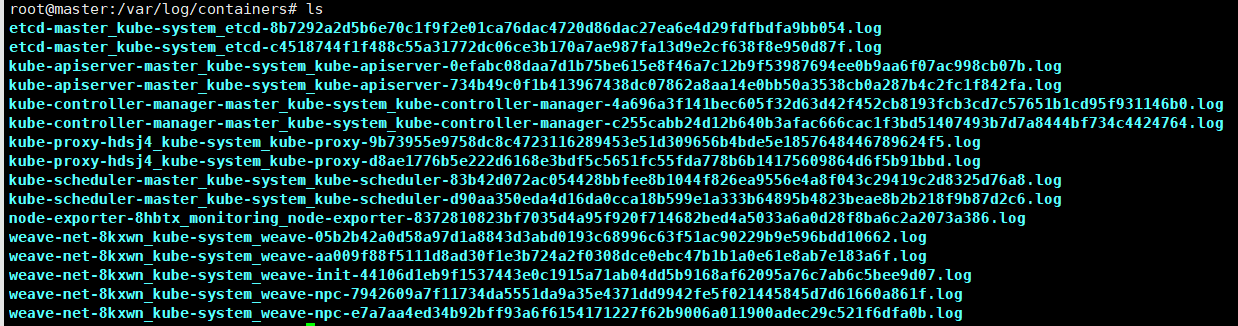
此外,这些日志文件由 Kubelet 控制,因此当您运行 kubectl logs命令时,Kubelet 会在终端中显示这些日志。
Kubelet Logs
对于 Kubelet,您可以使用 journalctl 从单个工作者节点访问日志。例如,使用以下命令检查 Kubelet 日志。
journalctl -u kubelet
journalctl -u kubelet -o cat如果 Kubelet 在没有 systemd 的情况下运行,您可以在 /var/log 目录中找到 Kubelet 日志。
Kubernetes 容器日志格式
下面是容器日志的其中一行数据示例:
{"log":"Shutting down, got signal: Terminated\n","stream":"stderr","time":"2021-11-09T06:14:42.535854831Z"}如前所述,所有日志数据都以 JSON 格式存储。因此,如果打开任何一个日志文件,就会发现每个日志条目都有三个键。
log-实际的日志数据stream– 写入日志的流time– Timetamp 时间表
Kubernetes 日志的类型
说到 Kubernetes,以下是不同类型的日志。
-
Application logs: 来自用户部署的应用程序的日志。应用程序日志有助于理解应用程序内部发生的事情。
-
Kubernetes Cluster components(集群组件):来自 api-server、 kube-scheduler、 etcd、 kube-proxy 等的日志。
-
Kubernetes Audit logs(审计日志): 所有与 API 服务器记录的 API 活动相关的日志。主要用于调查可疑的 API 活动。
Kubernetes Logging 架构
如果我们将 Kubernetes 集群作为一个整体,那么我们将需要统一收集日志。但是 Kubernetes 并不提供任何日志收集功能,因此您需要设置一个集中的日志后端(例如: Elasticsearch) ,并将所有日志发送到日志后端。下面的图像描绘了一个 high-level 的 Kubernetes Logging 架构。
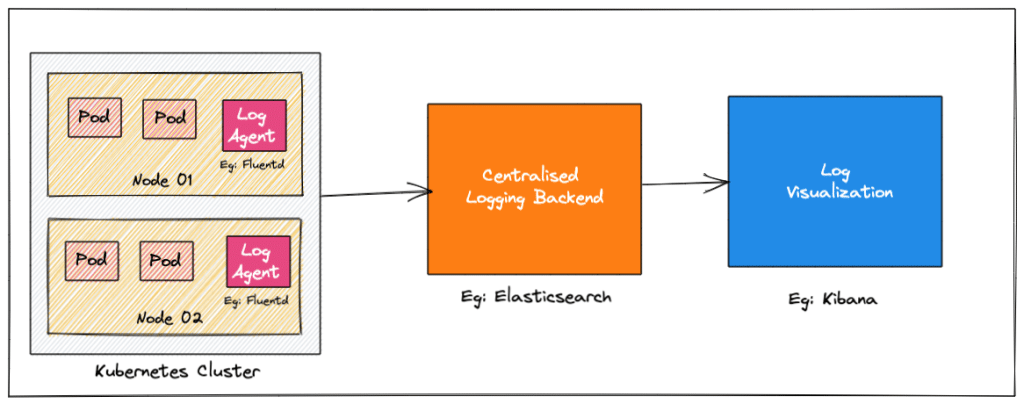
让我们了解一下日志记录的三个关键组件。
- Logging Agent: 一个日志代理,可以在所有的 Kubernetes 节点中作为 daemonset 运行,它将日志不断地集中到日志后端。日志代理也可以作为 sidecar 容器运行。例如 Fluentd。
- Logging Backend: 一个集中的系统,能够存储、搜索和分析日志数据。
- Log Visualization: 以仪表板的形式可视化日志数据的工具。
Kubernetes Logging 模式
本节将研究一些 Kubernetes 日志记录模式,以便将日志流传到日志后端。有三种关键的 Kubernetes 集群日志记录模式
- Node level logging agent
- Streaming sidecar container
- Sidecar logging agent
让我们详细研究一下每个方案的特点。
Node Level Logging Agent
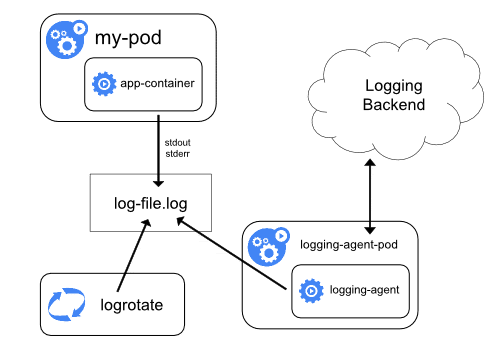
在这种方法中,每个节点运行着一个代理(例如: Fluentd)读取使用容器 STDOUT 和 STDERR 流创建的日志文件,然后将其发送给像 Elasticsearch 这样的日志后端。这是一种常用的日志记录模式,不需要任何开销就可以很好地工作。
而云原生中的 12因素应用程序方法 也建议将日志流传到 STDOUT。
Streaming sidecar container
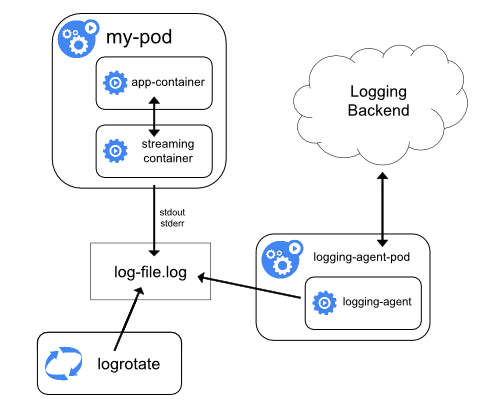
当应用程序不能直接向 STDOUT 和 STDERR 流写入日志时,这种 Sidecar 方法非常有用。
Pod 中的应用程序容器将所有日志写入容器中的一个文件,然后 Pod 中存在一个 sidecar 容器从该日志文件中读取数据并将其传输到 STDOUT 和 STDERR,最后利用 Node Level Logging Agent 的方式收集。
应用程序的日志自定义文件 -> 重新将流输出到 STDOUT -> 容器引擎收集
Sidecar Logging Agent
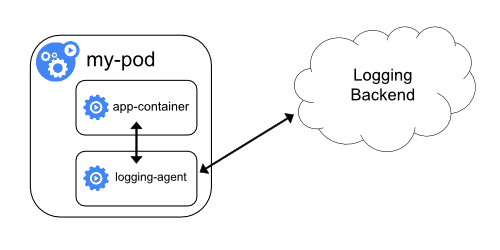
在这种方法中,日志不会被流送到 STDOUT 和 STDERR。相反,一个带有日志代理的 sidecar 容器将与应用程序容器一起运行。然后,日志代理将直接将日志流传到日志后端。
也就是说,Pod 中的 sidecar 容器,把日志1直接推送到日志存储后端,不需要容器引擎的收集。
这种方法有两个缺点。
- 将日志记录代理作为 sidecar 运行是资源密集型的,即会消耗大量 IO。
- 您不能使用
kubectl logs命令获得日志,因为 Kubelet 不会处理日志。
Kubernetes Logging 工具
Kubernetes 最常用的开源日志堆栈是 EFK (Elasticsearch,Flunentd/Fluent-but,和 Kibana)。
EFK 方案包含以下三大部件:
- Elasticsearch – Log 聚合器
- Flunetd/Fluentbit – Logging 代理(Fluentbit 是为集装箱工作负载设计的轻量级代理)
- Kibana – Log 可视化和仪表板工具
当涉及到像 Google GKE、 AWS 和 Azure AKS 这样的管理 Kubernetes 服务时,它集成了特定于云的集中式日志记录。因此,当您部署托管 kubernetes 集群时,您将获得在相应的日志记录服务中启用日志监视的选项。比如说:
- AWS EKS uses Cloud
- Google GKE uses Stackdriver monitoring
- Azure AKS uses Azure Monitor
需要在云上操作。
此外,组织可能会使用企业日志解决方案,比如 Splunk。在这种情况下,日志被转发给 Splunk 监控,并遵守组织的日志保留规范。以下是一些企业日志解决方案。
Kubenretes Logging 与 EFK
在 Kubernetes 中,目前其中一个最好的开源日志方案是 EFK ,它包含 Elasticsearch、 Fluentd 和 Kibana 三个部分。
在第二部分中,我们将在 Kubernetes 集群中,部署 EFK 日志方案。
第二部分:EFK 实践
第一部分,其中为初学者介绍了 Kubernetes 日志基本原理和模式。在第二部分中,您将学习如何在 Kubernetes 集群上设置用于日志流、日志分析和日志监视的 EFK。
在 Kubernetes 集群上运行多个应用程序和服务时,将所有应用程序和 Kubernetes 集群日志流到一个集中的日志基础设施中,以便于日志分析,这样做更有意义。第二部分旨在通过 EFK 堆栈向您介绍 Kubernetes 日志的重要技术方面。
EFK Stack
EFK 代表 Elasticsearch、 Fluentd 和 Kibana。EFK 是用于 Kubernetes 日志聚合和分析的流行且最佳的开源选择。
- Elasticsearch 是一个分布式和可扩展的搜索引擎,通常用于筛选大量的日志数据。它是一个基于 Lucene 搜索引擎(来自 Apache 的搜索库)的 NoSQL 数据库。它的主要工作是储存日志和从 Fluentd 中取回日志。
- Fluentd 是日志收集处理器,它是一个开源日志收集代理,支持多个数据源和输出格式。此外,它还可以将日志转发给 Stackdriver、 Cloudwatch、 Elasticsearch、 Splunk、 Bigquery 等。简而言之,它是日志数据生成系统和日志数据存储系统之间的统一层。
- Kibana 是一个用于查询、数据可视化和仪表板的 UI 工具。它是一个查询引擎,允许您通过 web 界面探索您的日志数据,为事件日志构建可视化,特定于查询过滤信息以检测问题。您可以使用 Kibana 虚拟地构建任何类型的仪表板。Kibana Query Language (KQL)用于查询 elasticsearch 数据。在这里,我们使用 Kibana 在 elasticsearch 中查询索引数据。
此外,Elasticsearch 还可以帮助解决大量非结构化数据分离的问题,目前许多组织都在使用 Elasticsearch,通常跟 Kibana 部署在一起。
注意: 当涉及到 Kubernetes 时,FLuentd 是最好的选择,因为比 logstash 更好,因为 FLuentd 可以解析容器日志而不需要任何额外的配置。此外,这是一个 CNCF 项目。
在 Kubernetes 上设置 EFK
接下来我们将一步步在 Kubernetes 中部署和配置 EFK,你可以在 Kubernetes EFK Github repo 中找到本博客中使用的所有部署定义文件,每个 EFK 组件的 YAML 定义文件都放在不同的目录中。
首先克隆仓库:
git clone https://github.com/scriptcamp/kubernetes-efk注意,在本文部署的 EFK 组件,都会在 Kubernetes 默认的 default 命名空间中。
仓库的文件结构如下:
├── kubernetes-efk
│ ├── README.md
│ ├── elasticsearch
│ │ ├── es-sts.yaml
│ │ └── es-svc.yaml
│ ├── fluentd
│ │ ├── fluentd-ds.yaml
│ │ ├── fluentd-rb.yaml
│ │ ├── fluentd-role.yaml
│ │ └── fluentd-sa.yaml
│ ├── kibana
│ │ ├── kibana-deployment.yaml
│ │ └── kibana-svc.yaml
│ └── test-pod.yamlEFK 架构
下图显示了我们将要构建的 EFK 的高级架构。
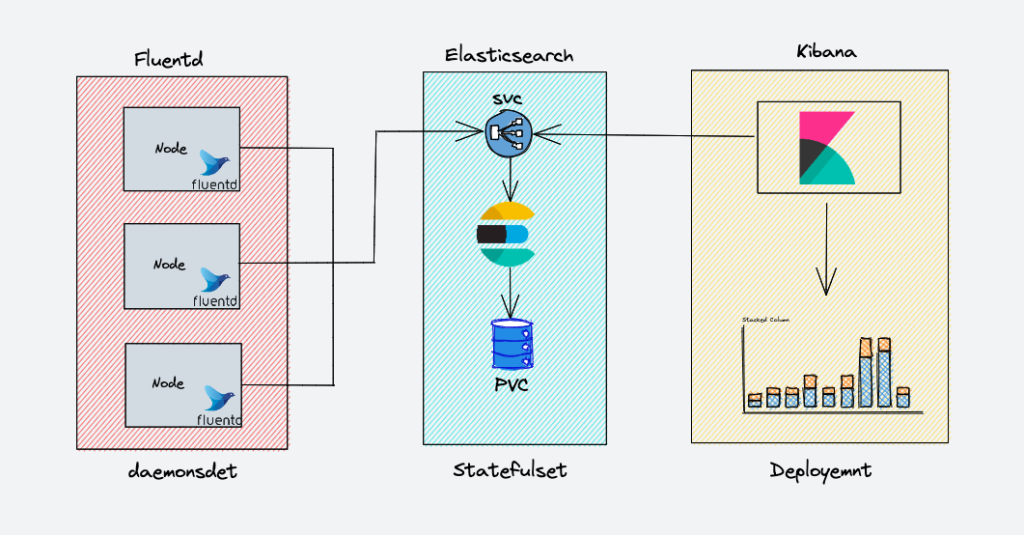
EKF 组件部署说明如下:
- Fluentd: 在需要从所有节点收集容器日志时作为守护进程部署。它连接到 Elasticsearch 服务端点以转发日志。
- Elasticsearch:在保存日志数据时作为状态集部署。我们还公开 Fluentd 和 kibana 的服务端点以连接到它。
- Kibana:- 作为部署部署并连接到 Elasticsearch 服务端点。
部署 Elasticsearch Statefulset
Elasticsearch 是作为 Statefulset 部署的,多个副本通过一个 headless service 彼此连接。Headless svc 在 Pod 的 DNS 域中提供帮助。
打开 elasticsearch/es-svc. yaml 文件,可以看到定义如下:
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node让我们现在就创造它。
kubectl create -f es-svc.yaml在我们开始为弹性搜索创建 statefulset 之前,让我们回想一下,statefulset 需要事先定义的存储类,它可以在需要时创建卷。
注意: 虽然在生产环境中,可能需要 400-500gb SSD 支撑 ES 的存储,由于这里是存储环境,因此定义 YAML 文件中是 3GB 的 PV。
笔者因为要学习 EFK,特意挂载了一个 512GB 的企业级 SSD。
在 elasticsearch/es-sts.yaml 文件中,它会自动创建一个具有 3GB 的存储卷,其定义如下:
spec:
accessModes: [ "ReadWriteOnce" ]
# storageClassName: ""
resources:
requests:
storage: 3Gi由于笔者有自己的盘,笔者挂载到了 slave2 节点中,所以这里笔者就不用这个配置了,笔者使用 NFS - PV 的方式,当然读者为了避免麻烦,可以继续使用上面的配置。
读者可以首先按照 https://k8s.whuanle.cn/5.volumes/3.nfts.html 部署自己的 NFS 存储,然后利用下面这个模板创建 PV。
apiVersion: v1 kind: PersistentVolume metadata: name: es-pv spec: capacity: storage: 450Gi volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle storageClassName: es-volume mountOptions: - hard - nfsvers=4.1 nfs: path: /data/volumns/es server: 10.0.0.4需读者自行提前创建 NFS,读者可参考 https://k8s.whuanle.cn/5.volumes/3.nfts.html 创建一个自己的跨节点的存储系统。
将 volumeClaimTemplates 部分改成:
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "es-volume"
resources:
requests:
storage: 450Gi然后我们看一下 es-sts.yaml 的文件中,对于 Eelasticsearch 集群的定义:
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"这里有两个地方要注意,一是你的集群必须要安装 CoreDNS,二是你的从节点数量跟 es-sts.yaml 中定义的 replicas: 3 数量一致,如果你有三个节点(一主二从),那么 replics 要设置为 2,但是一般 Eelasticsearch 实例数量都是单数。因此笔者只设置使用一个 Eelasticsearch 实例。
然后部署 Elasticsearch :
kubectl create -f es-sts.yaml 验证 Elasticsearch 部署
在 Elasticsearch Pod 进入运行状态之后,让我们尝试验证 Elasticsearch 状态集。最简单的方法是检查集群的状态。为了检查状态,端口前进 Elasticsearch Pod 的 9200 端口。
kubectl port-forward es-cluster-0 19200:9200port-forward 方式具有临时性,避免 Elasticsearch 暴露到外网;或者使用 Service IP 等方式测试 IP 连通性,你还可以使用 Service NodePort 的方式暴露 Elasticsearch 。
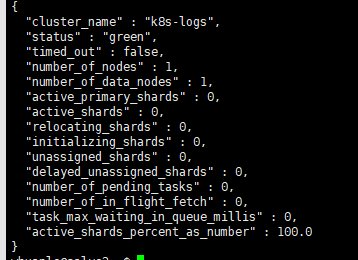
要检查 Elasticsearch 集群的健康状况,请在终端中运行以下命令。
curl http://localhost:19200/_cluster/health/?pretty输出将显示 Elasticsearch 集群的状态。如果所有的步骤都被正确的执行,访问此地址,会获得 Json 响应。
部署 Kibana
跟部署 Elasticsearch 一样,可以使用一个简单的 yaml 文件部署 Kibana。如果您检查以下 Kibana 部署清单文件,我们有一个 ELASTICSEARCH_URL 定义来配置 Elasticsearch 集群 Endpoint,Kibana 使用 Endpoint URL 连接 Elasticsearch。
下面是 kibana-deployment.yaml 文件的定义。
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.5.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601"state":"green","message":"Status changed from yellow to green - Ready","prevState":"yellow","prevMsg":"Waiting for Elasticsearch"
现在直接部署 Kibana 即可:
kubectl create -f kibana-deployment.yaml让我们创建一个 NodePort 类型的 Service,通过节点 IP 地址访问 Kibana UI。我们使用 nodePort 进行演示。然而,理想情况下,kubernetes 与 ClusterIP 服务的接入用于实际的项目实现。
kibana-svc.yaml 文件的定义如下:
apiVersion: v1
kind: Service
metadata:
name: kibana-np
spec:
selector:
app: kibana
type: NodePort
ports:
- port: 8080
targetPort: 5601
nodePort: 30000创建 Kibana Service:
kubectl create -f kibana-svc.yaml现在你可以通过 http://<node-ip>:3000 访问 Kibana UI。
Pod 进入运行状态后,让我们尝试验证 Kibana 部署。最简单的方法是通过集群的 UI 访问。
要检查状态,端口转发 Kibana Pod 的 5601端口。如果您已经创建了 nodePort 服务,您也可以使用它(注意防火墙可能会拦截)。
kubectl port-forward <kibana-pod-name> 5601:5601之后,通过 web 浏览器访问 UI 或使用 curl 发出请求
curl http://localhost:5601/app/kibana如果 Kibana UI 加载或出现有效的 curl 响应,那么我们可以断定 Kibana 正在正确运行。
部署 Fluentd
Fluentd 被部署为守护进程,因为它必须从集群中的所有节点流日志。除此之外,它还需要特殊的权限来列出和提取所有名称空间中的 Pod 元数据。
Kubernetes 服务帐户用于为 Kubernetes 中的组件提供权限,以及集群角色和集群绑定。让我们继续前进,创建所需的服务帐户和角色。
创建 Fluentd 集群角色
Kubernetes 中的集群角色包含表示一组权限的规则,对于 Fluentd,我们希望为 Pod 和名称空间授予权限。
fluentd-role.yaml 文件的定义如下:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch创建角色:
kubectl create -f fluentd-role.yaml创建 Fluentd Service Account
在 Kubernetes 中,Service Account 是为 Pod 提供身份的实体,在这里,我们希望创建一个 Service Account,用于 Fluentd Pods。
fluentd-sa.yaml 文件的定义如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
labels:
app: fluentd创建 Service Account:
kubectl create -f fluentd-sa.yaml集群角色绑定
Kubernetes 中的集群角色绑定将集群角色中定义的权限授予服务帐户。我们希望在上面创建的角色和服务帐户之间创建一个角色绑定。
fluentd-rb.yaml 文件的定义如下:
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: default创建角色绑定:
kubectl create -f fluentd-rb.yaml部署 Fluentd DaemonSet
现在让我们部署 Fluentd :
kubectl create -f fluentd-ds.yaml为了验证 fluentd 的安装,让我们启动一个连续创建日志的 pod。然后我们将尝试在 Kibana 境内看到这些日志。
kubectl create -f test-pod.yaml现在,让我们前往 Kibana,看看这个吊舱里的日志是否被 fluentd 拾取并存储在 elasticsearch。遵循以下步骤:
1,点击 explore on my own 进入后台。

2,选择 Kibana 部分下的“ Index Patterns”选项。
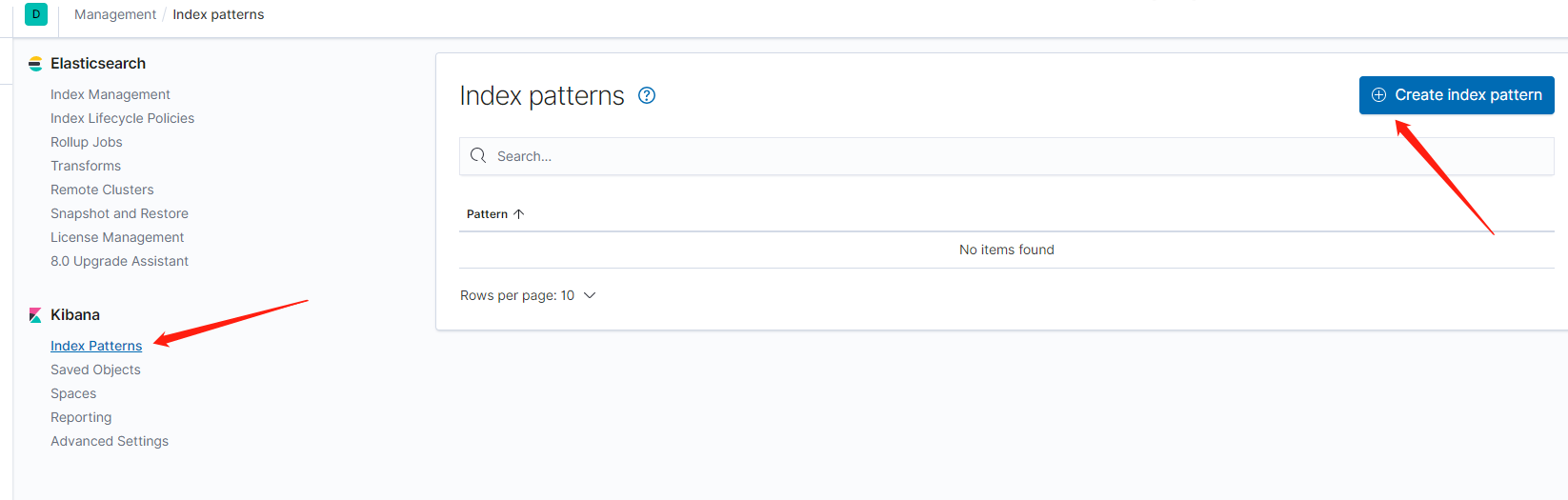
3,使用 logstash-* 模式创建一个新的 Index Patten,然后点击 Next step。
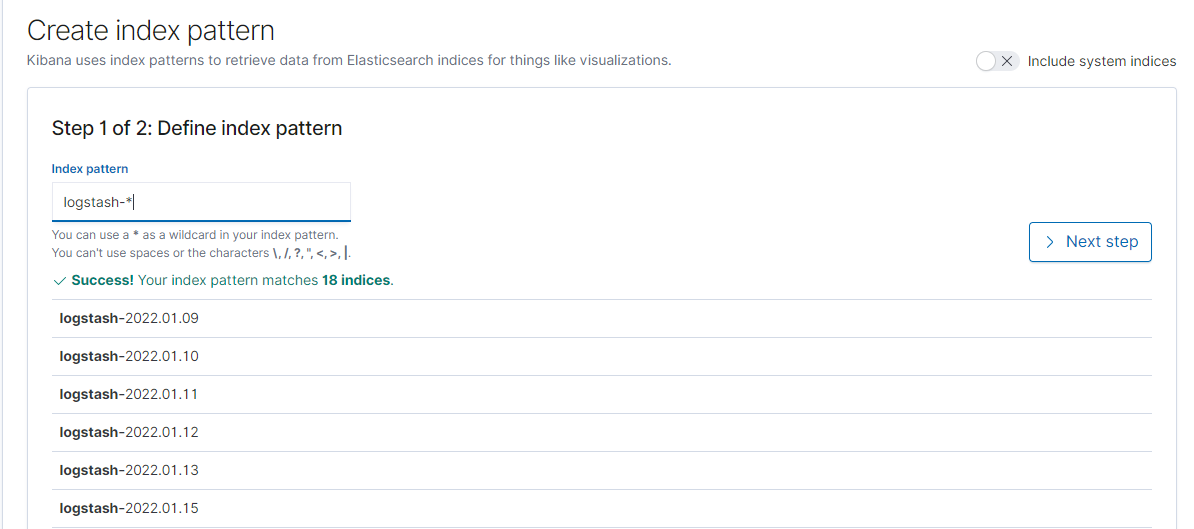
4,在选项找到 @timestamp ,然后点击 Create index pattern
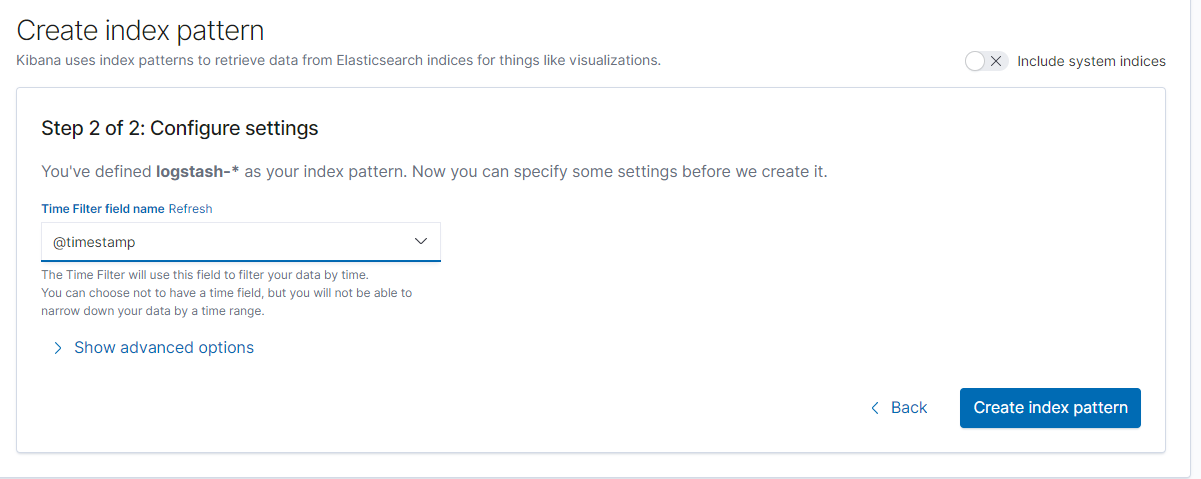
现在已经创建了索引模式,我们可以前往控制台,在控制台中,您将能够看到所有由 Fluentd 导出的日志,如下图所示,这些日志来自我们的 test-pod。
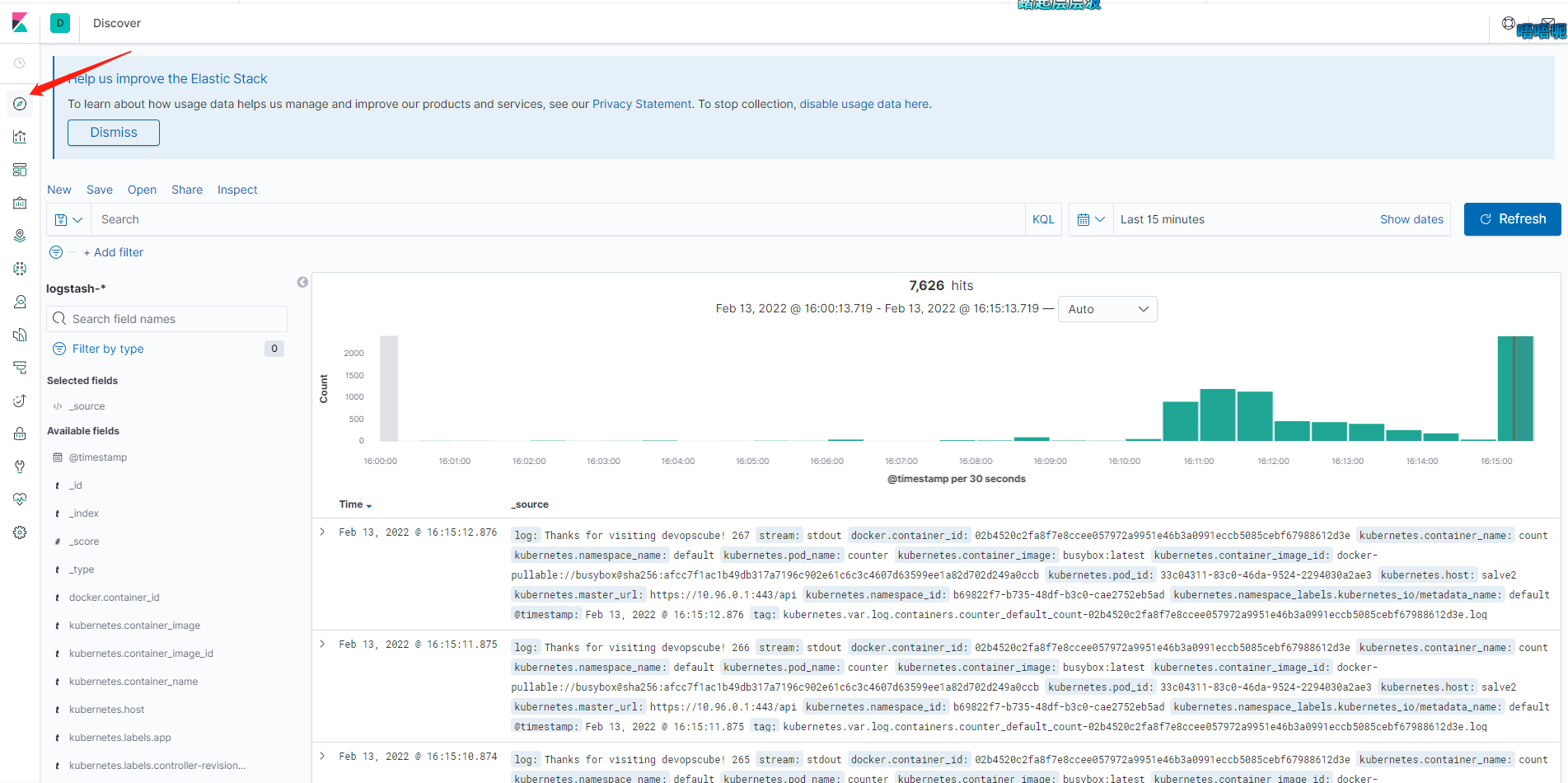
接下来,读者可以根据官方文档或其他资料,继续深入学习探究图表的制作和日志分析,以便在生产中应用 EFK 三件套。
如果想深入 Kibana 面板,笔者推荐你阅读这篇博客:https://devopscube.com/kibana-dashboard-tutorial/

文章评论