Kubernetes 监控
当你的应用部署到 Kubenetes 后,你很难看到容器内部发生了什么,一旦容器死掉,里面的数据可能就永远无法恢复,甚至无法查看日志以定位问题所在,何况一个应用可能存在很多个实例,用户的一个请求不指定被哪个容器处理了,这使得在 Kubernetes 中对应用进行故障排除较为复杂。在应用之外,由于 Kubernetes 作为基础设施,掌管这整个集群的生死,Kubernetes 的任何故障,必定影响到应用服务的运行,因此监控 Kubernetes 运行状况也至关重要。
当你的应用上了云原生,那你就不得不关注各个服务器的运行状态,基础设施和中间件的运行状态,Kubernetes 中每个组件和资源对象的运行状态,每个应用的运行状态。当然,这个运行状态是一个模糊的概念,取决于我们的关注点,每个被监控的对象要表达的 "运行状态" 是不一样的。为了可以监控我们关注的对象,对象需要做出一些配合,提供合适的运行状态的表达信息,以供我们收集和分析,这可以称为可观测性。
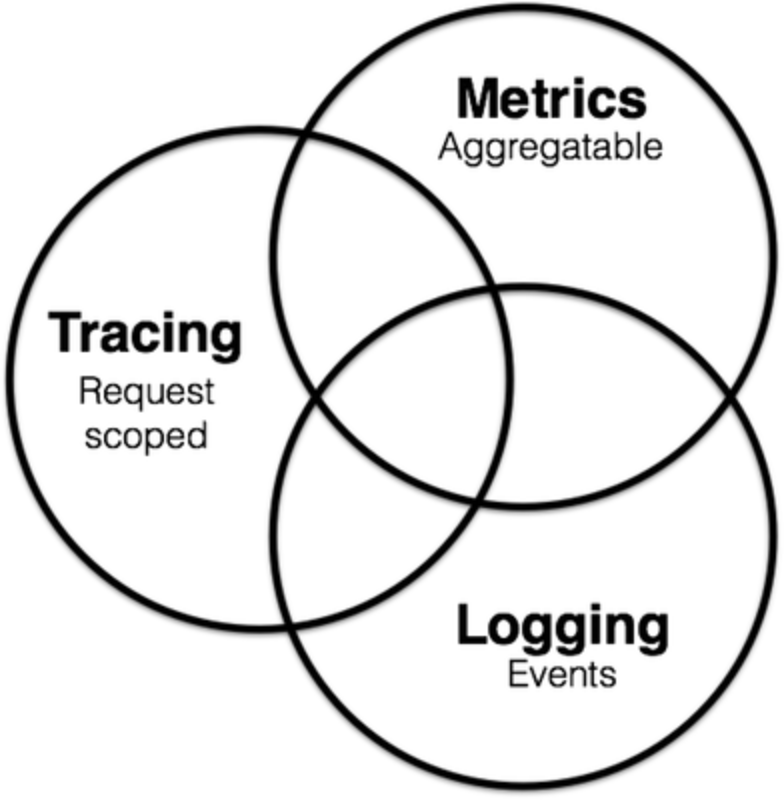
在云原生中,一般对可观测性分为三大作用域:
你可以在 Kubernetes 文档中了解如何监控、调试,以及了解如何对日志进行处理:
https://v1-20.docs.kubernetes.io/docs/tasks/debug-application-cluster/
在本文中,所提到的监控,只包括 Metrics 。
Metrics、Tracing、Logging 不是完全独立的,在上图中,Metrics 也会可能包含 Logging 和 Tracing 的信息。
监控对象
要采集的监控数据,来源于被监控对象,而在 Kubernetes 集群中,我们可以将要监控的对象分为三大部分:
- 机器:集群中的所有节点机器,指标有 CPU 内存使用率、网络和硬盘 IO 速率等;
- Kubernetes 对象状态:Deployments, Pods, Daemonsets, Statefulset 等对象的状态和某些指标信息;
- 应用:Pod 中每个容器的状态或指标,以及容器本身可能提供的
/metrics端点。
Prometheus
在基础环境中,一个完整的监控应包括采集数据、存储数据、分析存储数据、展示数据、告警等多个部分,而每个部分都有相关的工具或技术解决云原生中环境的多样需求和复杂性问题。
既然要做监控,那么就需要监控工具。监控工具可以获取所有重要的指标和日志(Metrics也可以包含一些日志),并将它们存储在一个安全、集中的位置,以便可以随时访问它们来制定方案解决问题。由于在云原生中,应用在 Kubernetes 集群中部署,因此,监控 Kubernetes 可以让你深入了解集群的运行状况和性能指标、资源计数以及集群内部情况的顶级概览。发生错误时,监控工具会提醒你(告警功能),以便你快速推出修复程序。
Prometheus 是一个 CNCF 项目,可以原生监控 Kubernetes、节点和 Prometheus 本身,目前 Kubernetes 官方文档主要推荐使用 Prometheus 本身,它为 Kubernetes 容器编排平台提供开箱即用的监控能力。因此在本文中,对监控方案的设计是围绕 Prometheus 展开的。
下面是 Prometheus 的一些组件介绍:
- Metric Collection: Prometheus 使用拉模型通过 HTTP 检索度量。在 Prometheus 无法获取指标的情况下,可以选择利用 Pushgateway 将指标推给 Prometheus 。
- Metric Endpoint: 希望使用 Prometheus 监视的系统应该公开某个/度量端点的度量, Prometheus 利用这个端点以固定的间隔提取指标。
- PromQL: Prometheus 附带了 PromQL,这是一种非常灵活的查询语言,可用于查询 Prometheus 仪表板中的指标。此外,Prometheus UI 和 Grafana 将使用 PromQL 查询来可视化指标。
- Prometheus Exporters: 有许多库和服务器可以帮助将第三方系统中的现有指标导出为 Prometheus 指标。这对于无法直接使用 Prometheus 指标检测给定系统的情况。
- TSDB (time-series database): Prometheus 使用 TSDB 高效地存储所有数据。默认情况下,所有数据都存储在本地。然而,为了避免单点故障,prometheustsdb 可以选择集成远程存储。
Prometheus 在 Kubernetes 中的监控方案结构如下:
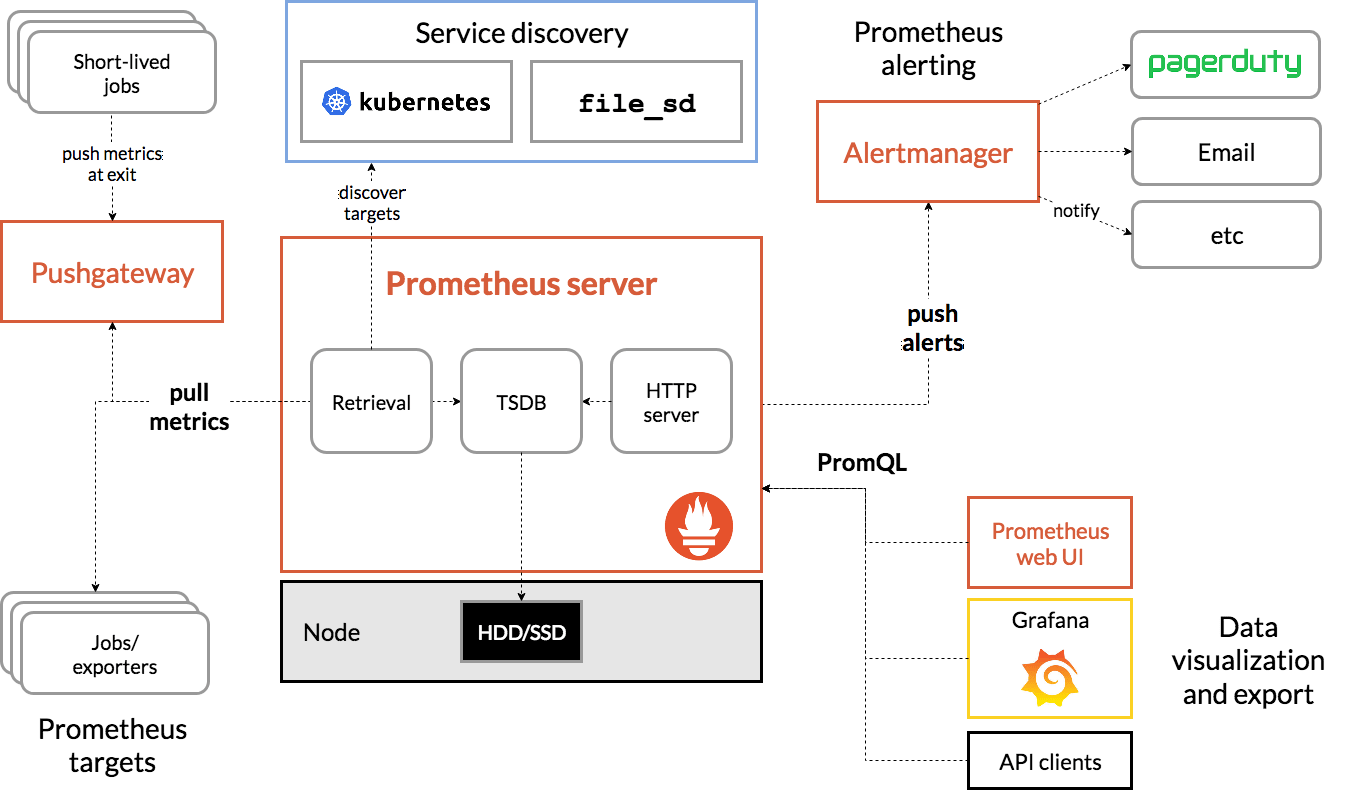
【图源:https://devopscube.com/setup-prometheus-monitoring-on-kubernetes/】
指标
要监控的对象种类很多,我们把相同类型的对象称为一个实体,而每个实体运行时的对象产生的数据有各种各样的,为了归纳收集这些数据, Prometheus 将实体中的各种属性值分为 Counter (计数器)、Gauge (仪表盘)、Histogram(累积直方图)、Summary(摘要)四种类型,实体中的每个属性,称为指标,例如 容器已累计使用 CPU 量,使用指标名称 container_cpu_usage_seconds_total 记录。
每个指标一般格式为:
指标名称{元数据=值} 指标值每个对象都在无时无刻产生数据,为了区分当前指标值属于哪个对象,可以给指标除了指标值外,附加大量的元数据信息,示例如下表示。
container_cpu_usage_seconds_total{
beta_kubernetes_io_arch = "amd64",
beta_kubernetes_io_os = "linux",
container = "POD",
cpu = "total",
id = "...",
image = "k8s.gcr.io/pause:3.5",
instance = "slave1",
job = "kubernetes-cadvisor",
kubernetes_io_arch = "amd64",
kubernetes_io_hostname = "slave1",
kubernetes_io_os = "linux",
name = "k8s_POD_pvcpod_default_02ed547b-6279-4346-8918-551b87877e91_0",
namespace = "default",
pod = "pvcpod"
}对象生成类似这种结构的文本后,可以暴露 metrics 端点,让 Prometheus 自动采集,或通过 Pushgateway 推送到 Prometheus 中。
接下来,我们将在 Kubernetes 中搭建一个完整的 Prometheus 监控体系。
实践
节点监控
本章参考资料:https://devopscube.com/node-exporter-kubernetes/
node exporter 是用 Golang 编写的,用于在 Linux 系统上,收集内核公开的所有硬件和操作系统级别的指标,包括 CPU 、信息、网卡流量、系统负载、socket 、机器配置等。
读者可参考中列举出的 https://github.com/prometheus/node_exporter 中列举出的所有默认开启或默认关闭的指标。
既然要监控集群中的每个节点,那么就要做到每个节点都运行这一个 node exporter 实例,并且在集群新增节点的时候自动调度一个 node exporter 到这个节点中运行,因此需要采用 node exporter 的部署需要 DaemontSet 模式。
查看集群中的所有节点:
root@master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready,SchedulingDisabled control-plane,master 98d v1.22.2
salve2 Ready <none> 3h50m v1.23.3
slave1 Ready <none> 98d v1.22.2Bibin Wilson 大佬已经封装好了用于 Kubernetes 的 node exporter 的 YAML 文件,我们直接下载即可:
git clone https://github.com/bibinwilson/kubernetes-node-exporter打开仓库中的 daemonset.yaml 文件,大概了解其中的信息。
在 YAML 文件中,可以看到 node exporter 会被部署到命名空间 monitoring 中运行,它有两个 label:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter为了 node exporter 能够被调度到 master 节点中运行,我们需要为 Pod 添加容忍度属性:
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
spec:
# 复制下面这部分到对应的位置
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
- key: "node.kubernetes.io/unschedulable"
operator: "Exists"
effect: "NoSchedule"为了部署 node exporter ,我们先创建命名空间:
kubectl create namespace monitoring执行命令部署 node exporter:
kubectl create -f daemonset.yaml查看 node exporter 实例
root@master:~# kubectl get daemonset -n monitoring NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE node-exporter 3 3 3 3 3 <none> 22h
由于 node exporter Pod 分散在各个节点,为了便于 Prometheus 收集这些 node exporter 的 Pod IP,需要创建 Endpoint 统一收集,这里通过创建 Service 自动生成 Endpoint 来达到目的。
查看仓库下的 service.yaml 文件,其定义如下:
kind: Service
apiVersion: v1
metadata:
name: node-exporter
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9100'
spec:
selector:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
ports:
- name: node-exporter
protocol: TCP
port: 9100
targetPort: 9100此 Service 的选择器如下:
selector: app.kubernetes.io/component: exporter app.kubernetes.io/name: node-exporter
创建 Service:
kubectl create -f service.yaml查看 Endpoint 收集的 node exporter 的 Pod IP:
root@master:~# kubectl get endpoints -n monitoring
NAME ENDPOINTS AGE
node-exporter 10.32.0.27:9100,10.36.0.4:9100,10.44.0.3:9100 22hnode exporter 除了收集各种指标数据外,不会再干什么。
部署 Prometheus
本节参考https://devopscube.com/setup-prometheus-monitoring-on-kubernetes/
现在有了 node exporter ,可以收集节点各类指标,接下来便是对 Kubernetes 基础设施的 metrics 数据收集。
Kubernetes 自身提供的很多 metrics 数据,有三大端点 /metrics/cadvisor, /metrics/resource and /metrics/probes 。
以 /metrics/cadvisor 为例,cAdvisor 分析在给定节点上运行的所有容器的内存、CPU、文件和网络使用情况的指标,你可以参考 https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md 了解 cAdvisor 的所有指标。
其它资料:
源码位置:https://github.com/kubernetes/metrics/blob/master/pkg/apis/metrics/v1beta1/types.go
Kubernetes 监控架构设计:https://github.com/kubernetes/design-proposals-archive
在本节中,部署的 Prometheus 将会对 kubenetes 进行以下动作以便收集 metrics 数据:
- Kubernetes-apiservers: 从 API 服务器获得所有的指标;
- Kubernetes 节点: 它收集所有的 kubernetes 节点指标;
kubernetes-pods: pod 元数据上加上 prometheus.io/scrape 和 prometheus.io/port 注释,所有的 pod 指标都会被发现;kubernetes-cadvisor: 收集所有 cAdvisor 指标,与容器相关;- Kubernetes-Service-endpoints: 如果服务元数据使用 prometheus.io/scrape 注释和 prometheus.io/port 注释,那么所有的服务端点都将被废弃;
Bibin Wilson 大佬已经封装好了相关的部署定义文件,我们直接下载即可:
git clone https://github.com/bibinwilson/kubernetes-prometheusPrometheus 通过使用 Kubernetes API Server ,获取 各节点、Pod、Deployment 等所有可用的指标。因此,我们需要创建具有对所需 API 组的只有读访问权限的 RBAC 策略,并将策略绑定到监视名称空间,以限制 Prometheus Pod 只能对 API 进行读操作。
查看 clusterRole.yaml 文件,可以其要监控的资源对象列表:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses在集群中创建角色和角色绑定:
kubectl create -f clusterRole.yaml可以通过 通过命令行标志和配置文件 对 Prometheus 进行配置。虽然命令行标志配置了不可变的系统参数(例如存储位置、要保存在磁盘和内存中的数据量等),但配置文件定义了与抓取作业及其实例相关的所有内容,以及加载哪些规则文件,因此部署 Permetheus 少不了做文件配置。
Permetheus 的配置文件以 YAML 格式编写,具体规则可以参考:https://prometheus.io/docs/prometheus/latest/configuration/configuration/
为了便于将配置文件映射到 Permetheus Pod 中,我们需要将配置放到 configmap ,然后挂载到 Pod,配置内容可以查看 config-map.yaml 。config-map.yaml 中定义了很多采集数据源的规则,例如收集 Kubernetes 集群和 node exporter ,配置可参考:
scrape_configs:
- job_name: 'node-exporter'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_endpoints_name]
regex: 'node-exporter'
action: keep你可以打开 https://raw.githubusercontent.com/bibinwilson/kubernetes-prometheus/master/config-map.yaml 在线预览这个文件。
创建 configmap:
kubectl create -f config-map.yaml这个配置很重要,需要根据实际情况配置,一般由运维处理,这里就不再讨论。
接下来将要部署 Prometeus ,由于示例文件中使用 emtpy 卷存储 Prometheus 数据,因此一旦 Pod 重启等,数据将会丢失,因此这里可以改成 hostpath 卷。
打开 prometheus-deployment.yaml 文件:
将
emptyDir: {}改成
hostPath:
path: /data/prometheus
type: Directory 可改可不改。
如果改的话,需要在被调度此 Pod 对应的节点上创建
/data/prometheus目录。
部署 Prometeus :
kubectl create -f prometheus-deployment.yaml 查看部署状态:
root@master:~# kubectl get deployments --namespace=monitoring NAME READY UP-TO-DATE AVAILABLE AGE prometheus-deployment 1/1 1 1 23h
为了在外界访问 Prometeus ,需要创建 Service:
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9090'
spec:
selector:
app: prometheus-server
type: NodePort
ports:
- port: 8080
targetPort: 9090
nodePort: 30000kubectl create -f prometheus-service.yaml接下来可以访问 Prometeus UI 面板。
点击 Graph,点击🌏图标,选择需要显示的指标值,再点击 Execute 查询显示。
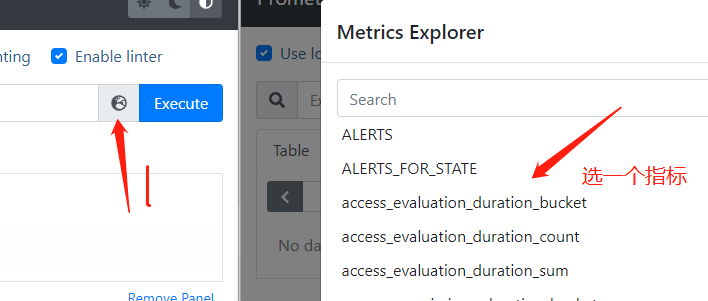
你还可以在 Service Discobery 中,查看 Prometheus 采集的 metrics 数据源。
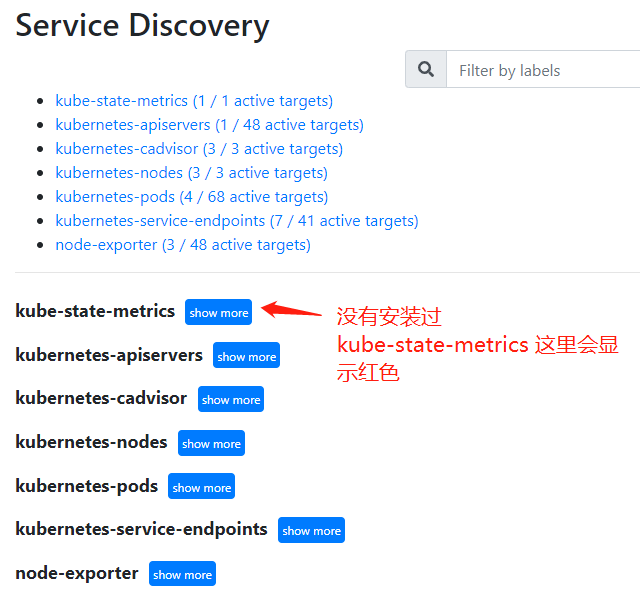
如果你的集群没有安装过 kube-state-metrics,那么这个数据源会显示红色标记,在下一节中,我们继续部署这个组件。
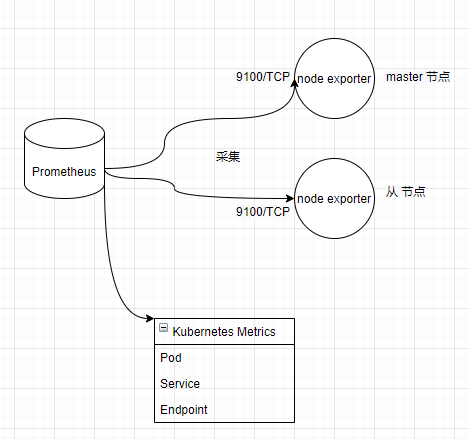
至此,我们的监控结构如下所示:
部署 Kube State Metrics
本节参考资料:https://devopscube.com/setup-kube-state-metrics/
Kube State metrics 是一个服务,它与 Kubernetes API Server 通信,以获取所有 API 对象的详细信息,如 Deployment、Pod 等。
Kube State metrics 提供了无法直接从本地 Kubernetes 监视组件获得的 Kubernetes 对象和资源 度量,因为 Kubenetes Metrics 本身提供的指标并不是很全面,因此需要 Kube State Metrics 以获得与 kubernetes 对象相关的所有度量。
以下是可以从 Kube State metrics 中获得的一些重要度量:
- Node status, node capacity (CPU and memory)
- Replica-set compliance (desired/available/unavailable/updated status of replicas per deployment)
- Pod status (waiting, running, ready, etc)
- Ingress metrics
- PV, PVC metrics
- Daemonset & Statefulset metrics.
- Resource requests and limits.
- Job & Cronjob metrics
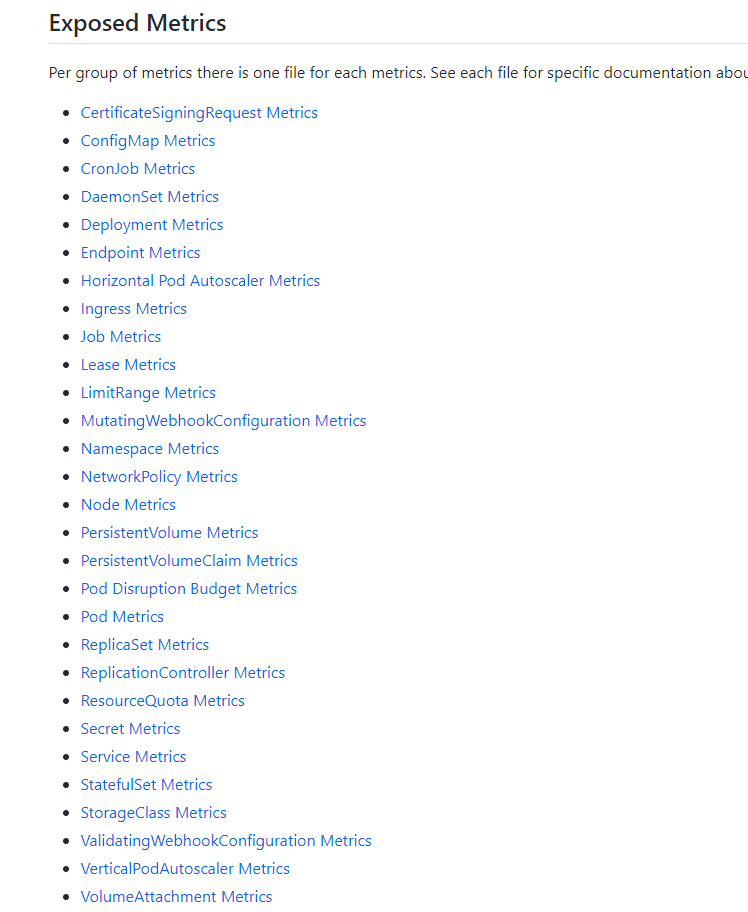
可以在这里的文档中查看受支持的详细指标:https://github.com/kubernetes/kube-state-metrics/tree/master/docs
Bibin Wilson 大佬已经封装好了相关的部署定义文件,我们直接下载即可:
git clone https://github.com/devopscube/kube-state-metrics-configs.git直接应用所有 YAML 创建对应的资源:
kubectl apply -f kube-state-metrics-configs/├── cluster-role-binding.yaml ├── cluster-role.yaml ├── deployment.yaml ├── service-account.yaml └── service.yaml
上面创建的资源,包含以下部分,这一小节,就不展开讲解。
- Service Account
- Cluster Role
- Cluster Role Binding
- Kube State Metrics Deployment
- Service
使用以下命令检查部署状态:
kubectl get deployments kube-state-metrics -n kube-system随后,刷新 Prometheus Service Discobery ,可以看到红色变成了蓝色,点击此数据源,可以看到以下信息:

- job_name: 'kube-state-metrics'
static_configs:
- targets: ['kube-state-metrics.kube-system.svc.cluster.local:8080']此配置为 kube-state-metrics 的访问地址。
在此,我们部署的 Prometeus 结构如下:
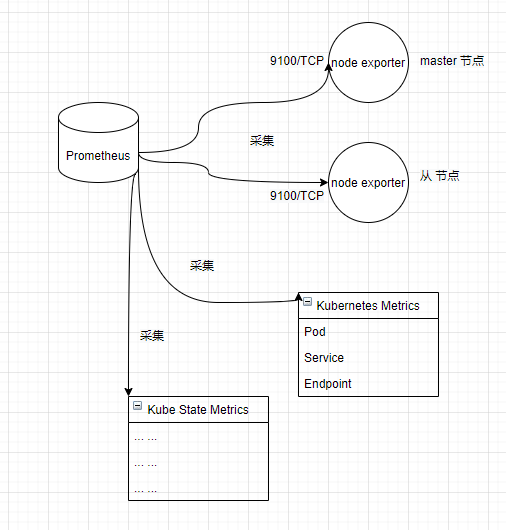
部署 Grafana
本节参考资料:https://devopscube.com/setup-grafana-kubernetes/
经过前面几个小节的部署,已经搞好数据源的采集以及数据存储,接下来我们将部署 Grafana,利用 Grafana 对指标数据进行分析以及可视化。
Bibin Wilson 大佬已经封装好了相关的部署定义文件,我们直接下载即可:
git clone https://github.com/bibinwilson/kubernetes-grafana.git首先查看 grafana-datasource-config.yaml 文件,此配置是为了 Grafana 自动配置好 Prometheus 数据源。
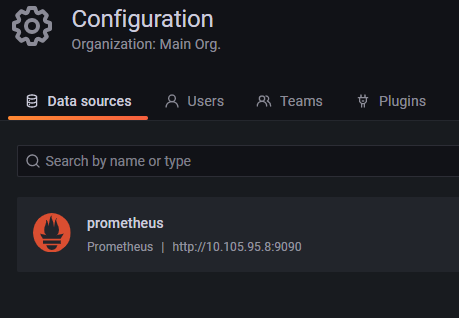
里面还有一个很重要的地址:
"url": "http://prometheus-service.monitoring.svc:8080",这里要确认你的 CoreDNS 是否正常,你可以参考 https://kubernetes.io/zh/docs/tasks/administer-cluster/dns-debugging-resolution/ 中列举的 DNS 调试方法,确认你的集群中是否可以通过 DNS 访问 Pod。
最简单的方法是启动一个 Pod,然后使用命令测试 curl http://prometheus-service.monitoring.svc:8080,看看能不能获取到响应数据,如果出现:
root@master:~/jk/kubernetes-prometheus# curl http://prometheus-deployment.monitoring.svc:8080
curl: (6) Could not resolve host: prometheus-deployment.monitoring.svc
root@master:~/jk/kubernetes-prometheus# curl http://prometheus-deployment.monitoring.svc.cluster.local:8080
curl: (6) Could not resolve host: prometheus-deployment.monitoring.svc.cluster.local可能是你 coredns 没有安装或者别的原因,导致无法通过此地址访问 Prometheus ,为了为了避免过多操作,可以改为使用 IP,而不是域名。
查看 Prometheus 的 Service IP:
root@master:~/jk/kubernetes-prometheus# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-deployment NodePort 10.105.95.8 <none> 9090:32330/TCP 23h测试通过 Service IP 访问是否正常
root@master:~/jk/kubernetes-prometheus# curl 10.105.95.8:9090
<a href="/graph">Found</a>.将 grafana-datasource-config.yaml 中的 prometheus-deployment.monitoring.svc.cluster.local:8080 改成对应的 Service IP,并且端口改成 9090。
创建配置
kubectl create -f grafana-datasource-config.yaml打开 deployment.yaml 查看定义,模板中 grafana 的数据存储也是使用 empty 卷,有数据丢失风险,因此可以改成用 hospath 或其他类型的卷存储。可参考笔者的配置:
volumes:
- name: grafana-storage
hostPath:
path: /data/grafana
type: Directory 部署 Grafana:
kubectl create -f deployment.yaml然后创建 Service:
kubectl create -f service.yaml接着可以通过 32000 端口访问 Grafana。
账号密码都是 admin
至此,我们部署的 Prometheus 监控结构如下:
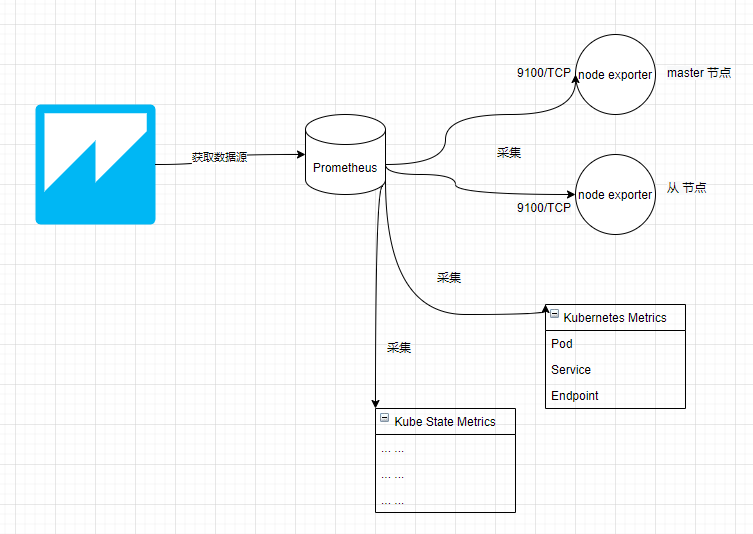
刚刚进去的时候空空如也,我们需要利用图表模板制作可视化界面,才能显示出漂亮的数据。
在 Grafana 官方网站中,有很多社区制作的免费的模板 https://grafana.com/grafana/dashboards/?search=kubernetes
首先打开 https://grafana.com/grafana/dashboards/8588 下载这个模板,然后上传模板文件,并绑定对应的 Prometheus 数据源。
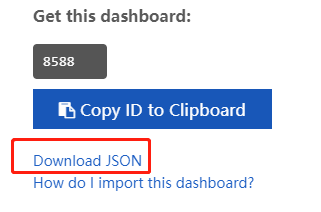
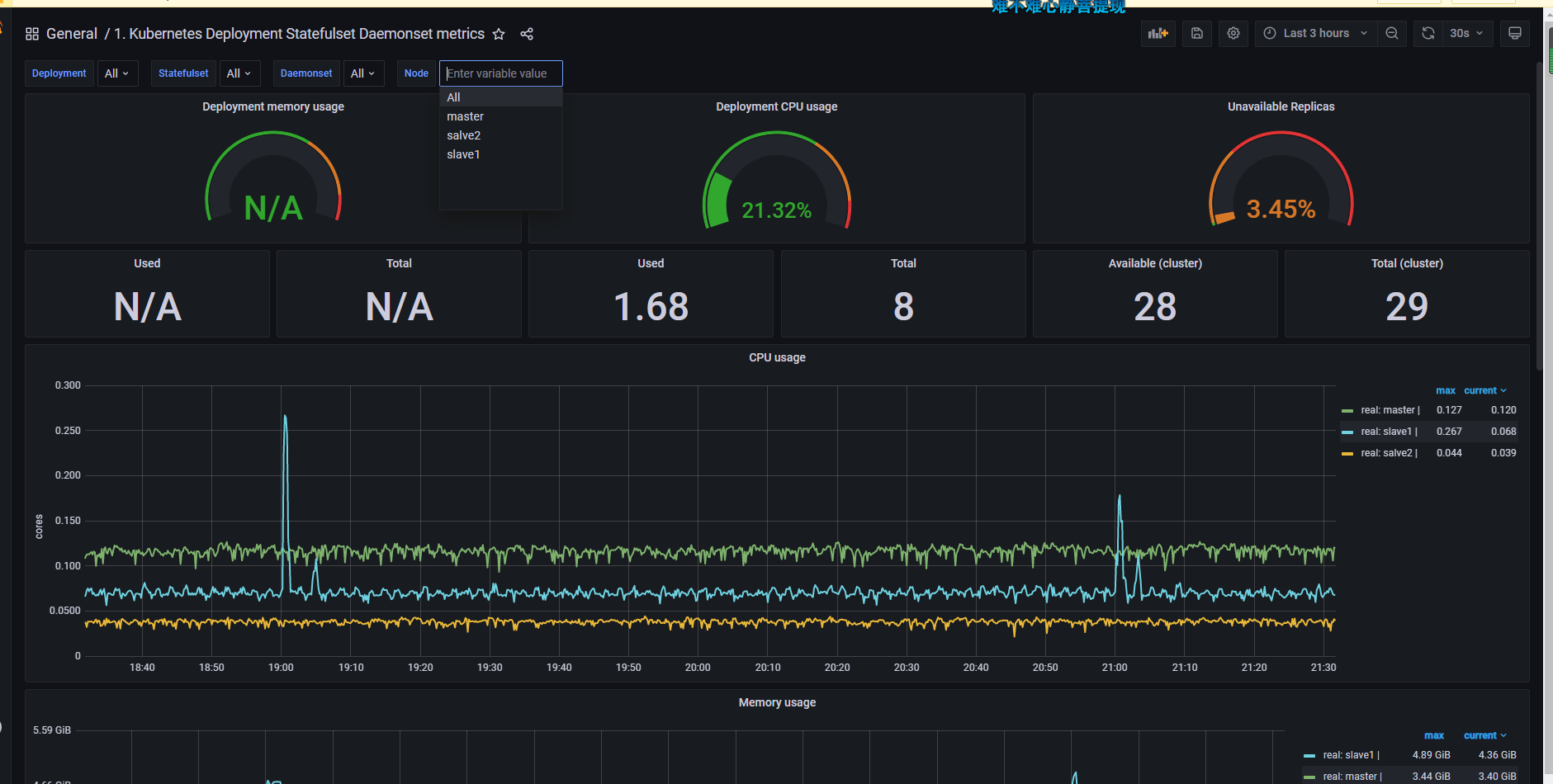
接下来就可以看到对应的监控界面了。
你可以打开 Browse ,继续导入更多的模板,然后查看要显示的模板监控界面。
应用如何接入 Prometheus 和 Grafana
前面已经提及对基础设施的监控,我们还可以对中间件如 TIDB、Mysql 等生成、收集指标数据,还可以在程序中自定义指标数据,然后自行制作 Grafana 模板。如果你是 .NET 开发,还可以参考笔者的另一篇文章来一步步了解这些过程:https://www.cnblogs.com/whuanle/p/14969982.html
告警
在监控体系中,告警是重中之重,一般需要根据公司的实际情况自研告警处理和推送通知组件。
我们建议您阅读 基于 Rob Ewaschuk 在 Google 的观察的我的警报哲学https://docs.google.com/a/boxever.com/document/d/199PqyG3UsyXlwieHaqbGiWVa8eMWi8zzAn0YfcApr8Q/edit
在前面部署 Prometheus 时,config-map.yaml 便已经定义了一个告警规则。
prometheus.rules: |-
groups:
- name: devopscube demo alert
rules:
- alert: High Pod Memory
expr: sum(container_memory_usage_bytes) > 1
for: 1m
labels:
severity: slack
annotations:
summary: High Memory Usage一条告警规则主要由以下几部分组成:
- alert:告警规则的名称。
- expr:基于 PromQL 表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为 pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations 的内容在告警产生时会一同作为参数发送到 Alertmanager。
可参考:https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/alert/prometheus-alert-rule
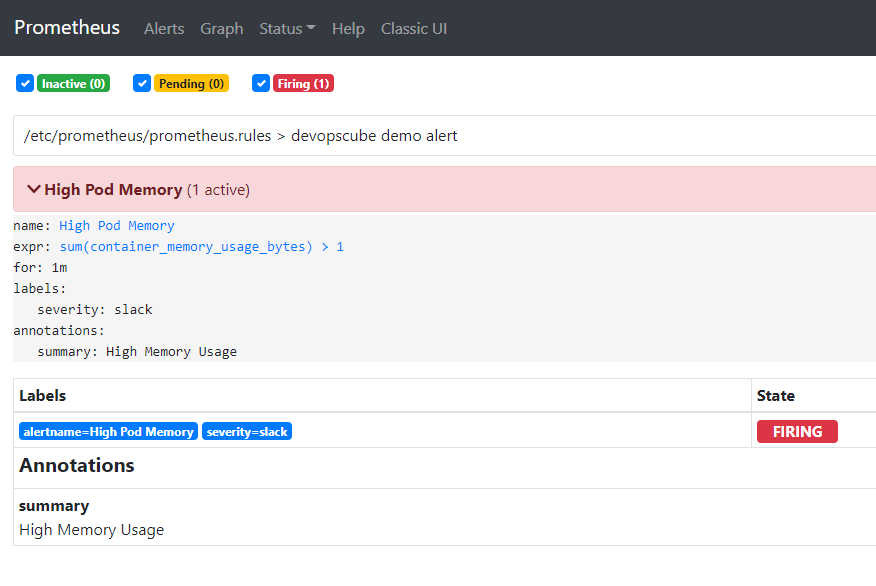
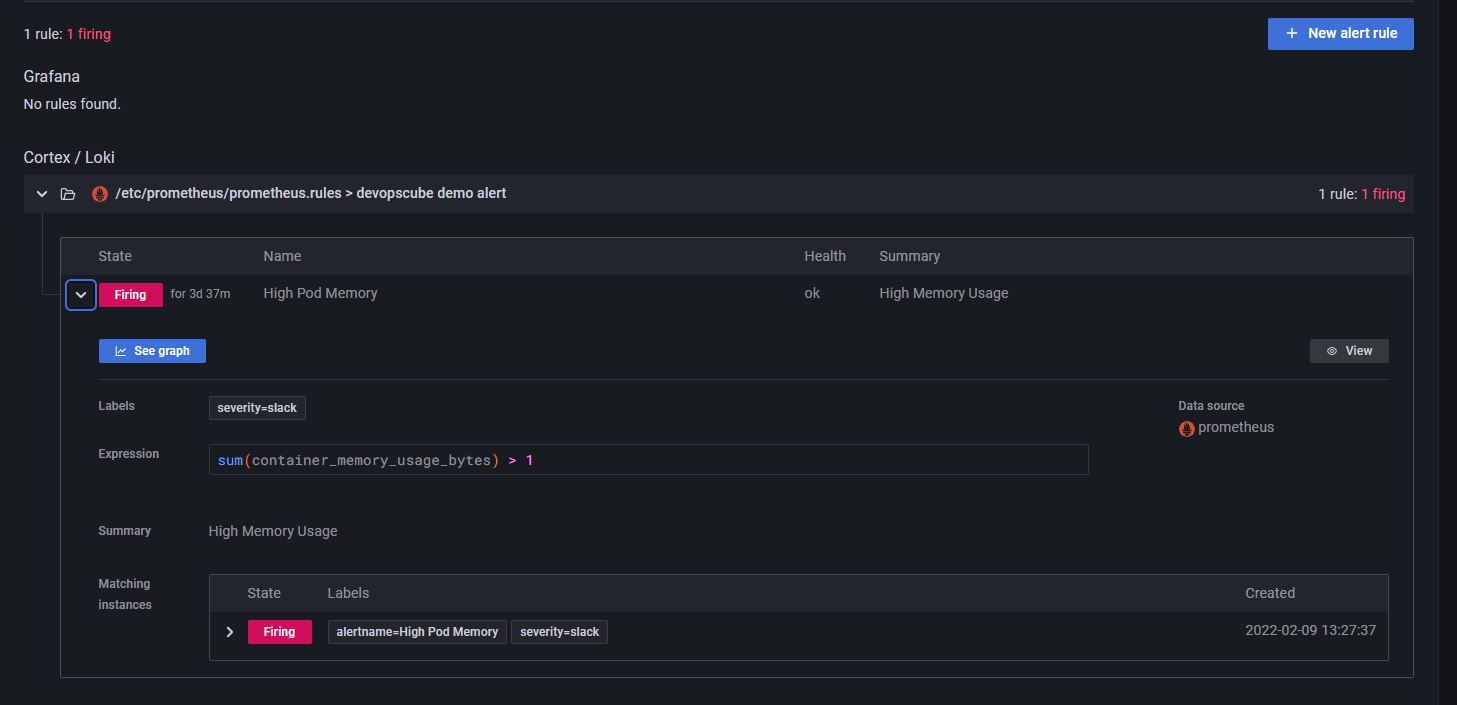
在 Grafana 中也可以看到这条规则。
下面我们将来配置告警通知。
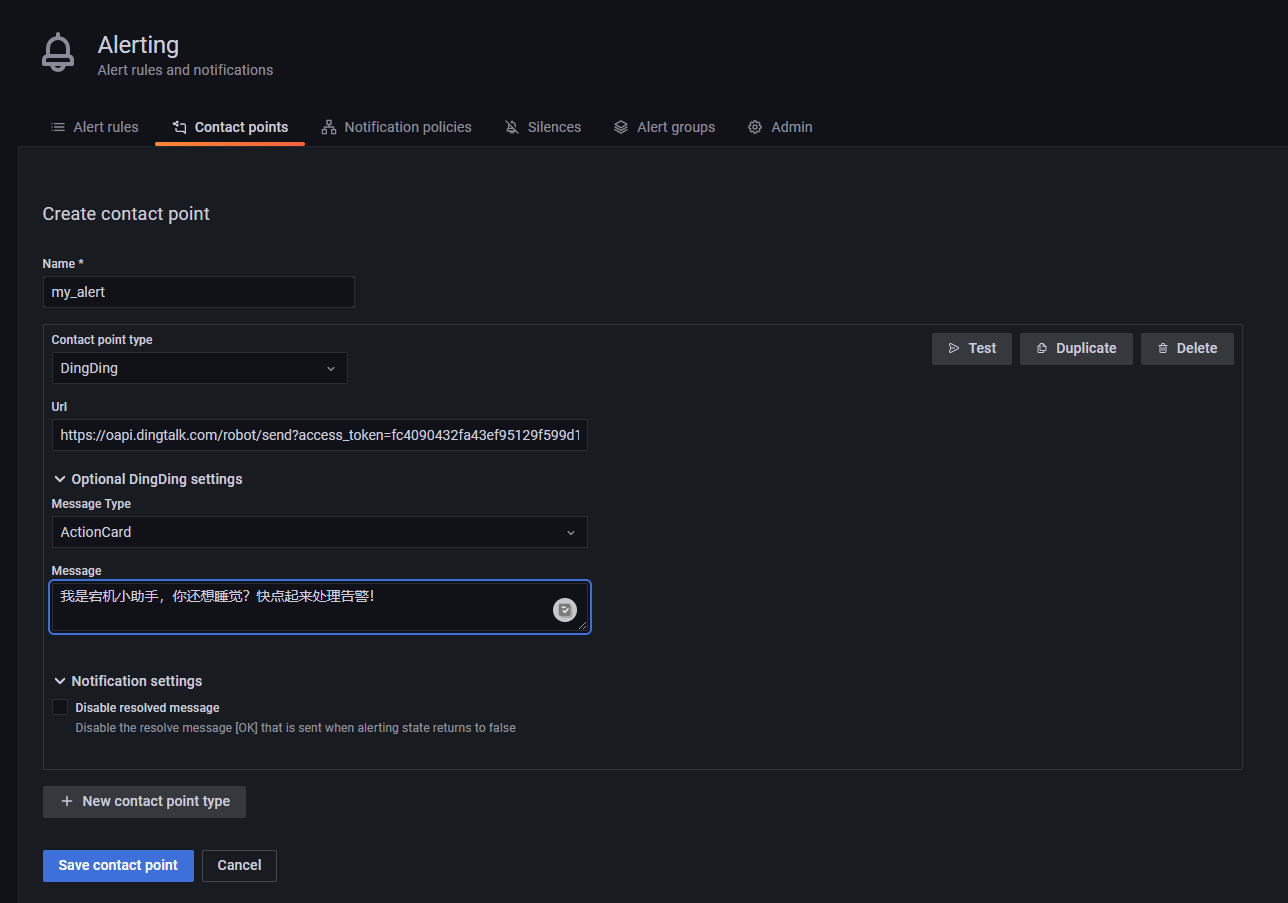
首先创建一个告警联系方式,笔者使用了钉钉 Webhook。
然后找 Alert Rules,添加一个新的告警规则。
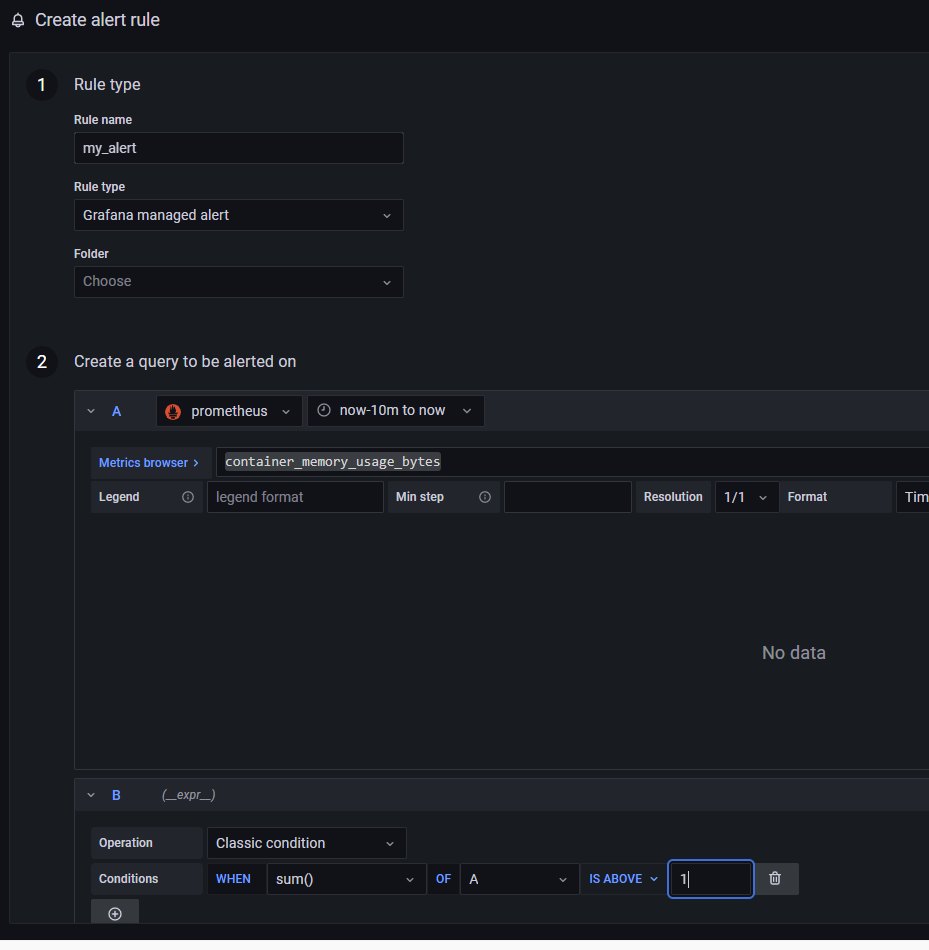
接着打开 Notification policies,为告警规则和联系方式做绑定,符合条件的告警信息将会被推送到指定的联系方式中。
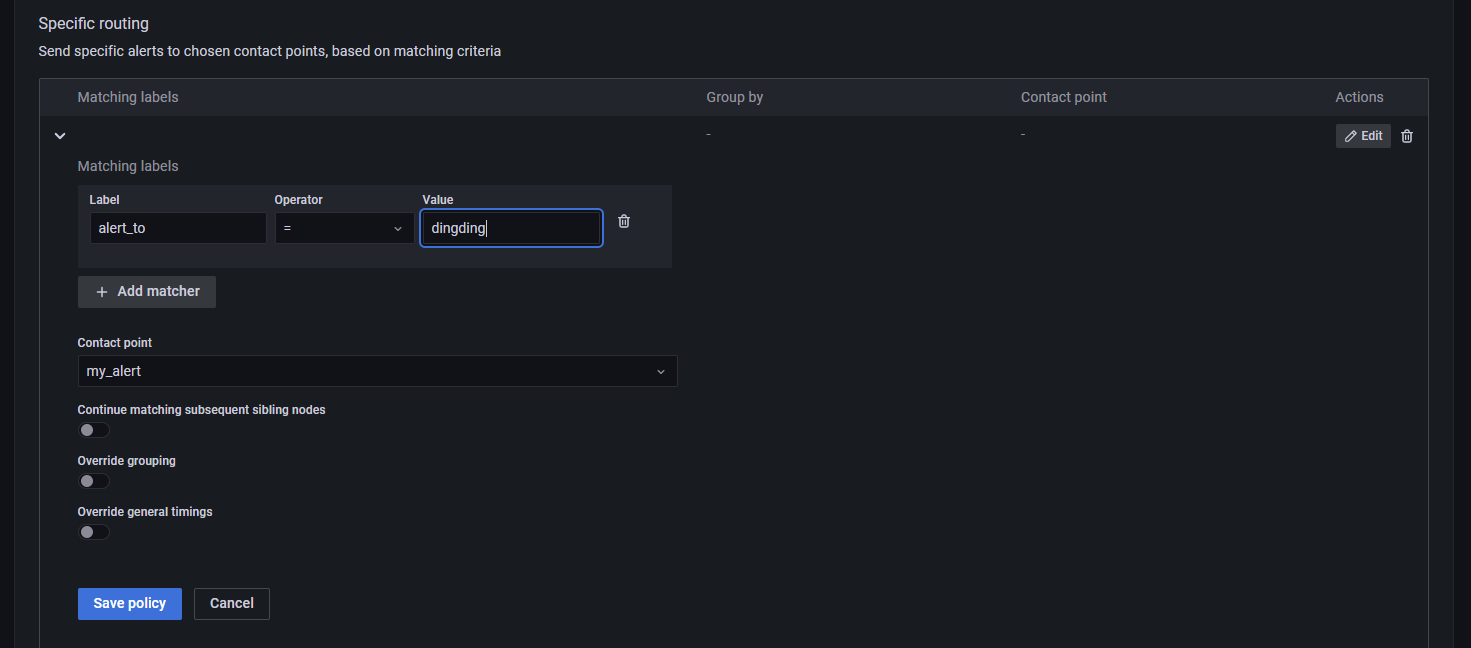
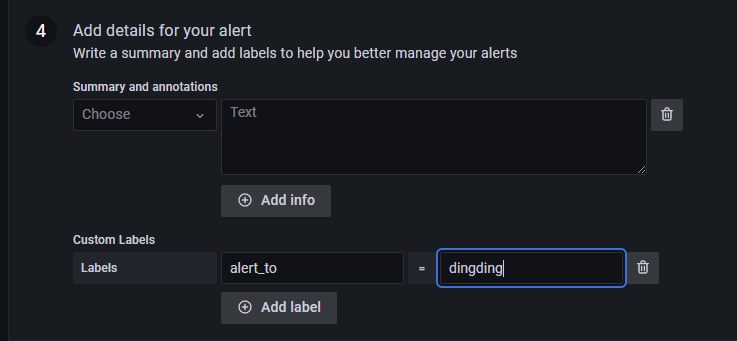
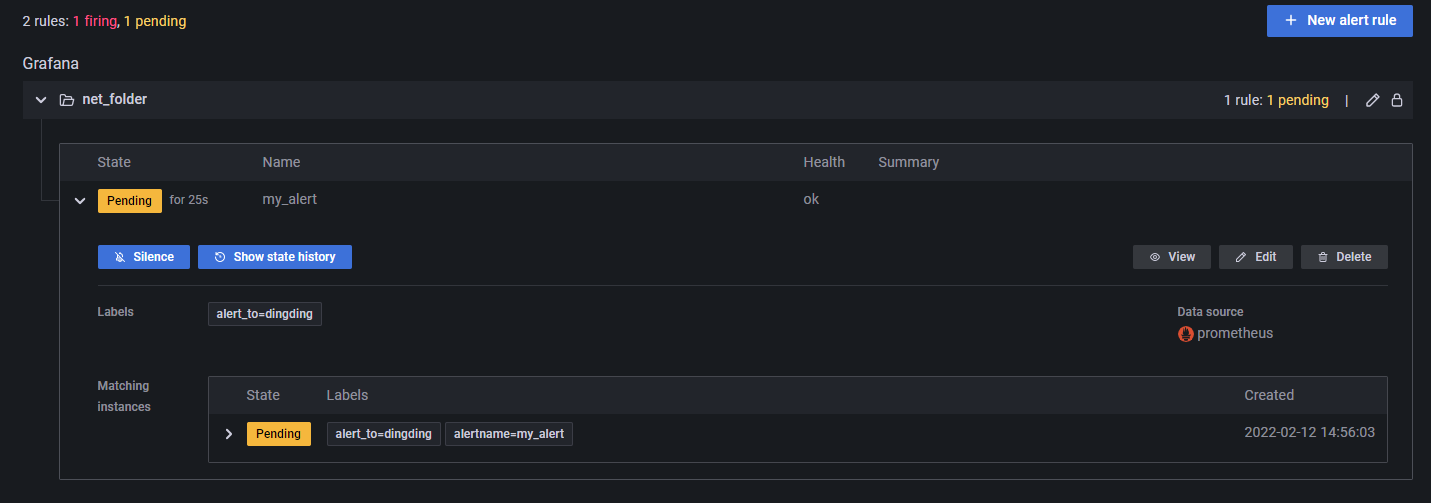
在 Alert Rules 中可以看到告警信息的推送记录。由于笔者的服务器在国外,可能导致服务器无法使用钉钉的 Webhook 功能,因此这里一直在 Pending,因此笔者这里就不再做过多的尝试了,读者了解大概步骤即可。

文章评论